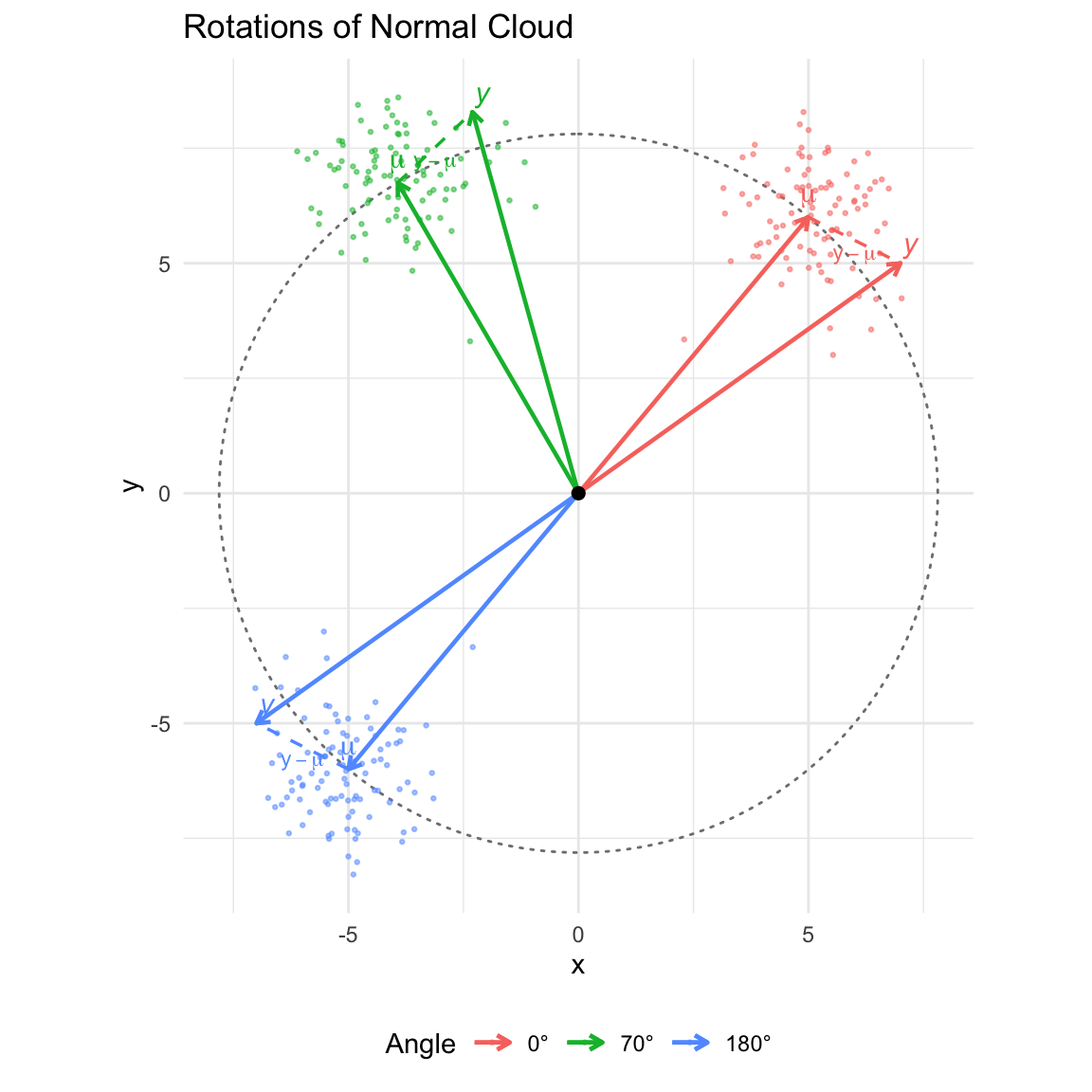
library(ggplot2)
library(MASS)
library(dplyr)
# --- 1. Setup Data & Parameters ---
set.seed(42)
n <- 100
sigma_val <- 1
Sigma <- diag(2) * sigma_val^2
mu_orig <- c(5, 6) # Original Mean
y_orig <- c(7, 5) # Updated Point y
# Generate 100 Points from N(mu, I)
data_orig <- mvrnorm(n, mu_orig, Sigma)
# Define Rotation Angles
angles <- c(0, 70, 180)
# --- 2. Process Data for Each Angle ---
points_list <- list()
vectors_list <- list()
for (deg in angles) {
theta <- deg * pi / 180
rot_mat <- matrix(c(cos(theta), -sin(theta),
sin(theta), cos(theta)), nrow = 2, byrow = TRUE)
# A. Rotate Points
data_rot <- data_orig %*% t(rot_mat)
df_pts <- data.frame(x = data_rot[,1], y = data_rot[,2])
df_pts$Angle <- factor(paste0(deg, "°"), levels = paste0(angles, "°"))
points_list[[length(points_list) + 1]] <- df_pts
# B. Rotate Vectors (mu and y)
mu_rot <- as.vector(rot_mat %*% mu_orig)
y_rot <- as.vector(rot_mat %*% y_orig)
df_vec <- data.frame(
Angle = factor(paste0(deg, "°"), levels = paste0(angles, "°")),
mu_x = mu_rot[1], mu_y = mu_rot[2],
y_x = y_rot[1], y_y = y_rot[2]
)
vectors_list[[length(vectors_list) + 1]] <- df_vec
}
all_points <- do.call(rbind, points_list)
all_vectors <- do.call(rbind, vectors_list)
# --- 3. Create Circle Data ---
# Radius Is the Length of Mu
radius_mu <- sqrt(sum(mu_orig^2))
circle_data <- data.frame(
x0 = 0, y0 = 0, r = radius_mu
)
# --- 4. Generate the Plot ---
ggplot() +
# 1. Circle through the mu's (Centered at 0,0)
ggforce::geom_circle(aes(x0 = 0, y0 = 0, r = radius_mu),
color = "gray50", linetype = "dotted", size = 0.5) +
# 2. Points (Data Cloud)
geom_point(data = all_points, aes(x = x, y = y, color = Angle),
size = 0.5, alpha = 0.5) +
# 3. Vector mu (Origin -> mu)
geom_segment(data = all_vectors,
aes(x = 0, y = 0, xend = mu_x, yend = mu_y, color = Angle),
arrow = arrow(length = unit(0.2, "cm")), size = 0.8) +
# 4. Vector y (Origin -> y)
geom_segment(data = all_vectors,
aes(x = 0, y = 0, xend = y_x, yend = y_y, color = Angle),
arrow = arrow(length = unit(0.2, "cm")), size = 0.8) +
# 5. Vector y - mu (mu -> y)
geom_segment(data = all_vectors,
aes(x = mu_x, y = mu_y, xend = y_x, yend = y_y, color = Angle),
arrow = arrow(length = unit(0.15, "cm")),
linetype = "dashed", size = 0.6) +
# 6. Labels for mu, y, and y-mu
geom_text(data = all_vectors, aes(x = mu_x, y = mu_y, label = expression(mu), color = Angle),
parse = TRUE, vjust = -0.5, size = 4, show.legend = FALSE) +
geom_text(data = all_vectors, aes(x = y_x, y = y_y, label = "y", color = Angle),
vjust = -0.5, hjust = -0.2, size = 4, fontface = "italic", show.legend = FALSE) +
# Label for y - mu (placed at midpoint)
geom_text(data = all_vectors, aes(x = (mu_x + y_x)/2, y = (mu_y + y_y)/2,
label = expression(y - mu), color = Angle),
parse = TRUE, size = 3, vjust = 1.5, show.legend = FALSE) +
# 7. Origin Marker
geom_point(aes(x=0, y=0), color="black", size=2) +
# Formatting
coord_fixed() +
theme_minimal() +
labs(title = "Rotations of Normal Cloud",
x = "x", y = "y") +
theme(legend.position = "bottom")