9 Bayesian Inference
9.1 Posterior Distributions
The foundation of Bayesian inference relies on the relationship between the prior distribution, the likelihood of the data, and the posterior distribution. This relationship is governed by Bayes’ Theorem (or Law).
Definition 9.1 (Posterior Distribution) Suppose we have a parameter \(\theta\) with a prior distribution denoted by \(\pi(\theta)\). If we observe data \(x\) drawn from a distribution with probability density function (pdf) \(f(x; \theta)\), then the posterior density of \(\theta\) given the data \(x\) is defined as:
\[ \pi(\theta|x) = \frac{\pi(\theta) f(x;\theta)}{m(x)} \]
where \(m(x)\) is the marginal distribution (or marginal likelihood) of the data, calculated as: \[ m(x) = \int_{\Theta} \pi(\theta) f(x;\theta) d\theta \]
In this context, \(m(x)\) acts as a normalizing constant. Since it depends only on the data \(x\) and not on the parameter \(\theta\), it ensures that the posterior density integrates to 1 but does not influence the shape of the posterior distribution.
Thus, we often state the proportional relationship:
\[ \pi(\theta|x) \propto \pi(\theta) f(x;\theta) \]
9.1.1 Discrete Posterior Calculation
Example 9.1 (Discrete Posterior Calculation) Consider the following table where we calculate the posterior probabilities for a discrete parameter space.
Let the parameter \(\theta\) take values \(\{1, 2, 3\}\) with prior probabilities \(\pi(\theta)\). Let the data \(x\) take values \(\{0, 1, 2, \dots\}\).
Given:
- Prior \(\pi(\theta)\): \(\pi(1)=1/3, \pi(2)=1/3, \pi(3)=1/3\).
- Likelihood \(\pi(x|\theta)\):
- If \(\theta=1\), \(x \sim \text{Uniform on } \{0, 1\}\) (Prob = 1/2).
- If \(\theta=2\), \(x \sim \text{Uniform on } \{0, 1, 2\}\) (Prob = 1/3).
- If \(\theta=3\), \(x \sim \text{Uniform on } \{0, 1, 2, 3\}\) (Prob = 1/4).
Suppose we observe \(x=2\). The calculation of the posterior probabilities is summarized in the table below:
| \(\theta=1\) | \(\theta=2\) | \(\theta=3\) | Sum | |
|---|---|---|---|---|
| Prior \(\pi(\theta)\) | \(1/3\) | \(1/3\) | \(1/3\) | \(1\) |
| Likelihood \(\pi(x=2|\theta)\) | \(0\) | \(1/3\) | \(1/4\) | - |
| Product \(\pi(\theta)\pi(x|\theta)\) | \(0\) | \(1/9\) | \(1/12\) | \(7/36\) |
| Posterior \(\pi(\theta|x)\) | \(0\) | \(4/7\) | \(3/7\) | \(1\) |
The marginal sum (evidence) is calculated as \(0 + 1/9 + 1/12 = 4/36 + 3/36 = 7/36\). The posterior values are obtained by dividing the product row by this sum.
9.1.2 Binomial-beta Conjugacy
Example 9.2 (Binomial-beta Conjugacy) Consider an experiment where \(x|\theta \sim \text{Bin}(n, \theta)\). The likelihood function is:
\[ f(x|\theta) = \binom{n}{x} \theta^x (1-\theta)^{n-x} \]
Suppose we choose a Beta distribution as the prior for \(\theta\), such that \(\theta \sim \text{Beta}(a, b)\). The prior density is:
\[ \pi(\theta) = \frac{\theta^{a-1}(1-\theta)^{b-1}}{B(a,b)} \]
where \(B(a,b)\) is the Beta function defined as \(\int_{0}^{1} \theta^{a-1}(1-\theta)^{b-1} d\theta\).
To find the posterior, we multiply the prior and the likelihood:
\[ \pi(\theta|x) \propto \theta^{a-1}(1-\theta)^{b-1} \cdot \theta^x (1-\theta)^{n-x} \]
Combining terms with the same base:
\[ \pi(\theta|x) \propto \theta^{a+x-1} (1-\theta)^{b+n-x-1} \]
We can recognize this kernel as a Beta distribution. Therefore, we conclude that the posterior distribution is:
\[ \theta|x \sim \text{Beta}(a+x, b+n-x) \]
Properties of the Posterior:
The posterior mean is: \[E^{\theta|X}[\theta] = \frac{a+X}{a+b+n}\] As \(n \to \infty\), this approximates the maximum likelihood estimate \(\frac{X}{n}\).
The posterior variance is: \[\text{Var}^{\theta|X}(\theta) = \frac{(a+X)(n+b-X)}{(a+b+n)^2(a+b+n+1)}\] For large \(n\), this approximates \(\frac{X(n-X)}{n^3} = \frac{\hat{p}(1-\hat{p})}{n}\).
Numerical Illustration:
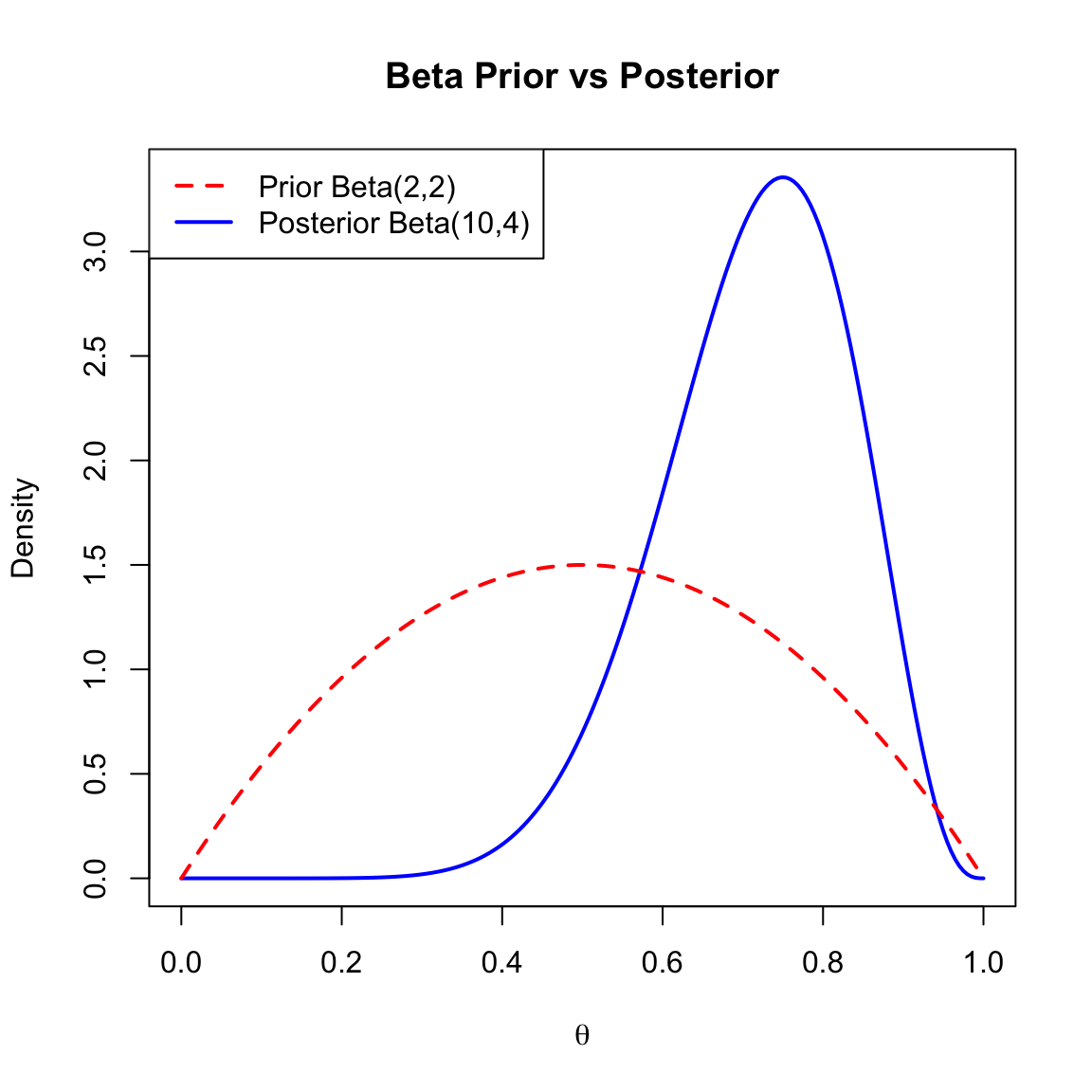
Suppose we are estimating a probability \(\theta\).
- Prior: \(\theta \sim \text{Beta}(2, 2)\) (Mean = 0.5).
- Data: 10 trials, 8 successes (\(n=10, x=8\)).
- Posterior: \(\theta|x \sim \text{Beta}(2+8, 2+2) = \text{Beta}(10, 4)\) (Mean \(\approx\) 0.71).
The plot below shows the prior (dashed) and posterior (solid) densities.
9.1.3 Normal-normal Conjugacy (known Variance)
Example 9.3 (Normal-normal Conjugacy (known Variance)) Let \(X_1, X_2, \dots, X_n\) be independent and identically distributed (i.i.d.) variables such that \(X_i \sim N(\mu, \sigma^2)\), where \(\sigma^2\) is known.
We assign a Normal prior to the mean \(\mu\): \(\mu \sim N(\mu_0, \sigma_0^2)\).
To find the posterior \(\pi(\mu|x_1, \dots, x_n)\), let \(x = (x_1, \dots, x_n)\). The posterior is proportional to:
\[ \pi(\mu|x) \propto \pi(\mu) \cdot f(x|\mu) \]
\[ \propto \exp\left\{-\frac{(\mu-\mu_0)^2}{2\sigma_0^2}\right\} \cdot \exp\left\{-\sum_{i=1}^n \frac{(x_i-\mu)^2}{2\sigma^2}\right\} \]
Posterior Precision:
It is often more convenient to work with precision (the inverse of variance). Let:
- \(\tau_0 = 1/\sigma_0^2\) (Prior precision)
- \(\tau = 1/\sigma^2\) (Data precision)
- \(\tau_1 = 1/\sigma_1^2\) (Posterior precision)
The relationship is additive:
\[ \tau_1 = \tau_0 + n\tau \]
\[ \text{Posterior Precision} = \text{Prior Precision} + \text{Precision of Data} \]
The posterior mean \(\mu_1\) is a weighted average of the prior mean and the sample mean:
\[ \mu_1 = \frac{\mu_0 \tau_0 + n\bar{x}\tau}{\tau_0 + n\tau} \]
So, the posterior distribution is:
\[ \mu|x_1, \dots, x_n \sim N\left( \frac{\mu_0 \tau_0 + n\bar{x}\tau}{\tau_0 + n\tau}, \frac{1}{\tau_0 + n\tau} \right) \]
Numerical Illustration:
Suppose we estimate a mean height \(\mu\).
- Known Variance: \(\sigma^2 = 100\) (\(\tau = 0.01\)).
- Prior: \(\mu \sim N(175, 25)\) (Precision \(\tau_0 = 0.04\)).
- Data: \(n=10, \bar{x}=180\). (Total data precision \(n\tau = 0.1\)).
- Posterior:
- Precision \(\tau_1 = 0.04 + 0.1 = 0.14\).
- Variance \(\sigma_1^2 \approx 7.14\).
- Mean \(\mu_1 = \frac{175(0.04) + 180(0.1)}{0.14} \approx 178.6\).
Figure 9.2 illustrates the prior (dashed) and posterior (solid) normal densities.
Code
mu_vals <- seq(150, 200, length.out = 200)
# Prior: N(175, 25) -> SD = 5
prior_norm <- dnorm(mu_vals, mean = 175, sd = 5)
# Posterior: N(178.6, 7.14) -> SD = Sqrt(7.14) Approx 2.67
posterior_norm <- dnorm(mu_vals, mean = 178.6, sd = sqrt(7.14))
plot(mu_vals, posterior_norm, type = 'l', lwd = 2, col = "blue",
xlab = expression(mu), ylab = "Density",
main = "Normal Prior vs Posterior",
ylim = c(0, max(c(prior_norm, posterior_norm))))
lines(mu_vals, prior_norm, col = "red", lty = 2, lwd = 2)
legend("topleft", legend = c("Prior N(175, 25)", "Posterior N(178.6, 7.14)"),
col = c("red", "blue"), lty = c(2, 1), lwd = 2)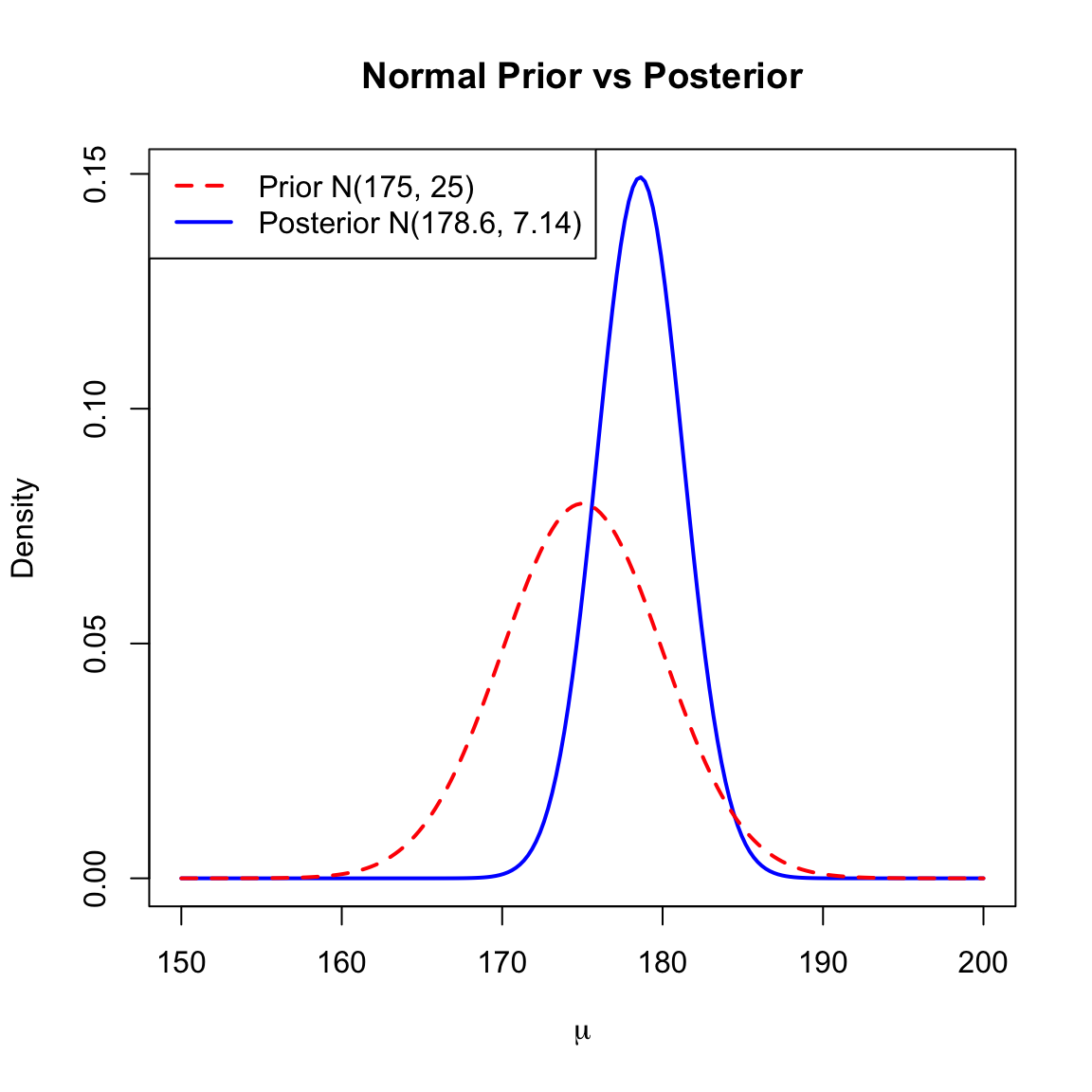
9.1.4 Normal with Unknown Mean and Variance
Example 9.4 (Normal with Unknown Mean and Variance) Consider \(X_1, \dots, X_n \sim N(\mu, 1/\tau)\), where both \(\mu\) and the precision \(\tau\) are unknown.
We use a Normal-Gamma conjugate prior with parameters \(\mu_0, \tau_0, \alpha_0, w_0\):
\(\tau \sim \text{Gamma}(\alpha_0/2, \alpha_0 w_0/2)\) \[ \pi(\tau) \propto \tau^{\alpha_0/2 - 1} \exp\left\{ -\frac{\alpha_0 w_0}{2} \tau \right\} \]
\(\mu|\tau \sim N(\mu_0, 1/(\tau_0\tau))\) \[ \pi(\mu|\tau) \propto \tau^{1/2} \exp\left\{ -\frac{\tau_0\tau}{2}(\mu-\mu_0)^2 \right\} \]
The joint prior is: \[ \pi(\mu, \tau) \propto \tau^{(\alpha_0+1)/2 - 1} \exp\left\{ -\frac{\tau}{2} \left( \alpha_0 w_0 + \tau_0(\mu - \mu_0)^2 \right) \right\} \]
The Likelihood:
To derive the Maximum Likelihood Estimators (MLEs), we work with the log-likelihood function \(l(\mu, \tau) = \log L(\mu, \tau)\):
\[ \begin{aligned} l(\mu, \tau) &= \log \left( \tau^{n/2} \exp\left\{ -\frac{\tau}{2} [ S_{xx} + n(\bar{x}-\mu)^2 ] \right\} \right) \\ &= \frac{n}{2} \log \tau - \frac{\tau}{2} \left[ S_{xx} + n(\bar{x}-\mu)^2 \right] + \text{const} \end{aligned} \]
MLE for \(\mu\)
Differentiating \(l(\mu, \tau)\) with respect to \(\mu\) and setting to zero:
\[ \frac{\partial l}{\partial \mu} = n\tau(\bar{x} - \mu) = 0 \implies \hat{\mu}_{\text{MLE}} = \bar{x} \]
MLE for \(\sigma^2\)
Differentiating \(l(\mu, \tau)\) with respect to \(\tau\), setting to zero, and substituting \(\mu = \bar{x}\):
\[ \frac{\partial l}{\partial \tau} = \frac{n}{2\tau} - \frac{S_{xx}}{2} = 0 \implies \hat{\tau}_{\text{MLE}} = \frac{n}{S_{xx}} \]
Using the invariance property (\(\sigma^2 = 1/\tau\)):
\[ \hat{\sigma}^2_{\text{MLE}} = \frac{S_{xx}}{n} = \frac{\sum_{i=1}^n (x_i - \bar{x})^2}{n} \]
Derivation of the Posterior:
Multiplying the prior by the likelihood gives the joint posterior density. We organize the terms to separate the marginal distribution of \(\tau\) from the conditional distribution of \(\mu\):
\[ \begin{aligned} \pi(\mu, \tau | x) &\propto \underbrace{\tau^{(\alpha_0 + n)/2 - 1} \exp\left\{ -\frac{\tau}{2} \left[ \alpha_0 w_0 + S_{xx} + \frac{n\tau_0}{n+\tau_0}(\bar{x}-\mu_0)^2 \right] \right\}}_{\text{Marginal of } \tau} \\ &\quad \times \underbrace{\tau^{1/2} \exp\left\{ -\frac{(n+\tau_0)\tau}{2} \left( \mu - \frac{\tau_0\mu_0+n\bar{x}}{n+\tau_0} \right)^2 \right\}}_{\text{Conditional of } \mu|\tau} \end{aligned} \]
Results:
Conditional Posterior of \(\mu|\tau, x\): \[ \mu|\tau, x \sim N(\mu', 1/(\tau'\tau)) \] \[ E^{\mu|\tau, X}[\mu] = \frac{\tau_0\mu_0 + n\bar{x}}{\tau_0 + n} \] where \[\tau' = \tau_0 + n\] \[\mu' = \frac{\tau_0\mu_0 + n\bar{x}}{\tau_0 + n}\]
Marginal Posterior of \(\tau|x\): The marginal posterior is \(\tau|x \sim \text{Gamma}(\alpha', \beta')\) with: \[ \alpha' = \frac{\alpha_0 + n}{2}, \quad \beta' = \frac{\alpha_0 w_0 + n\hat{\sigma}^2_{\text{MLE}} + \frac{n\tau_0}{n+\tau_0}(\bar{x}-\mu_0)^2}{2} \]
Using the approximation \(E^{\sigma^2|X}[\sigma^2] \approx 1/E^{\tau|X}[\tau] = \beta'/\alpha'\), the posterior expectation of the variance is a weighted average of the prior variance, the data variance, and the discrepancy between the prior and data means:
\[ E^{\sigma^2|X}[\sigma^2] \approx \frac{\alpha_0 w_0 + n\hat{\sigma}^2_{\text{MLE}} + \frac{1}{1/n+1/\tau_0}(\bar{x}-\mu_0)^2}{\alpha_0 + n} \]
Conditional Posterior of \(\tau|\mu, x\): If \(\mu\) is considered known, the posterior for \(\tau\) combines the prior \(\alpha_0, w_0\) with the deviations from \(\mu\). Note that the prior term \(\pi(\mu|\tau)\) contributes an extra factor of \(\tau^{1/2}\) to the shape.
\[ \tau|\mu, x \sim \text{Gamma}(\alpha'', \beta'') \]
Where: \[ \alpha'' = \frac{\alpha_0 + n + 1}{2}, \quad \beta'' = \frac{\alpha_0 w_0 + \sum_{i=1}^n (x_i-\mu)^2 + \tau_0(\mu-\mu_0)^2}{2} \]
The approximate expectation of the variance is: \[ E^{\sigma^2|\mu, X}[\sigma^2] \approx \frac{\alpha_0 w_0 + \sum_{i=1}^n (x_i-\mu)^2 + \tau_0(\mu-\mu_0)^2}{\alpha_0 + n + 1} \]
9.2 Finding Bayes Rules via Minimizing Posterior Expected Loss
The general form of Bayes rule is derived by minimizing risk.
Definition 9.2 (Risk Function and Bayes Risk) Setup and Notation:
- \(\theta \in \Theta\): parameter of interest (unknown state of nature)
- \(x \in X\): observed data
- \(\pi(\theta)\): prior probability distribution over the parameter space
- \(f(x;\theta)\): likelihood or sampling distribution of the data given the parameter
- \(d: X \to A\): decision rule mapping observed data to an action/decision
- \(\mathcal{L}(\theta, a)\): loss function measuring the loss incurred when the true parameter is \(\theta\) and action \(a\) is taken
Definition:
Risk Function: For a given decision rule \(d\) and parameter value \(\theta\), \[R(\theta, d) = \int_{X} \mathcal{L}(\theta, d(x)) f(x;\theta) dx = E^{X|\theta} [ \mathcal{L}(\theta, d(X)) ]\] is the expected loss with respect to the sampling distribution when the true parameter is \(\theta\).
Bayes Risk: For a decision rule \(d\) and prior distribution \(\pi\), \[r(\pi, d) = \int_{\Theta} R(\theta, d) \pi(\theta) d\theta = E^\theta [ R(\theta, d) ]\] is the expected risk averaging over both the parameter uncertainty (prior) and the data variability (likelihood).
Posterior Bayes Loss: The minimum possible expected loss given observed data \(x\) is denoted as \(\rho^{\text{Bayes}}(\pi, x)\). It represents the expected posterior loss of the Bayes rule: \[ \rho^{\text{Bayes}}(\pi, x) = \inf_{d} E^{\theta|x} [ \mathcal{L}(\theta, d) ] \]
Theorem 9.1 (Minimization of Bayes Risk) Minimizing the Bayes risk \(r(\pi, d)\) is equivalent to minimizing the posterior expected loss for each observed \(x\). That is, the Bayes rule \(d(x)\) is defined as \[ d^{\text{Bayes}}(x) = \underset{a}{\arg\min} \ E^{\theta|X} [ \mathcal{L}(\theta, a) ] \] The value of the minimum expected posterior loss is \(\rho^{\text{Bayes}}(\pi, x)\).
Proof. We start by writing the Bayes risk essentially as a double integral over the parameters and the data. Substituting the definition of the risk function \(R(\theta, d)\):
\[ \begin{aligned} r(\pi, d) &= \int_{\Theta} R(\theta, d) \pi(\theta) d\theta \\ &= \int_{\Theta} \left[ \int_{X} \mathcal{L}(\theta, d(x)) f(x|\theta) dx \right] \pi(\theta) d\theta \end{aligned} \]
Assuming the conditions for Fubini’s Theorem are met, we switch the order of integration:
\[ r(\pi, d) = \int_{X} \left[ \int_{\Theta} \mathcal{L}(\theta, d(x)) f(x|\theta) \pi(\theta) d\theta \right] dx \]
Recall that the joint density can be factored as \(f(x, \theta) = f(x|\theta)\pi(\theta) = \pi(\theta|x)m(x)\), where \(m(x)\) is the marginal density of the data. Substituting this into the inner integral:
\[ \begin{aligned} r(\pi, d) &= \int_{X} \left[ \int_{\Theta} \mathcal{L}(\theta, d(x)) \pi(\theta|x) m(x) d\theta \right] dx \\ &= \int_{X} m(x) \left[ \int_{\Theta} \mathcal{L}(\theta, d(x)) \pi(\theta|x) d\theta \right] dx \end{aligned} \]
Since the marginal density \(m(x)\) is non-negative, minimizing the total integral \(r(\pi, d)\) with respect to the decision rule \(d(\cdot)\) is equivalent to minimizing the term inside the brackets for every \(x\) (specifically where \(m(x) > 0\)).
The term inside the brackets is the Posterior Expected Loss:
\[ \int_{\Theta} \mathcal{L}(\theta, d(x)) \pi(\theta|x) d\theta = E^{\theta|X} [ \mathcal{L}(\theta, d(X)) ] \]
Important
Therefore, to minimize the Bayes risk, one effectively minimizes the posterior expected loss for each \(x\). This relationship relies on the key identity for the total expectation of the loss:
\[ \boxed{ r(\pi, d) = E^X \left[ E^{\theta|X} \big( \mathcal{L}(\theta, d(X)) \big) \right] = E^\theta \left[ E^{X|\theta} \big( \mathcal{L}(\theta, d(X)) \big) \right] } \]
In the first expression, the outer expectation \(E^X\) is taken with respect to the marginal density of the data, \(m(x)\), defined as: \[ m(x) = \int_{\Theta} f(x|\theta)\pi(\theta) d\theta \]
In the second expression, the outer expectation \(E^\theta\) is taken with respect to the prior density \(\pi(\theta)\).
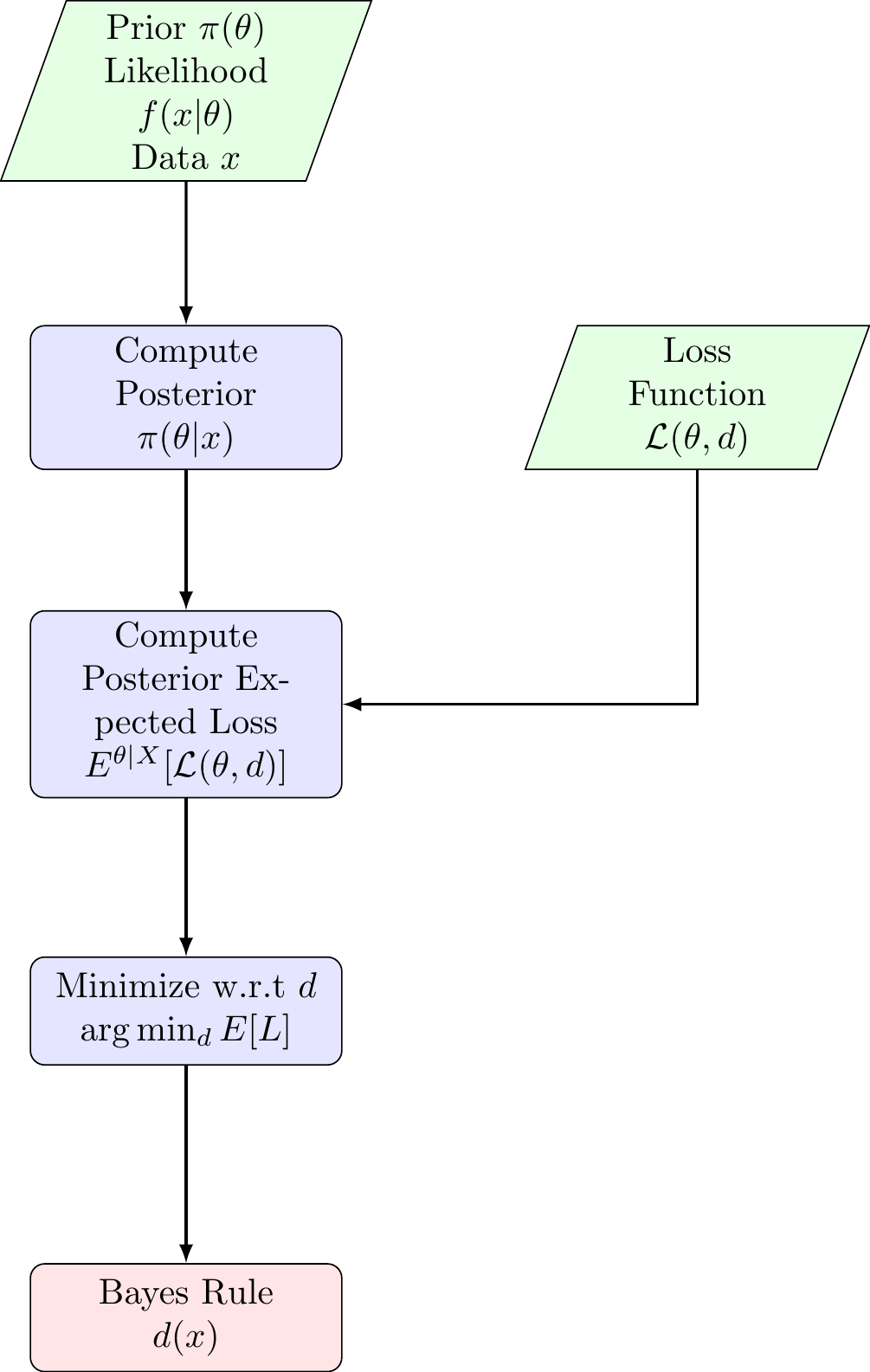
The following diagram summarizes the general workflow for deriving a Bayes estimator:
9.3 Special Bayes Rules
9.3.1 Squared Error Loss (point Estimate)
\[\mathcal{L}(\theta, a) = (\theta - a)^2\]
To find the optimal estimator \(d(x)\), we minimize the posterior expected loss \(E^{\theta|X}[(\theta - d(X))^2]\). Taking the derivative with respect to \(d\) and setting it to 0:
\[-2 E^{\theta|X}(\theta - d) = 0 \implies d(X) = E^{\theta|X}[\theta]\]
Result: The Bayes rule under squared error loss is the posterior mean.
9.3.2 Scale-Invariant Squared Error Loss
Consider the loss function that penalizes relative errors rather than absolute errors. This is particularly useful when the magnitude of the parameter \(\theta\) varies significantly, and an error of 1.0 is “worse” when \(\theta=1\) than when \(\theta=1000\).
\[ \mathcal{L}(\theta, d) = \left( \frac{d - \theta}{\theta} \right)^2 = \left( \frac{d}{\theta} - 1 \right)^2 \]
To find the Bayes rule, we minimize the posterior expected loss \(E^{\theta|X} [\mathcal{L}(\theta, d)]\):
\[ Q(d) = E^{\theta|X} \left[ \frac{d^2}{\theta^2} - \frac{2d}{\theta} + 1 \right] = d^2 E^{\theta|X}[\theta^{-2}] - 2d E^{\theta|X}[\theta^{-1}] + 1 \]
Differentiating with respect to \(d\) and setting to zero:
\[ \frac{\partial Q}{\partial d} = 2d E^{\theta|X}[\theta^{-2}] - 2 E^{\theta|X}[\theta^{-1}] = 0 \]
Solving for \(d\):
\[ d(X) = \frac{E^{\theta|X}[\theta^{-1}]}{E^{\theta|X}[\theta^{-2}]} \]
Result: The Bayes rule under scale-invariant squared error loss is the ratio of the posterior mean of \(\theta^{-1}\) to the posterior mean of \(\theta^{-2}\).
9.3.3 Absolute Error Loss
\[\mathcal{L}(\theta, d) = |\theta - d|\]
To find the Bayes rule, we minimize the posterior expected loss:
\[ \psi(d) = E^{\theta|X} [ |\theta - d| ] = \int_{-\infty}^{\infty} |\theta - d| \, dF(\theta|x) \]
where \(F(\theta|x)\) is the cumulative distribution function (CDF) of the posterior. Splitting the integral at the decision point \(d\):
\[ \psi(d) = \int_{-\infty}^{d} (d - \theta) \, dF(\theta|x) + \int_{d}^{\infty} (\theta - d) \, dF(\theta|x) \]
We find the minimum by analyzing the rate of change of \(\psi(d)\) with respect to \(d\). Differentiating (or taking the subgradient for non-differentiable points):
\[ \frac{\partial}{\partial d} \psi(d) = \int_{-\infty}^{d} 1 \, dF(\theta|x) - \int_{d}^{\infty} 1 \, dF(\theta|x) = P(\theta \le d|x) - P(\theta > d|x) \]
Setting this derivative to zero implies we seek a point where the probability mass to the left equals the probability mass to the right:
\[ P(\theta \le d|x) = P(\theta > d|x) \]
Since the total probability is 1, this condition simplifies to finding \(d\) such that the cumulative probability is \(1/2\).
General Case (Discrete or Mixed Distributions)
In cases where the posterior distribution is discrete or has jump discontinuities (e.g., the CDF jumps from 0.4 to 0.6 at a specific value), an exact solution to \(F(d) = 0.5\) may not exist. To generalize, the Bayes rule is defined as any median \(m\) of the posterior distribution.
A median is formally defined as any value \(m\) that satisfies the following two conditions simultaneously:
- \(P(\theta \le m|x) \ge \frac{1}{2}\)
- \(P(\theta \ge m|x) \ge \frac{1}{2}\)
Result: The Bayes rule under absolute error loss is the posterior median.
9.3.4 Weighted Absolute Error Loss (min-normalization)
\[\mathcal{L}(\theta, d) = \frac{|\theta - d|}{\min(\theta, 1-\theta)}\]
This loss function penalizes errors extremely heavily when the true parameter \(\theta\) is near the boundaries (0 or 1). Because the denominator approaches zero at the boundaries, the “cost” of an error becomes infinite, forcing the estimator to be very cautious (conservative) if the posterior has significant mass near 0 or 1.
To find the Bayes rule, we minimize the posterior expected loss. Let \(\pi(\theta|x)\) denote the posterior density.
\[ \psi(d) = E^{\theta|X} \left[ \frac{|\theta - d|}{\min(\theta, 1-\theta)} \right] = \int \frac{|\theta - d|}{\min(\theta, 1-\theta)} \pi(\theta|x) \, d\theta \]
Let \(w(\theta) = \frac{1}{\min(\theta, 1-\theta)}\). We can view this integral as an expectation with respect to a weighted posterior density \(\pi^*(\theta|x)\):
\[ \pi^*(\theta|x) \propto w(\theta) \pi(\theta|x) = \frac{\pi(\theta|x)}{\min(\theta, 1-\theta)} \]
Result: The Bayes rule is the median of the weighted posterior distribution \(\pi^*(\theta|x)\).
9.3.4.0.1 Importance Sampling for Weighted Median
Goal: Estimate the median of \(\pi^*(\theta|x) \propto w(\theta)\pi(\theta|x)\) using samples from \(\pi(\theta|x)\).
Sample: Generate \(M\) independent draws \(\theta_1, \dots, \theta_M\) from the standard posterior \(\pi(\theta|x)\).
Weight: For each \(i = 1, \dots, M\), compute the importance weight: \[ W_i = w(\theta_i) = \frac{1}{\min(\theta_i, 1-\theta_i)} \]
Sort: Reorder the samples such that \(\theta_{(1)} \le \theta_{(2)} \le \dots \le \theta_{(M)}\). Permute the weights \(W_{(1)}, \dots, W_{(M)}\) to match this ordering.
Accumulate: Compute the cumulative weights: \[ S_k = \sum_{j=1}^k W_{(j)} \quad \text{for } k=1, \dots, M \]
Select: Find the smallest index \(k^*\) such that the cumulative weight exceeds half the total weight: \[ k^* = \min \{ k : S_k \ge 0.5 \times S_M \} \]
Output: Return the estimator \(\hat{\delta} = \theta_{(k^*)}\).
Numerical Example: Beta(2, 10)
We compare the “exact” weighted median (found by numerical integration) with the Monte Carlo estimate for a skewed distribution.
Code
# 1. Setup
set.seed(2025)
M <- 10
alpha <- 2
beta <- 10
theta_samples <- rbeta(M, alpha, beta)
w <- function(theta) { 1 / pmin(theta, 1 - theta) }
# 2. Process
weights <- w(theta_samples)
ord <- order(theta_samples)
sorted_theta <- theta_samples[ord]
sorted_weights <- weights[ord]
cum_weights <- cumsum(sorted_weights)
total_weight <- sum(sorted_weights)
threshold <- 0.5 * total_weight
# Find k
k_idx <- which(cum_weights >= threshold)[1]
# 3. Create Data Frame
selection_table <- data.frame(
idx = 1:M,
theta = sorted_theta,
weight = sorted_weights,
cum_weight = cum_weights,
check = ifelse(cum_weights >= threshold, "$\\ge$ Threshold", "$<$ Threshold"),
sel = ifelse(1:M == k_idx, "$\\leftarrow k$ (Median)", "")
)
# 4. Set LaTeX Column Names
# Note: We use double backslashes \\ for LaTeX commands inside R strings
colnames(selection_table) <- c(
"$i$",
"$\\theta_{(i)}$", # Sorted Theta
"$w_{(i)}$", # Sorted Weight
"$\\sum_{j=1}^i w_{(j)}$",# Cumulative Sum
"Condition",
"Selection"
)
# Print Context
cat("Total Weight ($\\sum w_i$):", total_weight, "\n")Total Weight ($\sum w_i$): 48.91008 Code
cat("Threshold ($0.5 \\times \\sum w_i$):", threshold, "\n\n")Threshold ($0.5 \times \sum w_i$): 24.45504 Code
# 5. Render Table with escape = FALSE
# escape = FALSE is crucial; otherwise, it prints the dollar signs literally
knitr::kable(selection_table,
digits = 4,
align = "c",
escape = FALSE)| \(i\) | \(\theta_{(i)}\) | \(w_{(i)}\) | \(\sum_{j=1}^i w_{(j)}\) | Condition | Selection |
|---|---|---|---|---|---|
| 1 | 0.1256 | 7.9601 | 7.9601 | \(<\) Threshold | |
| 2 | 0.1462 | 6.8412 | 14.8013 | \(<\) Threshold | |
| 3 | 0.1563 | 6.3965 | 21.1978 | \(<\) Threshold | |
| 4 | 0.1714 | 5.8329 | 27.0307 | \(\ge\) Threshold | \(\leftarrow k\) (Median) |
| 5 | 0.2221 | 4.5024 | 31.5330 | \(\ge\) Threshold | |
| 6 | 0.2265 | 4.4144 | 35.9475 | \(\ge\) Threshold | |
| 7 | 0.2676 | 3.7376 | 39.6850 | \(\ge\) Threshold | |
| 8 | 0.2840 | 3.5214 | 43.2064 | \(\ge\) Threshold | |
| 9 | 0.2990 | 3.3445 | 46.5509 | \(\ge\) Threshold | |
| 10 | 0.4239 | 2.3592 | 48.9101 | \(\ge\) Threshold |
Actual Weighted Median with 1000 draws of \(\theta\)
Code
# 1. Setup Parameters
set.seed(123)
M <- 1000
alpha <- 2
beta <- 10
# 2. Generate Samples and Weights
theta_samples <- rbeta(M, alpha, beta)
# Weight function: w(theta) = 1 / min(theta, 1-theta)
w <- function(theta) { 1 / pmin(theta, 1 - theta) }
weights <- w(theta_samples)
# 3. Sort and Calculate Cumulative Weights
ord <- order(theta_samples)
sorted_theta <- theta_samples[ord]
sorted_weights <- weights[ord]
cum_weights <- cumsum(sorted_weights)
total_weight <- sum(sorted_weights)
threshold <- 0.5 * total_weight
# 4. Find the Weighted Median Index k
k_idx <- which(cum_weights >= threshold)[1]
mc_weighted_median <- sorted_theta[k_idx]
# 5. Compare with Theoretical Value (calculated previously)
# Re-calculating theoretical for completeness of this chunk
weighted_dens_unnorm <- function(theta) { w(theta) * dbeta(theta, alpha, beta) }
C <- integrate(weighted_dens_unnorm, 0, 1)$value
weighted_cdf <- function(q) { integrate(weighted_dens_unnorm, 0, q)$value / C }
theo_median <- uniroot(function(x) weighted_cdf(x) - 0.5, c(0.001, 0.999))$root
# 6. Display Results
results <- data.frame(
"Method" = c("Theoretical (Integration)", "Monte Carlo (M=1000)", "Standard Median (Unweighted)"),
"Value" = c(theo_median, mc_weighted_median, qbeta(0.5, alpha, beta))
)
knitr::kable(results, digits = 4, align = "l", caption = "Weighted Median Estimation")| Method | Value |
|---|---|
| Theoretical (Integration) | 0.0670 |
| Monte Carlo (M=1000) | 0.0692 |
| Standard Median (Unweighted) | 0.1480 |
9.3.5 Hypothesis Testing (0-1 Loss)
Consider the hypothesis test \(H_0: \theta \in \Theta_0\) versus \(H_1: \theta \in \Theta_1\). We define the decision space as \(\mathcal{A} = \{0, 1\}\), where \(a=0\) means accepting \(H_0\) and \(a=1\) means rejecting \(H_0\) (accepting \(H_1\)).
Case 1: 0-1 Loss
The standard 0-1 loss function assigns a penalty of 1 for an incorrect decision and 0 for a correct one:
| State of Nature (\(\theta\)) | Action \(a=0\) (Accept \(H_0\)) | Action \(a=1\) (Reject \(H_0\)) |
|---|---|---|
| \(\theta \in \Theta_0\) (\(H_0\) True) | \(0\) (Correct) | \(1\) (Type I Error) |
| \(\theta \in \Theta_1\) (\(H_1\) True) | \(1\) (Type II Error) | \(0\) (Correct) |
To find the Bayes rule, we minimize the posterior expected loss for a given \(x\), denoted as \(E^{\theta|X}[\mathcal{L}(\theta, a)]\).
Expected Loss for choosing \(a=0\) (Accept \(H_0\)): \[ E^{\theta|X}[\mathcal{L}(\theta, 0)] = 0 \cdot P(\theta \in \Theta_0|x) + 1 \cdot P(\theta \in \Theta_1|x) = P(\theta \in \Theta_1|x) \]
Expected Loss for choosing \(a=1\) (Reject \(H_0\)): \[ E^{\theta|X}[\mathcal{L}(\theta, 1)] = 1 \cdot P(\theta \in \Theta_0|x) + 0 \cdot P(\theta \in \Theta_1|x) = P(\theta \in \Theta_0|x) \]
The Bayes rule selects the action with the smaller expected loss. Thus, we choose \(a=1\) if: \[ P(\theta \in \Theta_0|x) \le P(\theta \in \Theta_1|x) \] This confirms that under 0-1 loss, the Bayes rule simply selects the hypothesis with the higher posterior probability. The optimal Bayes decision rule \(d(x)\) is given by:
\[ d(x) = \begin{cases} 1 & \text{if } P(\Theta_0|x) \le \frac{1}{2} \quad (\text{Reject } H_0) \\ 0 & \text{if } P(\Theta_0|x) > \frac{1}{2} \quad (\text{Accept } H_0) \end{cases} \]
Case 2: General Loss (Asymmetric Costs)
In many practical applications, the cost of errors is not symmetric. For example, a Type I error (false rejection) might be more costly than a Type II error. Let \(c_1\) be the cost of a Type I error and \(c_2\) be the cost of a Type II error. Usually, we normalize one cost to 1.
| State of Nature (\(\theta\)) | Action \(a=0\) (Accept \(H_0\)) | Action \(a=1\) (Reject \(H_0\)) |
|---|---|---|
| \(\theta \in \Theta_0\) (\(H_0\) True) | \(0\) | \(c\) (Type I Error) |
| \(\theta \in \Theta_1\) (\(H_1\) True) | \(1\) (Type II Error) | \(0\) |
We again calculate the posterior expected loss:
Expected Loss for \(a=0\): \[E^{\theta|X}[\mathcal{L}(\theta, 0)] = 0 \cdot P(\Theta_0|x) + 1 \cdot P(\Theta_1|x) = P(\Theta_1|x)\]
Expected Loss for \(a=1\): \[E^{\theta|X}[\mathcal{L}(\theta, 1)] = c \cdot P(\Theta_0|x) + 0 \cdot P(\Theta_1|x) = c P(\Theta_0|x)\]
We reject \(H_0\) (\(a=1\)) if the expected loss of doing so is lower: \[ c P(\Theta_0|x) \le P(\Theta_1|x) \]
Since \(P(\Theta_1|x) = 1 - P(\Theta_0|x)\), we can rewrite this condition as: \[ c P(\Theta_0|x) \le 1 - P(\Theta_0|x) \implies (1+c) P(\Theta_0|x) \le 1 \] \[ P(\Theta_0|x) \le \frac{1}{1+c} \]
Result: With asymmetric costs, we accept \(H_1\) only if the posterior probability of the null hypothesis is sufficiently small (below the threshold \(\frac{1}{1+c}\)). If the cost of false rejection \(c\) is high, we require stronger evidence against \(H_0\). The optimal Bayes decision rule \(d(x)\) is given by:
\[ d(x) = \begin{cases} 1 & \text{if } P(\Theta_0|x) \le \frac{1}{1+c} \quad (\text{Reject } H_0) \\ 0 & \text{if } P(\Theta_0|x) > \frac{1}{1+c} \quad (\text{Accept } H_0) \end{cases} \]
9.3.6 Classification Prediction
In classification problems, the parameter of interest is a discrete class label \(y\) taking values in a set of categories \(\{1, 2, \dots, K\}\). The goal is to predict the true class label based on observed features \(x\).
We typically employ the 0-1 loss function, which assigns a penalty of 1 for a misclassification and 0 for a correct prediction:
\[\mathcal{L}(y, \hat{y}) = \begin{cases} 0 & \text{if } \hat{y} = y \ (\text{Correct Classification}) \\ 1 & \text{if } \hat{y} \neq y \ (\text{Misclassification}) \end{cases}\]
To find the optimal classification rule (the Bayes Classifier), we minimize the posterior expected loss, which is equivalent to minimizing the probability of misclassification.
\[ E^{Y|X}[\mathcal{L}(y, \hat{y})] = \sum_{y} \mathcal{L}(y, \hat{y}) P(y|x) \]
Since the loss is 1 only when the predicted class \(\hat{y}\) differs from the true class \(y\), this sum simplifies to:
\[ E^{Y|X}[\mathcal{L}(y, \hat{y})] = \sum_{y \neq \hat{y}} 1 \cdot P(y|x) = P(y \neq \hat{y} | x) = 1 - P(y = \hat{y} | x) \]
Minimizing the misclassification rate \(1 - P(y = \hat{y} | x)\) is mathematically equivalent to maximizing the probability of being correct, \(P(y = \hat{y} | x)\).
Result:
The Bayes rule for classification is to predict the class with the highest posterior predictive probability. In the context of machine learning and pattern recognition, this decision rule is known as the Bayes Optimal Classifier.
\[ \hat{y}_{\text{Bayes}}(x) = \underset{k \in \{1, \dots, K\}}{\arg\max} \ P(y = k | x) \]
9.3.7 Interval Estimation as a Decision Problem
We can motivate the choice of a Credible Interval by defining a specific loss function for interval estimation. We define the action space \(\mathcal{A}\) as the set of all intervals of fixed radius \(\delta > 0\) centered at \(d\), i.e., \(\mathcal{A} = \{ [d - \delta, d + \delta] \mid d \in \mathbb{R} \}\).
The loss function is defined as: \[ \mathcal{L}(\theta, d) = \begin{cases} 0 & \text{if } |\theta - d| \le \delta \quad (\theta \in [d-\delta, d+\delta]) \\ 1 & \text{if } |\theta - d| > \delta \quad (\theta \notin [d-\delta, d+\delta]) \end{cases} \]
Derivation of the Bayes Rule
We minimize the Expected Posterior Loss, which is simply the probability that \(\theta\) falls outside the interval: \[ E^{\theta|X}[\mathcal{L}(\theta, d)] = 1 \cdot P(|\theta - d| > \delta | x) = 1 - P(d - \delta \le \theta \le d + \delta | x) \]
Minimizing this loss is equivalent to maximizing the posterior probability mass contained within the interval. Thus, the Bayes estimator \(d\) is: \[ d_{\text{Bayes}} = \underset{d}{\arg\max} \int_{d-\delta}^{d+\delta} \pi(\theta|x) \, d\theta \]
To find the optimal \(d\), we differentiate the integral with respect to \(d\) and set it to zero: \[ \frac{\partial}{\partial d} \left( \int_{d-\delta}^{d+\delta} \pi(\theta|x) \, d\theta \right) = \pi(d+\delta|x) - \pi(d-\delta|x) = 0 \]
This yields the condition \(\pi(d+\delta|x) = \pi(d-\delta|x)\).
The optimal \(d\) centers the interval such that the posterior density heights at the two endpoints are equal. This is the defining characteristic of a Highest Posterior Density (HPD) interval.
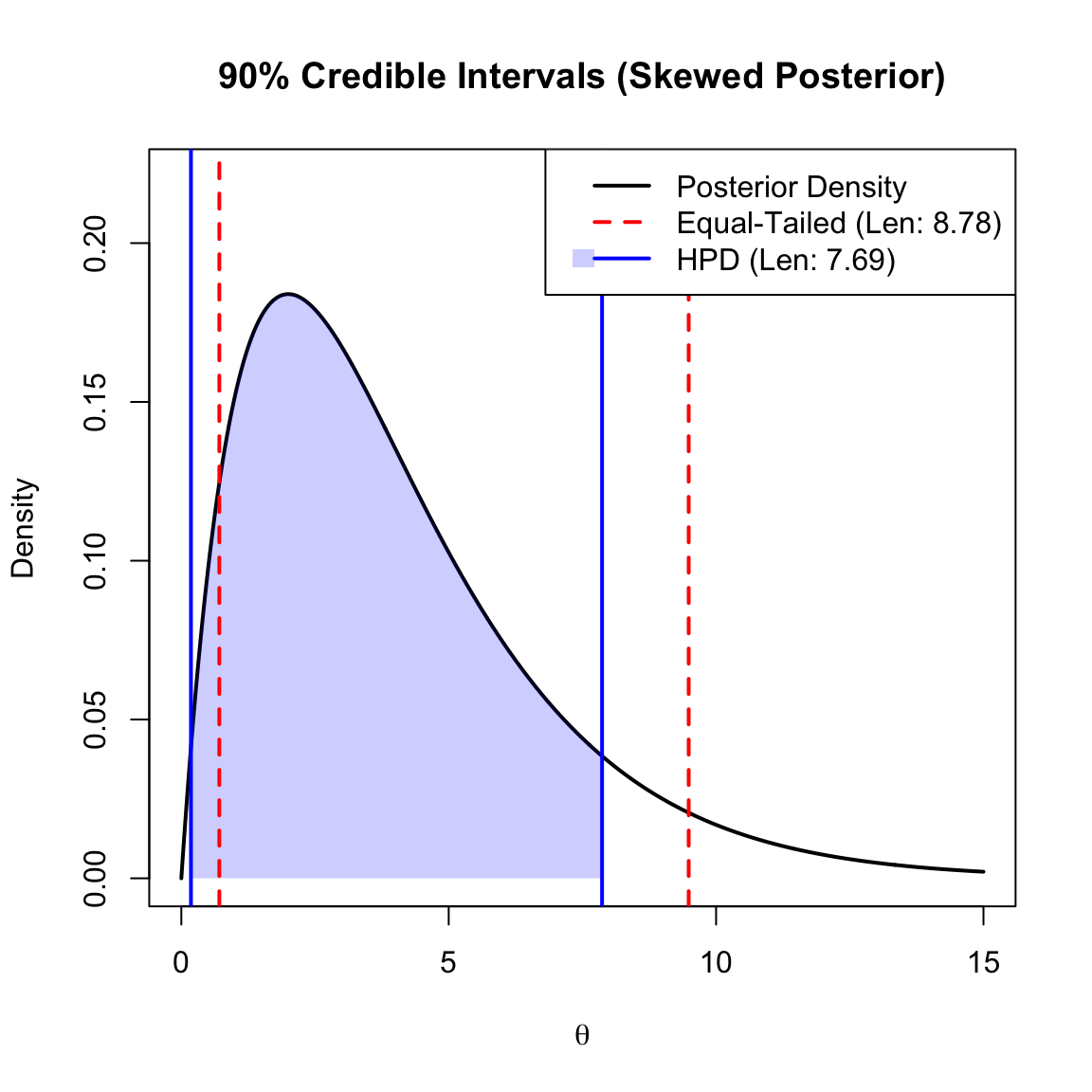
Comparison with Equal-Tailed Intervals:
- Equal-Tailed Interval: We simply cut off \(\alpha/2\) probability from each tail of the distribution. This is easy to compute but may not be the shortest interval if the distribution is skewed.
- HPD Interval: This is the shortest possible interval for the given coverage. For unimodal distributions, the probability density at the two endpoints of the HPD interval is identical.
The plot below illustrates a skewed posterior distribution (Gamma). Notice how the HPD Interval (Blue) is shifted toward the mode (the peak) to capture the highest density values, resulting in a shorter interval length compared to the Equal-Tailed Interval (Red).
9.4 Finding Minimax Rules with Bayes Rules
Theorem 2.1 states that if a Bayes estimator \(\delta^\pi\) (derived from a prior \(\pi\)) yields a constant risk \(R(\theta, \delta^\pi) = c\) across the entire parameter space \(\Theta\), then that estimator is necessarily minimax.
This result is a cornerstone of decision theory because it provides a sufficient condition for minimaxity. While the minimax criterion focuses on the “worst-case scenario” by minimizing the maximum possible risk, the Bayes criterion focuses on the “average-case scenario” relative to a prior. When the risk is constant, these two perspectives align: the average risk equals the maximum risk, and no other estimator can achieve a lower maximum without also having a lower Bayes risk, which would contradict the optimality of the Bayes rule.
9.4.1 Binomial Minimax Estimator
Example 9.5 Let \(X \sim \text{Bin}(n, \theta)\) and \(\theta \sim \text{Beta}(a, b)\). The squared error loss is \(\mathcal{L}(\theta, d) = (\theta - d)^2\). The Bayes estimator is the posterior mean: \[d(X) = \frac{a+X}{a+b+n}\]
We calculate the risk \(R(\theta, d)\):
\[ R(\theta, d) = E^{X|\theta} \left[ \left( \theta - \frac{a+X}{a+b+n} \right)^2 \right] \]
Let \(c = a+b+n\). \[R(\theta, d) = \frac{1}{c^2} E^{X|\theta} \left[ (c\theta - a - X)^2 \right]\]
Using the bias-variance decomposition and knowing \(E^{X|\theta}[X] = n\theta\) and \(E^{X|\theta}[X^2] = (n\theta)^2 + n\theta(1-\theta)\), we expand the risk function. To make the risk constant (independent of \(\theta\)), we set the coefficients of \(\theta\) and \(\theta^2\) to zero.
Solving the resulting system of equations yields: \[a = b = \frac{\sqrt{n}}{2}\]
Thus, the minimax estimator is: \[d(X) = \frac{X + \sqrt{n}/2}{n + \sqrt{n}}\]
This differs from the standard MLE \(\hat{p} = X/n\) and the uniform prior Bayes estimator (\(a=b=1\)).
According to Theorem 2.2, let \(\{\delta_n\}\) be a sequence of Bayes rules with respect to priors \(\{\pi_n\}\), and let \(r(\pi_n, \delta_n)\) be the associated Bayes risks. If there exists a rule \(\delta_0\) such that \[ \sup_{\theta} R(\theta, \delta_0) \le \lim_{n \to \infty} r(\pi_n, \delta_n) \] then \(\delta_0\) is a minimax estimator.
We can rewrite the Minimax estimator \(d(X)\) as a linear combination of the sample proportion (MLE) \(\hat{p} = X/n\) and the prior mean \(p_0 = 1/2\):
\[ d(X) = \underbrace{\left( \frac{n}{n + \sqrt{n}} \right)}_{w} \underbrace{\left( \frac{X}{n} \right)}_{\hat{p}} + \underbrace{\left( \frac{\sqrt{n}}{n + \sqrt{n}} \right)}_{1-w} \underbrace{\left( \frac{1}{2} \right)}_{p_0} \]
\[ d(X) = w \hat{p} + (1-w) p_0 \]
Interpretation:
- \(p_0 = 0.5\): The estimator shrinks the data toward a neutral prior mean of \(0.5\) (representing maximum uncertainty).
- \(w = \frac{n}{n+\sqrt{n}}\): The weight assigned to the data. As the sample size \(n\) increases, \(w \to 1\), and the minimax estimator converges to the MLE.
9.4.2 Exponential Minimax Estimation
Let’s recall Theorem 2.2. If there exists a rule \(\delta_0\) such that: \[ \sup_{\theta} R(\theta, \delta_0) \le \lim_{n \to \infty} r(\pi_n, \delta_n), \] where \(\{\delta_n\}\) is a sequence of Bayes rules with respect to priors \(\{\pi_n\}\) and \(r(\pi_n, \delta_n)\) is the associated Bayes risks. Then \(\delta_0\) is Minimax. This theorem is frequently used when a minimax estimator corresponds to an “improper” prior (a prior that does not integrate to 1, such as a uniform distribution on an infinite interval). Since Bayes rules cannot be directly defined for improper priors in the standard risk framework, we approximate the improper prior with a sequence of proper priors \(\{\pi_k\}\). If the risk of our proposed estimator \(\delta_0\) acts as a ceiling that the Bayes risks approach from below, \(\delta_0\) effectively guards against the “least favorable” conditions, satisfying the minimax criterion.
Example 9.6 (Exponential Minimax Estimation) Let \(X_1, \dots, X_n\) be a sample from an \(\text{Exp}(\theta)\) distribution with mean \(\theta\). We consider the Scale-Invariant Loss Function:
\[ \mathcal{L}(\theta, d) = \left( \frac{d}{\theta} - 1 \right)^2 \]
Likelihood and MLE
The probability density function for a single observation is \(f(x_i|\theta) = \frac{1}{\theta} e^{-x_i/\theta}\). The likelihood function for the sample is:
\[ L(\theta|x) = \theta^{-n} e^{-\frac{1}{\theta}\sum_{i=1}^n x_i} \]
The Maximum Likelihood Estimator is standard: \(\hat{\theta}_{\text{MLE}} = \bar{X}\).
Minimax Estimation Setup
We propose the estimator \(d_0(X) = \frac{\sum X_i}{n+1}\). To show this is a minimax estimator, we consider a sequence of priors \(\pi_k\) and examine the limit of their Bayes risks.
Prior Density
We assume the prior \(\pi_k(\theta)\) follows an Inverse-Gamma distribution with shape \(\alpha_k\) and scale \(\beta_k\). The density is given by:
\[ \pi_k(\theta) = \frac{\beta_k^{\alpha_k}}{\Gamma(\alpha_k)} \theta^{-\alpha_k - 1} e^{-\beta_k / \theta}, \quad \theta > 0 \]
Posterior Analysis
Let \(T = \sum X_i\). The posterior density is proportional to:
\[ \pi(\theta | x) \propto \left( \theta^{-n} e^{-T/\theta} \right) \cdot \left( \theta^{-\alpha_k - 1} e^{-\beta_k / \theta} \right) \propto \theta^{-(n + \alpha_k) - 1} e^{-(T + \beta_k)/\theta} \]
This is an Inverse-Gamma distribution with parameters \(\alpha^* = n + \alpha_k\) and \(\beta^* = T + \beta_k\).
Calculation of the Bayes Estimator
Using the result derived in the Scale-Invariant Squared Error Loss section, the Bayes estimator is:
\[ d_{\pi_k}(X) = \frac{E^{\theta|X}[\theta^{-1}]}{E^{\theta|X}[\theta^{-2}]} \]
For an Inverse-Gamma\((\alpha^*, \beta^*)\) variable, the required moments are:
- \(E^{\theta|X}[\theta^{-1}] = \frac{\alpha^*}{\beta^*}\)
- \(E^{\theta|X}[\theta^{-2}] = \frac{\alpha^* (\alpha^* + 1)}{(\beta^*)^2}\)
Substituting these into the estimator formula:
\[ d_{\pi_k}(X) = \frac{ \frac{\alpha^*}{\beta^*} }{ \frac{\alpha^* (\alpha^* + 1)}{(\beta^*)^2} } = \frac{\beta^*}{\alpha^* + 1} = \frac{T + \beta_k}{n + \alpha_k + 1} \]
Bayes Risk Limit
The Bayes risk \(r(\pi_k, d_{\pi_k})\) is the expected value of the minimum posterior loss. Substituting \(d_{\pi_k}\) back into the loss equation:
\[ r(\pi_k, d_{\pi_k}) = 1 - \frac{(E^{\theta|X}[\theta^{-1}])^2}{E^{\theta|X}[\theta^{-2}]} = 1 - \frac{n + \alpha_k}{n + \alpha_k + 1} = \frac{1}{n + \alpha_k + 1} \]
Taking the limit as the prior parameters approach zero (\(\alpha_k \to 0\)):
\[ \lim_{k \to \infty} r(\pi_k, d_{\pi_k}) = \frac{1}{n+1} \]
Minimax Verification
We compute the frequentist risk of our candidate estimator \(d_0(X) = \frac{T}{n+1}\). Let \(Y = T/\theta \sim \text{Gamma}(n, 1)\). Note that \(E^{X|\theta}[Y]=n\) and \(\text{Var}^{X|\theta}(Y)=n\).
\[ \begin{aligned} R(\theta, d_0) &= E^{X|\theta} \left[ \left( \frac{d_0}{\theta} - 1 \right)^2 \right] = E^{X|\theta} \left[ \left( \frac{Y}{n+1} - 1 \right)^2 \right] \\ &= \text{Var}^{X|\theta}\left(\frac{Y}{n+1}\right) + \left(E^{X|\theta}\left[\frac{Y}{n+1}\right]-1\right)^2 \\ &= \frac{n}{(n+1)^2} + \left( \frac{n}{n+1} - 1 \right)^2 \\ &= \frac{1}{n+1} \end{aligned} \]
Since \(R(\theta, d_0) = \lim_{k \to \infty} r(\pi_k, d_{\pi_k}) = \frac{1}{n+1}\) for all \(\theta\), \(d_0\) is a minimax estimator.
9.5 Stein’s Paradox and the James-stein Estimator
9.5.1 The Problem of Estimating Normal Mean
In high-dimensional estimation (\(p \ge 3\)), the Maximum Likelihood Estimator (MLE) is inadmissible under squared error loss. The James-Stein Estimator dominates the MLE, meaning it achieves lower risk for all values of \(\theta\).
Consider the setting:
- Data: \(X \sim N_p(\theta, I)\)
- Prior: \(\theta \sim N_p(0, \sigma^2 I)\)
- Jame-Stein Estimator:
\[d^{JS}(X) = \left( 1 - \frac{p-2}{||X||^2} \right) X\]
The James-Stein estimator improves upon the MLE by shrinking the individual observations toward a common mean (usually zero). The magnitude of this shrinkage depends on the total sum of squares of the observations.
- When the variance of \(\theta\) is large, \(||X||^2\) tends to be large, resulting in less shrinkage.
- When the variance of \(\theta\) is small, \(||X||^2\) is smaller, leading to a larger shrinkage factor.
The following R code simulates these two cases and displays them side-by-side with a shared y-axis for direct comparison.
Code
library(ggplot2)
library(patchwork)
library(tidyr)
library(dplyr)
library(latex2exp)
set.seed(42)
p <- 20
sigma1 <- 3
sigma2 <- 1
simulate_js <- function(sigma, p_dim) {
theta <- rnorm(p_dim, 0, sigma)
X <- theta + rnorm(p_dim, 0, 1)
sum_x_sq <- sum(X^2)
shrinkage_factor <- max(0, 1 - (p_dim - 2) / sum_x_sq)
js_est <- shrinkage_factor * X
data.frame(
i = 1:p_dim,
X_i = X,
JS_i = js_est
)
}
df_large <- simulate_js(sigma1, p)
df_small <- simulate_js(sigma2, p)
y_lims <- range(c(df_large$X_i, df_small$X_i))
create_plot <- function(df, title, y_limits) {
df_long <- df %>%
pivot_longer(cols = c(X_i, JS_i), names_to = "Est", values_to = "Value")
ggplot(df_long, aes(x = i, y = Value, color = Est, shape = Est)) +
geom_point(size = 3, alpha = 0.8) +
scale_color_manual(
values = c("X_i" = "tomato", "JS_i" = "blue"),
labels = unname(TeX(c("$\\hat{\\theta}_i^{JS}$", "$X_i$")))
) +
scale_shape_manual(
values = c("X_i" = 4, "JS_i" = 16),
labels = unname(TeX(c("$\\hat{\\theta}_i^{JS}$", "$X_i$")))
) +
ylim(y_limits) +
theme_minimal() +
labs(
title = title,
x = TeX("Index $i$"),
y = TeX("Value"),
color = "Estimator",
shape = "Estimator"
)
}
p1 <- create_plot(df_large, TeX("Large $\\sigma^2$ (Less Shrinkage)"), y_lims)
p2 <- create_plot(df_small, TeX("Small $\\sigma^2$ (More Shrinkage)"), y_lims)
# Combine with patchwork, collect guides at the bottom
p1 + p2 +
plot_layout(guides = "collect") &
theme(legend.position = "bottom")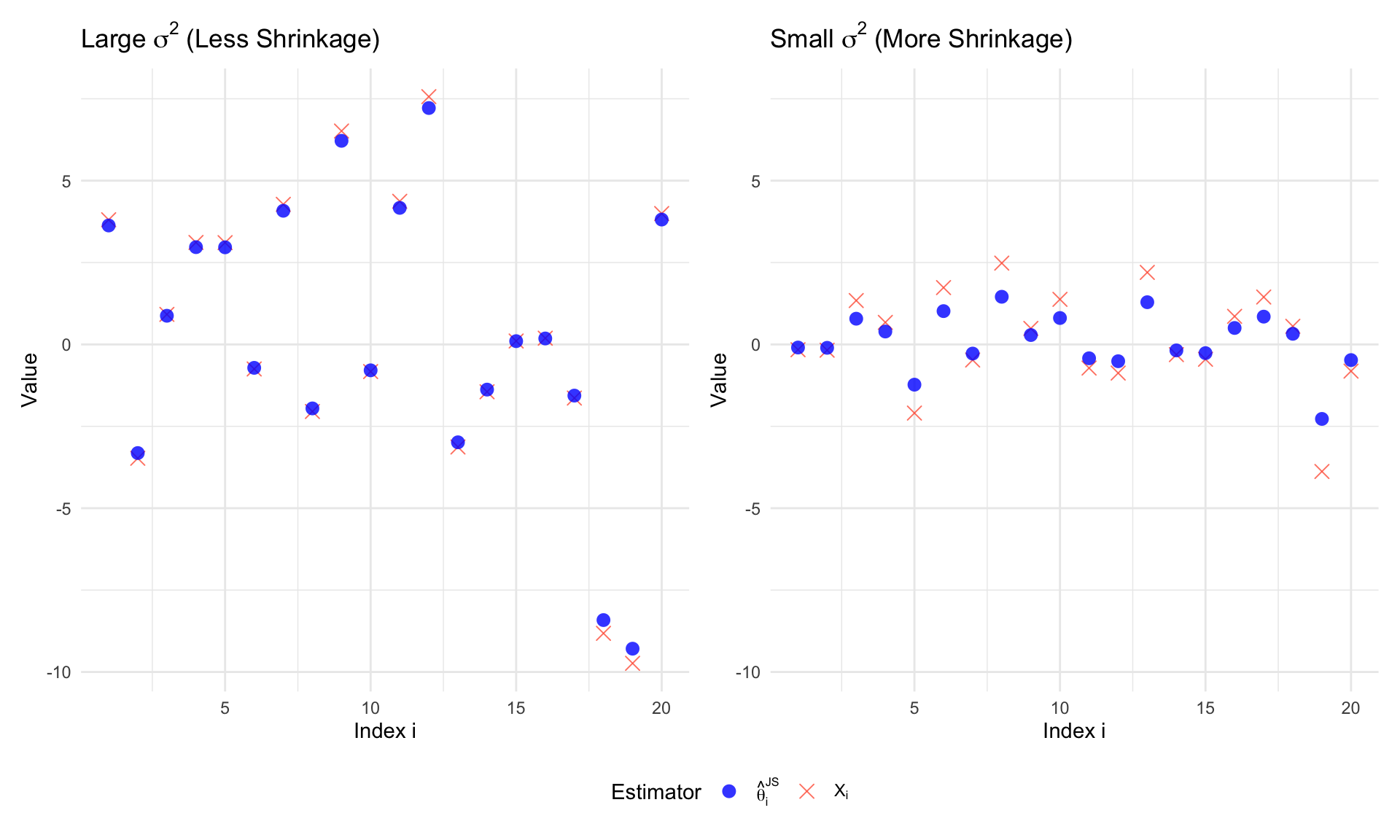
9.5.2 The Maximum Likelihood Estimator
Since the observations have the covariance matrix \(I\) (the identity matrix), the individual components \(X_1, \dots, X_p\) are independent, with \(X_i \sim N(\theta_i, 1)\).
The joint likelihood function is the product of the individual probability density functions:
\[ L(\theta; x) = \prod_{i=1}^p \frac{1}{\sqrt{2\pi}} \exp\left( -\frac{(X_i - \theta_i)^2}{2} \right) \]
To find the estimator, we maximize the log-likelihood function \(\ell(\theta)\):
\[ \begin{aligned} \ell(\theta) &= \ln \left( \prod_{i=1}^p \frac{1}{\sqrt{2\pi}} \exp\left( -\frac{(X_i - \theta_i)^2}{2} \right) \right) \\ &= \sum_{i=1}^p \left[ \ln\left(\frac{1}{\sqrt{2\pi}}\right) - \frac{(X_i - \theta_i)^2}{2} \right] \end{aligned} \]
Maximizing this sum is equivalent to minimizing the sum of squared errors \(\sum (X_i - \theta_i)^2\). We can solve for each component \(\theta_i\) separately. Differentiating with respect to \(\theta_i\):
\[ \frac{\partial \ell}{\partial \theta_i} = (X_i - \theta_i) \]
Setting the derivative to zero gives the critical point:
\[ X_i - \hat{\theta}_i = 0 \implies \hat{\theta}_{i, \text{MLE}} = X_i \]
Since this holds for every component \(i = 1, \dots, p\), the Maximum Likelihood Estimator for the entire vector is simply the observation vector itself:
\[ d^{\text{MLE}}(X) = X \]
9.5.3 A Bayes Rule
We first derive the Bayes rule with respect to a specific conjugate prior. Instead of using matrix notation, we can look at the problem component-wise, as the observations are independent.
Consider the model where we observe \(p\) independent components:
\[ X_i | \theta_i \sim N(\theta_i, 1), \quad \text{for } i = 1, \ldots, p \]
We place independent centered normal priors on each unknown parameter \(\theta_i\):
\[ \theta_i \sim N(0, \sigma^2), \quad \text{for } i = 1, \ldots, p \]
Since the components are independent, we can derive the Bayes rule for a single scalar component \(X_i\) estimating \(\theta_i\). The total risk will simply be the sum of the component risks.
For a single component, the posterior distribution of \(\theta_i\) given \(X_i\) is Normal, with parameters determined by the standard conjugate formulas:
Posterior Precision (inverse variance): The posterior precision is the sum of the prior precision and the data precision. \[ \frac{1}{v_{\text{post}}} = \frac{1}{\sigma^2} + \frac{1}{1} = \frac{1 + \sigma^2}{\sigma^2} \] Therefore, the posterior variance is: \[ v_{\text{post}} = \frac{\sigma^2}{1 + \sigma^2} \]
Posterior Mean (Bayes Estimator): The posterior mean is the precision-weighted average of the prior mean (0) and the data mean (\(X_i\)). \[ \begin{aligned} E^{\theta_i|X_i}[\theta_i] &= v_{\text{post}} \left( \frac{0}{\sigma^2} + \frac{X_i}{1} \right) \\ &= \frac{\sigma^2}{1 + \sigma^2} X_i \\ &= \left( 1 - \frac{1}{1 + \sigma^2} \right) X_i \end{aligned} \]
Since this holds for all \(i\), the Bayes rule for the vector \(\theta\) is applying this shrinkage factor to each component:
\[ d^{\text{Bayes}}(X) = \left( 1 - \frac{1}{1 + \sigma^2} \right) X \]
9.5.3.1 Bayes Risk of the Bayes Rule
To compute the Bayes risk, we sum the risks of the individual components. For squared error loss, the posterior expected loss for one component is simply the posterior variance derived above:
\[ E^{\theta_i|X_i} [ (\theta_i - d^{\text{Bayes}}(X_i))^2 ] = v_{\text{post}} = \frac{\sigma^2}{1 + \sigma^2} \]
The total Bayes risk is the sum of these variances over \(p\) components:
\[ r(\pi, d^{\text{Bayes}}) = \sum_{i=1}^p \frac{\sigma^2}{1 + \sigma^2} = \frac{p\sigma^2}{1 + \sigma^2} \]
9.5.3.2 Minimaxity of the MLE
The James-Stein result is particularly striking when compared to the performance of the standard estimator.
Theorem 9.2 (Minimaxity of the Maximum Likelihood Estimator) Let \(X \sim N_p(\theta, I)\). Under the squared error loss function \(\mathcal{L}(\theta, d) = ||\theta - d||^2\), the standard Maximum Likelihood Estimator \(d^0(X) = X\) is a minimax rule. That is, it minimizes the maximum possible risk over the parameter space:
\[ \sup_{\theta \in \mathbb{R}^p} R(\theta, d^0) = \inf_{d} \sup_{\theta \in \mathbb{R}^p} R(\theta, d) = p \]
Proof.
Click to view proof by least favorable prior
The risk of the MLE is \(R(\theta, d^0) = p\) for all \(\theta\). Since it is a constant risk estimator, its maximum risk is simply \(p\).
To prove it is minimax, we show that \(p\) is the limit of the Bayes risks for a sequence of conjugate priors \(\theta_i \sim N(0, \sigma^2)\). As derived above, the Bayes risk for the optimal Bayes estimator \(d^{\text{Bayes}}\) is:
\[ r(\pi_{\sigma^2}, d^{\text{Bayes}}) = \frac{p\sigma^2}{1 + \sigma^2} \]
As \(\sigma^2 \to \infty\) (the prior becomes “flat”), the Bayes risk approaches \(p\):
\[ \lim_{\sigma^2 \to \infty} \frac{p\sigma^2}{1 + \sigma^2} = p \]
By the property that the maximum risk of an estimator is always at least the Bayes risk of any prior, and specifically greater than or equal to the limit of Bayes risks for a sequence of priors, we establish that no estimator can have a maximum risk lower than \(p\). Since \(d^0\) achieves this maximum risk, it is minimax.
9.5.4 Stein’s Lemma
Notation: The Divergence Operator
The symbol \(\nabla \cdot g(X)\) (read as “divergence of \(g\)”) is simply a shorthand notation for the sum of the partial derivatives:
\[ \nabla \cdot g(X) \equiv \sum_{i=1}^p \frac{\partial g_i(X)}{\partial X_i} \]
It represents the total “outward flow” of the vector field \(g\) from a local point.
Lemma 9.1 (Stein’s Lemma) Let \(X \sim N_p(\theta, I)\) be a multivariate normal random vector, and let \(g: \mathbb{R}^p \to \mathbb{R}^p\) be a continuously differentiable function such that \(E^{X|\theta}[| \partial g_i / \partial X_i |] < \infty\). Then:
\[ E^{X|\theta} \left[ (X - \theta)^T g(X) \right] = E^{X|\theta} \left[ \nabla \cdot g(X) \right] = E^{X|\theta} \left[ \sum_{i=1}^p \frac{\partial g_i(X)}{\partial X_i} \right] \]
The term \(\nabla \cdot g(X)\) represents the divergence of the vector field \(g\), which intuitively measures the local rate of expansion or outward flux of the function \(g\) at the point \(X\); in this statistical context, it quantifies the aggregate sensitivity of the function components to changes in the data.
Proof.
It suffices to show the result for a single component in 1 dimension, as the multivariate case follows by summation due to independence. Let \(X_i \sim N(\theta_i, 1)\) and let \(\phi(t)\) be the standard normal density function. The joint density is \(f(x) = \prod \phi(x_j - \theta_j)\).
Consider the expectation of the \(i\)-th term: \[ E^{X|\theta} [ (X_i - \theta_i) g_i(X) ] = \int_{\mathbb{R}^p} (x_i - \theta_i) g_i(x) \left( \prod_{j=1}^p \phi(x_j - \theta_j) \right) dx \]
Focusing on the integral with respect to \(x_i\): \[ \int_{-\infty}^{\infty} (x_i - \theta_i) \phi(x_i - \theta_i) g_i(x) dx_i \]
Recall that \(\phi'(z) = -z \phi(z)\). Therefore, \((x_i - \theta_i) \phi(x_i - \theta_i) = - \frac{\partial}{\partial x_i} \phi(x_i - \theta_i)\). We use integration by parts with: \[ u = g_i(x) \quad \text{and} \quad dv = - \frac{\partial}{\partial x_i} \phi(x_i - \theta_i) dx_i \]
Thus: \[ \int_{-\infty}^{\infty} g_i(x) (x_i - \theta_i) \phi(x_i - \theta_i) dx_i = \left[ -g_i(x) \phi(x_i - \theta_i) \right]_{-\infty}^{\infty} + \int_{-\infty}^{\infty} \frac{\partial g_i(x)}{\partial x_i} \phi(x_i - \theta_i) dx_i \]
Assuming \(g(x)\) does not grow exponentially fast, the boundary term vanishes. The remaining integral is the expectation of the partial derivative. Summing over all \(i=1 \dots p\) gives the divergence \(\nabla \cdot g(X)\).In high-dimensional statistics, Stein’s Lemma is often expressed using the inner product of the random vector and the function vector field, which highlights the alignment between the data and the transformation.
Corollary 9.1 (Stein’s Lemma (Vector Form)) Let \(X \sim N_p(\theta, I)\) and \(g: \mathbb{R}^p \to \mathbb{R}^p\) be a weakly differentiable function. Then:
\[ E^{X|\theta} [ X^T g(X) ] = \theta^T E^{X|\theta} [ g(X) ] + E^{X|\theta} [ \nabla \cdot g(X) ] \]
Remark: Connection to Non-Central \(\chi^2\) Moments
This identity provides an elegant way to derive the mean of a non-central chi-square distribution without performing complex integration.
Consider the case where \(g(X) = X\). Here, \(\nabla \cdot X = p\). Plugging this into the vector form:
\[ E^{X|\theta} [ X^T X ] = \theta^T E^{X|\theta} [ X ] + E^{X|\theta} [ p ] \]
Since \(E^{X|\theta} [ X ] = \theta\), we immediately obtain:
\[ E^{X|\theta} [ \lVert X \rVert^2 ] = \lVert \theta \rVert^2 + p \]
This is precisely the mean of a \(\chi^2_p(\lambda)\) distribution with non-centrality parameter \(\lambda = \lVert \theta \rVert^2\). Essentially, Stein’s Lemma decomposes the second moment into the signal component (\(\lVert \theta \rVert^2\)) and the geometric noise component (\(p\)).
Lemma 9.2 (Stein’s Lemma for Radial Fields) Let \(X \sim N_p(\theta, I)\) and consider a radial vector field of the form \(g(X) = c(\lVert X \rVert^2)X\), where \(c: \mathbb{R} \to \mathbb{R}\) is a differentiable scalar function. Then:
\[ E^{X|\theta} \left[ (X - \theta)^T g(X) \right] = E^{X|\theta} \left[ p \cdot c(\lVert X \rVert^2) + 2 \lVert X \rVert^2 \cdot c'(\lVert X \rVert^2) \right] \]
where \(c'(z) = \frac{d}{dz}c(z)\).
Proof.
We apply the general Stein’s Lemma by calculating the divergence of the radial field \(g(X) = c(\lVert X \rVert^2)X\). Using the product rule for divergence:
\[ \nabla \cdot (c(\lVert X \rVert^2)X) = c(\lVert X \rVert^2) (\nabla \cdot X) + X^T (\nabla c(\lVert X \rVert^2)) \]
Step 1: The geometric spread. The divergence of the identity map \(X\) in \(p\) dimensions is simply the sum of the partial derivatives of each component with respect to itself: \[ \nabla \cdot X = \sum_{i=1}^p \frac{\partial X_i}{\partial X_i} = p \]
Step 2: The radial stretch. To find \(\nabla c(\lVert X \rVert^2)\), we use the chain rule. Let \(h(X) = \lVert X \rVert^2 = \sum X_i^2\). Then \(\nabla h(X) = 2X\). \[ \nabla c(\lVert X \rVert^2) = c'(\lVert X \rVert^2) \nabla (\lVert X \rVert^2) = 2 c'(\lVert X \rVert^2) X \]
Substituting this back into the divergence formula: \[ \begin{aligned} \nabla \cdot g(X) &= p \cdot c(\lVert X \rVert^2) + X^T (2 c'(\lVert X \rVert^2) X) \\ &= p \cdot c(\lVert X \rVert^2) + 2 c'(\lVert X \rVert^2) \lVert X \rVert^2 \end{aligned} \]
Taking the expectation of both sides completes the proof.
Connection to the \(\chi^2\) Distribution
This version of the lemma is particularly useful because when \(\theta = 0\), the quantity \(\lVert X \rVert^2\) follows a central \(\chi^2_p\) distribution.
- Verifying the Mean: If we set \(c(\lVert X \rVert^2) = 1\), then \(g(X) = X\). The lemma gives \(E^{X|\theta=0}[\lVert X \rVert^2] = p + 2\lVert X \rVert^2(0) = p\), which is the expected value of a \(\chi^2_p\) variable.
- The James-Stein Weight: If we set \(c(\lVert X \rVert^2) = \frac{1}{\lVert X \rVert^2}\), then \(c'(z) = -\frac{1}{z^2}\). \[ \nabla \cdot g(X) = \frac{p}{\lVert X \rVert^2} + 2 \lVert X \rVert^2 \left( -\frac{1}{\lVert X \rVert^4} \right) = \frac{p-2}{\lVert X \rVert^2} \] This explains why the \(p-2\) constant appears in the James-Stein estimator—it is the net result of \(p\) dimensions of “spreading” minus 2 dimensions of “radial thinning.”
Example 9.7 (An Example for Verifying Stein’s Lemma) Let \(X \sim N(\theta, 1)\) be a univariate normal random variable with unit variance. Let \(g(x) = x^2\). Stein’s Lemma states that: \[ E^{X|\theta} \left[ (X-\theta) g(X) \right] = E^{X|\theta} \left[ g'(X) \right] \]
Step 1: Calculate the Right-Hand Side (RHS) First, we find the derivative of \(g(x)\): \[ g'(x) = \frac{d}{dx} (x^2) = 2x \]
Now, compute the expectation of the derivative: \[ \text{RHS} = E^{X|\theta} [g'(X)] = E^{X|\theta} [2X] = 2 E^{X|\theta} [X] = 2\theta \]
Step 2: Calculate the Left-Hand Side (LHS) We evaluate the expectation of the cross-product term. Substitute \(X = Z + \theta\), where \(Z \sim N(0, 1)\) is a standard normal variable. Then \(X - \theta = Z\).
\[ \begin{aligned} \text{LHS} &= E^{X|\theta} \left[ (X-\theta) X^2 \right] \\ &= E^{X|\theta} \left[ Z (Z + \theta)^2 \right] \quad \text{where } Z \sim N(0,1) \\ &= E^{X|\theta} \left[ Z (Z^2 + 2\theta Z + \theta^2) \right] \\ &= E^{X|\theta} [Z^3] + 2\theta E^{X|\theta} [Z^2] + \theta^2 E^{X|\theta} [Z] \end{aligned} \]
We use the known moments of the standard normal distribution \(Z\):
- \(E[Z] = 0\) (mean)
- \(E[Z^2] = 1\) (variance)
- \(E[Z^3] = 0\) (skewness of symmetric distribution)
Substituting these values back: \[ \text{LHS} = 0 + 2\theta(1) + \theta^2(0) = 2\theta \]
Conclusion We observe that: \[ \text{LHS} = 2\theta \quad \text{and} \quad \text{RHS} = 2\theta \] Thus, Stein’s Lemma holds for this specific case.
Example 9.8 (A Radial Field Example Verifying Stein’s Lemma) Let \(X \sim N_p(\theta, I)\) and \(g(X) = \lVert X \rVert^2 X\). We verify the Radial Field Lemma: \[E^{X|\theta} \left[ (X - \theta)^T g(X) \right] = E^{X|\theta} \left[ p \cdot c(\lVert X \rVert^2) + 2 \lVert X \rVert^2 \cdot c'(\lVert X \rVert^2) \right]\]
Here, \(c(z) = z\), which implies \(c'(z) = 1\).
RHS (Divergence): Using the radial formula: \[ \begin{aligned} \nabla \cdot g(X) &= p(\lVert X \rVert^2) + 2\lVert X \rVert^2(1) \\ &= (p+2)\lVert X \rVert^2 \end{aligned} \] The expectation is \((p+2)E^{X|\theta}[\lVert X \rVert^2]\). Since \(\lVert X \rVert^2\) is a non-central \(\chi^2_p\) with non-centrality parameter \(\lVert \theta \rVert^2\), we know \(E^{X|\theta}[\lVert X \rVert^2] = p + \lVert \theta \rVert^2\). Thus, \(\text{RHS} = (p+2)(p + \lVert \theta \rVert^2)\).
LHS (Alignment): \[ \begin{aligned} E^{X|\theta} \left[ (X-\theta)^T (\lVert X \rVert^2 X) \right] &= E^{X|\theta} \left[ \lVert X \rVert^2 (X^T X - \theta^T X) \right] \\ &= E^{X|\theta} \left[ \lVert X \rVert^4 - \theta^T X \lVert X \rVert^2 \right] \end{aligned} \]
To simplify, let \(X = \theta + Z\) where \(Z \sim N_p(0, I)\). Recall the moments of the non-central chi-square distribution or expand the terms: \(E[\lVert X \rVert^4] = p(p+2) + 2(p+2)\lVert \theta \rVert^2 + \lVert \theta \rVert^4\). For the cross term \(E[\theta^T X \lVert X \rVert^2]\), we find it equals \(\lVert \theta \rVert^4 + (p+2)\lVert \theta \rVert^2\).
Subtracting these: \[ \begin{aligned} \text{LHS} &= [p(p+2) + 2(p+2)\lVert \theta \rVert^2 + \lVert \theta \rVert^4] - [\lVert \theta \rVert^4 + (p+2)\lVert \theta \rVert^2] \\ &= p(p+2) + (p+2)\lVert \theta \rVert^2 \\ &= (p+2)(p + \lVert \theta \rVert^2) \end{aligned} \]
Conclusion
The results match exactly. The alignment of the cubic radial field with the noise is perfectly predicted by the sum of its geometric expansion (\(p \lVert X \rVert^2\)) and its radial stretch (\(2 \lVert X \rVert^2\)).
9.5.5 Inadmissibility of the MLE in High Dimensions (Stein’s Phenomenon)
Theorem 9.3 Let \(X \sim N_p(\theta, I)\) be a \(p\)-dimensional random vector with \(p \ge 3\). Under the squared error loss function \(\mathcal{L}(\theta, d) = ||\theta - d||^2\), the standard Maximum Likelihood Estimator \(d^0(X) = X\) is inadmissible.
Proof (Proof of Inadmissibility). To show that \(d^0(X) = X\) is inadmissible, we compare its risk to that of the James-Stein estimator \(d^{JS}(X)\).
Let \(g(X) = c(\lVert X \rVert^2)X\) where \(c(\lVert X \rVert^2) = \frac{p-2}{\lVert X \rVert^2}\). We can write the James-Stein estimator as \(d^{JS}(X) = X - g(X)\).
The risk is the expected squared error loss:
\[ \begin{aligned} R(\theta, d^{JS}) &= E^{X|\theta} \left[ || (X - \theta) - g(X) ||^2 \right] \\ &= E^{X|\theta} \left[ ||X - \theta||^2 \right] - 2 E^{X|\theta} \left[ (X-\theta)^T g(X) \right] + E^{X|\theta} \left[ ||g(X)||^2 \right] \end{aligned} \]
The first term is the risk of the MLE, which is \(p\).
For the second term, we apply Stein’s Lemma for Radial Fields (Lemma 9.2). We first compute the scalar function and its derivative: \[c(z) = \frac{p-2}{z} \implies c'(z) = -\frac{p-2}{z^2}\]
Substituting these into the radial divergence formula from Lemma 9.2: \[ \begin{aligned} \nabla \cdot g(X) &= p \cdot c(\lVert X \rVert^2) + 2 \lVert X \rVert^2 \cdot c'(\lVert X \rVert^2) \\ &= p \left( \frac{p-2}{\lVert X \rVert^2} \right) + 2 \lVert X \rVert^2 \left( -\frac{p-2}{\lVert X \rVert^4} \right) \\ &= \frac{p(p-2)}{\lVert X \rVert^2} - \frac{2(p-2)}{\lVert X \rVert^2} \\ &= \frac{(p-2)^2}{\lVert X \rVert^2} \end{aligned} \]
Applying the lemma to the cross-term: \[2 E^{X|\theta} \left[ (X-\theta)^T g(X) \right] = 2 E^{X|\theta} [ \nabla \cdot g(X) ] = 2(p-2)^2 E^{X|\theta} \left[ \frac{1}{\lVert X \rVert^2} \right]\]
The third term in the risk expansion is the squared magnitude of the shrinkage: \[\lVert g(X) \rVert^2 = \left\lVert \frac{p-2}{ \lVert X \rVert ^2} X \right \rVert^2 = \frac{(p-2)^2}{\lVert X \rVert^4} \lVert X \rVert^2 = \frac{(p-2)^2}{\lVert X \rVert^2}\]
Substituting these results back into the risk equation: \[ \begin{aligned} R(\theta, d^{JS}) &= p - 2(p-2)^2 E^{X|\theta} \left[ \frac{1}{\lVert X \rVert^2} \right] + (p-2)^2 E^{X|\theta} \left[ \frac{1}{\lVert X \rVert^2} \right] \\ &= p - (p-2)^2 E^{X|\theta} \left[ \frac{1}{\lVert X \rVert^2} \right] \end{aligned} \]
Since \(p \ge 3\), the constant \((p-2)^2\) is strictly positive. Because \(1/\lVert X \rVert^2 > 0\) with probability 1, the risk of the James-Stein estimator is strictly less than \(p\) for all \(\theta \in \mathbb{R}^p\).
Thus, \(d^{JS}\) dominates the MLE, proving the MLE is inadmissible.
9.5.6 How much JS Estimator Improves over MLE
The exact risk function of the James-Stein estimator \(d^{JS}(X)\) under squared error loss for \(X \sim N_p(\theta, I)\) is given by:
\[R(\theta, d^{JS}) = p - (p-2)^2 E \left[ \frac{1}{\chi_p^2(\|\theta\|^2/2)} \right]\]
where \(\chi_p^2(\|\theta\|^2/2)\) is a non-central chi-square random variable with \(p\) degrees of freedom and non-centrality parameter \(\lambda = \|\theta\|^2/2\).
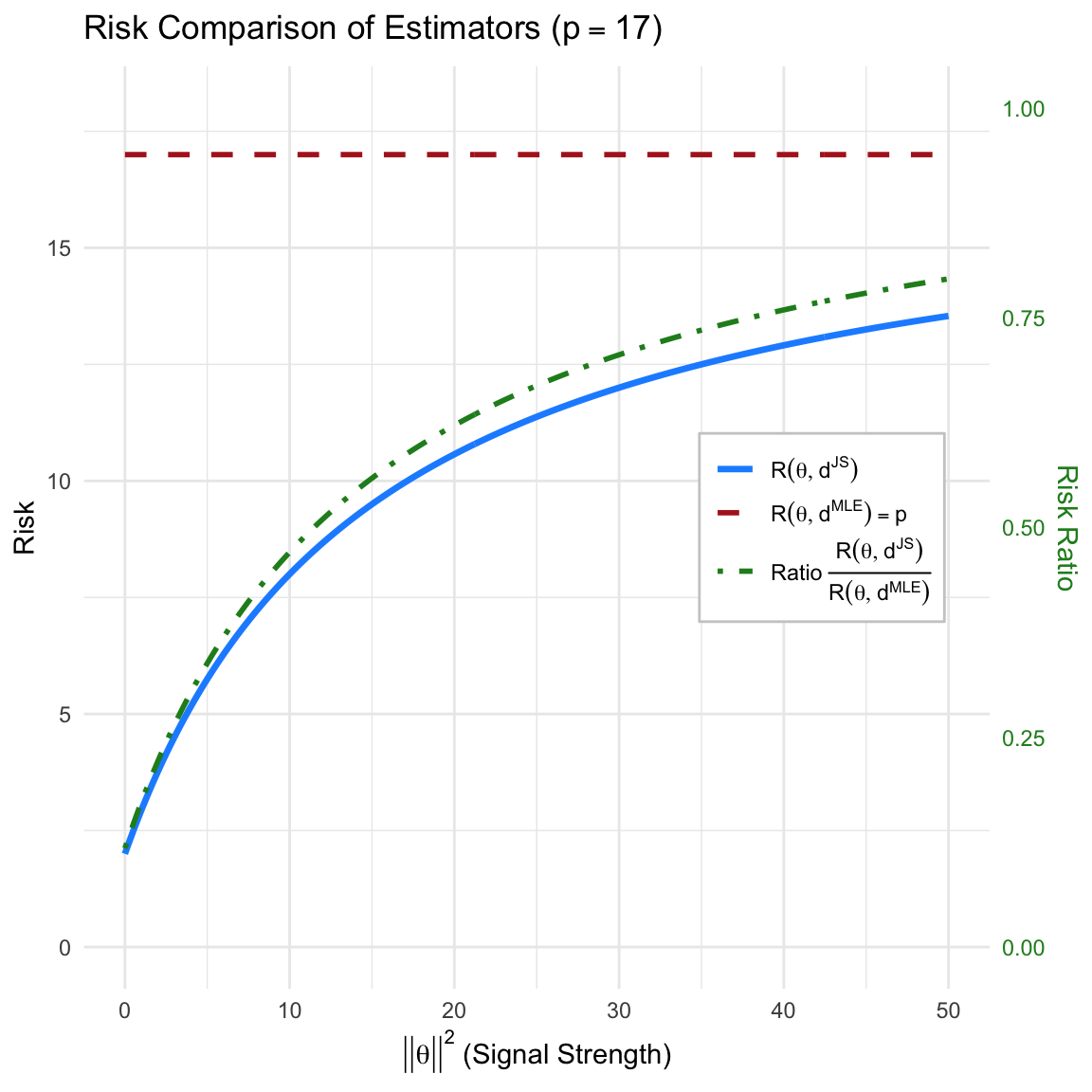
Using the approximation \(E[1/\chi_p^2(\lambda)] \approx 1/E[\chi_p^2(\lambda)] = 1/(p + \|\theta\|^2)\), we can see the approximate behavior of the risk:
\[R(\theta, d^{JS}) \approx p - \frac{(p-2)^2}{p + \|\theta\|^2}\]
Aggressive Shrinkage near the Origin: When \(\|\theta\|^2\) is small, the denominator \(p + \|\theta\|^2\) is small, making the subtracted term large. This results in a risk substantially lower than the MLE risk of \(p\).
Diminishing Improvement with Large Signal: As \(\|\theta\|^2\) becomes large, the term \(\frac{(p-2)^2}{p + \|\theta\|^2}\) approaches zero. Consequently, the risk of the James-Stein estimator approaches \(p\), and the improvement over the MLE becomes negligible.
Risk Ratio near the Origin: As the true parameter vector shrinks to zero (\(\|\theta\| \to 0\)), the ratio of the risks converges to a constant fraction. Using the exact expectation \(E^{X|\theta=0}[1/\|X\|^2] = 1/(p-2)\):
\[ \lim_{\|\theta\| \to 0} \frac{R(\theta, d^{JS})}{R(\theta, d^{\text{MLE}})} = \frac{p - (p-2)^2 \left( \frac{1}{p-2} \right)}{p} = \frac{p - (p-2)}{p} = \frac{2}{p} \]
For a dimension like \(p=10\), the James-Stein estimator incurs only \(20\%\) of the risk of the MLE near the origin.
Is \(d^{JS}\) Minimax?
Yes. Since the MLE is minimax with constant risk \(p\), the minimax risk value for this problem is \(p\).
Because \(R(\theta, d^{JS}) < p\) for all \(\theta\) and \(\lim_{\lVert \theta \rVert \to \infty} R(\theta, d^{JS}) = p\), the maximum risk of the James-Stein estimator is exactly \(p\). Therefore, \(d^{JS}\) achieves the minimax risk level and is a minimax estimator.
Code
library(ggplot2)
library(latex2exp)
# Parameters
p <- 17
theta_sq <- seq(0, 50, length.out = 300)
# Create Data Frame
df <- data.frame(
theta_sq = theta_sq,
risk_mle = p,
risk_js = p - (p - 2)^2 / (p - 2 + theta_sq)
)
# Calculate Ratio
df$ratio <- df$risk_js / p
# --- FIX: ADJUST SCALING FACTOR ---
# We scale the Ratio so 1.0 sits at y = 12 (top of plot),
# rather than y = 10, to separate it from the Risk curve.
y_max_limit <- p+1
scale_factor <- y_max_limit
# Define Legend Labels
labels_map <- c(
"MLE" = TeX(r'($R(\theta, d^{MLE}) = p$)'),
"JS" = TeX(r'($R(\theta, d^{JS})$)'),
"Ratio" = TeX(r'(Ratio $\frac{R(\theta, d^{JS})}{R(\theta, d^{MLE})}$)')
)
ggplot(df, aes(x = theta_sq)) +
# 1. MLE Risk Line (Red Dashed)
geom_line(aes(y = risk_mle, color = "MLE", linetype = "MLE"), size = 1) +
# 2. JS Risk Line (Blue Solid)
geom_line(aes(y = risk_js, color = "JS", linetype = "JS"), size = 1.2) +
# 3. Ratio Line (Green Dot-Dash)
# We scale it up to occupy the full plot height
geom_line(aes(y = ratio * scale_factor, color = "Ratio", linetype = "Ratio"), size = 1) +
# Axes Configuration
scale_y_continuous(
name = "Risk",
limits = c(0, y_max_limit),
# Secondary Axis: Divide back by the NEW scale factor
sec.axis = sec_axis(~ . / scale_factor, name = "Risk Ratio")
) +
# Manual Colors and Linetypes
scale_color_manual(
name = NULL,
values = c("MLE" = "firebrick", "JS" = "dodgerblue", "Ratio" = "forestgreen"),
labels = labels_map
) +
scale_linetype_manual(
name = NULL,
values = c("MLE" = "dashed", "JS" = "solid", "Ratio" = "dotdash"),
labels = labels_map
) +
# Theming
labs(
title = TeX(sprintf(r'(Risk Comparison of Estimators ($p=%d$))', p)),
x = TeX(r'($|| \theta ||^2$ (Signal Strength))')
) +
theme_minimal() +
theme(
legend.position = c(0.95, 0.5),
legend.justification = c(1, 0.5),
legend.background = element_rect(fill = "white", color = "gray80"),
axis.title.y.right = element_text(color = "forestgreen"),
axis.text.y.right = element_text(color = "forestgreen")
)
9.5.7 Using Normalized Loss (Optional)
We consider the Normalized Squared Error Loss function, which penalizes errors relative to the magnitude of the true parameter vector: \[ \mathcal{L}(\theta, d) = \frac{\lVert d - \theta \rVert^2}{\lVert \theta \rVert^2}, \quad \theta \neq 0 \]
- Risk of the MLE (\(d^{\text{MLE}} = X\))
The risk of the Maximum Likelihood Estimator is straightforward because the standard Mean Squared Error (MSE) of \(X\) is constant (\(p\)): \[ R(\theta, d^{\text{MLE}}) = E^{X|\theta} \left[ \frac{\lVert X - \theta \rVert^2}{\lVert \theta \rVert^2} \right] = \frac{1}{\lVert \theta \rVert^2} E^{X|\theta} \left[ \lVert X - \theta \rVert^2 \right] \] Since \(X \sim N_p(\theta, I)\), we have \(E^{X|\theta}[\lVert X - \theta \rVert^2] = p\). \[ R(\theta, d^{\text{MLE}}) = \frac{p}{\lVert \theta \rVert^2} \]
- Risk of the James-Stein Estimator (\(d^{JS}\))
For the James-Stein estimator \(d^{JS} = \left( 1 - \frac{p-2}{\lVert X \rVert^2} \right)X\), we utilize the known result for its standard MSE risk: \[ E^{X|\theta} [\lVert d^{JS} - \theta \rVert^2] = p - (p-2)^2 E^{X|\theta} \left[ \frac{1}{\lVert X \rVert^2} \right] \] The risk under the normalized loss is simply this term scaled by \(1/\lVert \theta \rVert^2\): \[ R(\theta, d^{JS}) = \frac{1}{\lVert \theta \rVert^2} \left( p - (p-2)^2 E^{X|\theta} \left[ \frac{1}{\lVert X \rVert^2} \right] \right) \]
- Comparison and Dominance
We compare the risks by taking the difference: \[ R(\theta, d^{\text{MLE}}) - R(\theta, d^{JS}) = \frac{1}{\lVert \theta \rVert^2} (p-2)^2 E^{X|\theta} \left[ \frac{1}{\lVert X \rVert^2} \right] \] Since \((p-2)^2 > 0\) (for \(p \ge 3\)) and the expectation of a positive random variable is positive, this difference is strictly positive for all \(\theta \neq 0\). \[ R(\theta, d^{JS}) < R(\theta, d^{\text{MLE}}) \]
Global Dominance: The James-Stein estimator dominates the MLE under this loss function as well, achieving lower risk everywhere in the parameter space.
- Behavior near \(\theta \approx 0\): As \(\lVert \theta \rVert \to 0\), both risks diverge to infinity. We analyze their relative performance by examining the ratio of the risks:
\[ \frac{R(\theta, d^{JS})}{R(\theta, d^{\text{MLE}})} = \frac{p - (p-2)^2 E^{X|\theta} [1/\lVert X \rVert^2]}{p} = 1 - \frac{(p-2)^2}{p} E^{X|\theta} \left[ \frac{1}{\lVert X \rVert^2} \right] \]
At \(\theta = 0\), \(\lVert X \rVert^2 \sim \chi^2_p\), and the expectation is \(E^{X|\theta=0}[1/\lVert X \rVert^2] = 1/(p-2)\). Substituting this into the ratio:
\[ \lim_{\lVert \theta \rVert \to 0} \frac{R(\theta, d^{JS})}{R(\theta, d^{\text{MLE}})} = 1 - \frac{(p-2)^2}{p(p-2)} = 1 - \frac{p-2}{p} = \frac{2}{p} \]
Thus, near the origin, the James-Stein estimator reduces the risk by a factor of \(p/2\). For large dimensions (e.g., \(p=10\)), the JS estimator has only \(20\%\) of the risk of the MLE.
9.5.8 Bayes Risk of James-stein Estimator (Optional)
We can derive the Bayes Risk \(r(\pi, d^{JS})\) of this estimator using two equivalent methods: minimizing the expected frequentist risk, or minimizing the expected posterior loss.
Theorem 9.4 (Bayes Risk of James-stein Estimator) For \(p \ge 3\), the Bayes risk of the James-Stein estimator \(d^{JS}\) with respect to the prior \(\theta \sim N(0, \sigma^2 I)\) is:
\[ r(\pi, d^{JS}) = \frac{p\sigma^2 + 2}{\sigma^2 + 1} \]
Proof.
Method 1: Integration over the Prior (Frequentist Risk approach)
The Bayes risk is defined as \(r(\pi, d) = E^\pi [ R(\theta, d) ]\).
First, recall the frequentist risk of the James-Stein estimator for a fixed \(\theta\). Using Stein’s Lemma, the risk is given by:
\[ R(\theta, d^{JS}) = p - (p-2)^2 E^{X|\theta} \left[ \frac{1}{||X||^2} \right] \]
To find the Bayes risk, we take the expectation of this risk with respect to the prior \(\pi(\theta)\):
\[ r(\pi, d^{JS}) = \int R(\theta, d^{JS}) \pi(\theta) d\theta = p - (p-2)^2 E^\pi \left[ E^{X|\theta} \left( \frac{1}{||X||^2} \right) \right] \]
By the law of iterated expectations, \(E^\pi [ E^{X|\theta} (\cdot) ]\) is equivalent to the expectation with respect to the marginal distribution of \(X\), denoted as \(m(x)\). Under the conjugate prior, the marginal distribution is \(X \sim N(0, (1+\sigma^2)I)\).
Consequently, the quantity \(\frac{||X||^2}{1+\sigma^2}\) follows a Chi-squared distribution with \(p\) degrees of freedom (\(\chi^2_p\)). The expectation of the inverse chi-square is:
\[ E^X \left[ \frac{1}{||X||^2} \right] = \frac{1}{1+\sigma^2} E \left[ \frac{1}{\chi^2_p} \right] = \frac{1}{1+\sigma^2} \cdot \frac{1}{p-2} \]
Substituting this back into the risk equation:
\[ \begin{aligned} r(\pi, d^{JS}) &= p - (p-2)^2 \cdot \frac{1}{(p-2)(1+\sigma^2)} \\ &= p - \frac{p-2}{1+\sigma^2} \\ &= \frac{p(1+\sigma^2) - (p-2)}{1+\sigma^2} \\ &= \frac{p\sigma^2 + p - p + 2}{1+\sigma^2} = \frac{p\sigma^2 + 2}{\sigma^2 + 1} \end{aligned} \]
Proof.
Method 2: Integration over the Marginal (Posterior Loss approach)
Alternatively, we can compute the Bayes risk by first finding the posterior expected loss for a given \(x\), and then averaging over the marginal distribution of \(x\):
\[ r(\pi, d) = E^X [ E^{\theta|X} [ \mathcal{L}(\theta, d(X)) ] ] \]
Step 1: Posterior Expected Loss
The posterior distribution of \(\theta\) given \(x\) is:
\[ \theta | x \sim N \left( \frac{\sigma^2}{1+\sigma^2}x, \frac{\sigma^2}{1+\sigma^2}I \right) \]
The expected squared error loss can be decomposed into the variance (trace) and the squared bias:
\[ E^{\theta|X} [ ||\theta - d^{JS}(X)||^2 ] = \text{tr}(\text{Var}^{\theta|X}(\theta)) + || E^{\theta|X}[\theta] - d^{JS}(X) ||^2 \]
Trace term: \[\text{tr} \left( \frac{\sigma^2}{1+\sigma^2} I_p \right) = \frac{p\sigma^2}{1+\sigma^2}\]
Squared Bias term: Let \(B = \frac{1}{1+\sigma^2}\). Then \(E^{\theta|X}[\theta] = (1-B)X\). The estimator is \(d^{JS}(X) = (1 - \frac{p-2}{||X||^2})X\). The difference is:
\[ E^{\theta|X}[\theta] - d^{JS}(X) = \left( (1-B) - \left( 1 - \frac{p-2}{||X||^2} \right) \right) X = \left( \frac{p-2}{||X||^2} - B \right) X \]
Squaring the norm gives:
\[ \left( \frac{p-2}{||X||^2} - B \right)^2 ||X||^2 = \frac{(p-2)^2}{||X||^2} - 2B(p-2) + B^2 ||X||^2 \]
Step 2: Expectation with respect to Marginal \(X\)
We now take the expectation \(E^X[\cdot]\) of the posterior loss. Recall \(X \sim N(0, (1+\sigma^2)I)\), so \(E^X[||X||^2] = p(1+\sigma^2)\) and \(E^X[1/||X||^2] = \frac{1}{(p-2)(1+\sigma^2)}\).
- Expectation of Trace term: Constant, remains \(\frac{p\sigma^2}{1+\sigma^2}\).
- Expectation of Bias term:
Step 3: Combine Terms
\[ r(\pi, d^{JS}) = \underbrace{\frac{p\sigma^2}{1+\sigma^2}}_{\text{Variance Part}} + \underbrace{\frac{2}{1+\sigma^2}}_{\text{Bias Part}} = \frac{p\sigma^2 + 2}{\sigma^2 + 1} \]
Both methods yield the same result.
9.5.9 Practical Application: One-way ANOVA and “Borrowing Strength”
Example 9.9 Consider a One-Way ANOVA setting where we wish to estimate the means of \(p\) different independent groups (e.g., the true batting averages of \(p=10\) baseball players, or the efficacy of \(p=5\) different hospital treatments).
- Model: Let \(X_i \sim N(\theta_i, \sigma^2)\) be the observed sample mean for group \(i\), for \(i = 1, \dots, p\).
- Goal: Estimate the vector of true means \(\boldsymbol{\theta} = (\theta_1, \dots, \theta_p)\) simultaneously. The loss is the sum of squared errors: \(L(\boldsymbol{\theta}, \hat{\boldsymbol{\theta}}) = \sum (\theta_i - \hat{\theta}_i)^2\).
The MLE Approach (Total Separation): The standard estimator is \(\hat{\theta}_i^{\text{MLE}} = X_i\). This estimates each group entirely independently, using only data from that specific group. If a specific player has a lucky streak, their estimate is very high; if they are unlucky, it is very low.
The James-Stein Approach (Shrinkage / Pooling): In this context, the James-Stein estimator (specifically the variation shrinking toward the grand mean \(\bar{X}\)) is: \[ \hat{\theta}_i^{JS} = \bar{X} + \left( 1 - \frac{(p-3)\sigma^2}{\sum (X_i - \bar{X})^2} \right) (X_i - \bar{X}) \]
Why is this better? Even though the groups might be physically independent (e.g., distinct hospitals), the James-Stein estimator “borrows strength” from the ensemble.
- Noise Reduction: Extreme observations \(X_i\) are likely to contain more positive noise than signal. Shrinking them toward the global average \(\bar{X}\) reduces this variance.
- Stein’s Paradox: While \(\hat{\theta}_i^{JS}\) introduces bias (estimates are pulled toward the center), the reduction in variance is so significant that the Total Risk (sum of squared errors over all groups) is strictly lower than that of the MLE, provided \(p \ge 3\).
Thus, estimating the groups together yields a more accurate global picture than estimating them separately, even if the groups are independent.
9.5.10 Why Is This Paradoxical?
The result that \(d^{JS}\) dominates \(d^0\) is called Stein’s Paradox because it defies intuition in several ways:
- Independence Irrelevance: The result holds even if the components \(X_i\) are completely unrelated (e.g., \(X_1\) is the price of tea in China, \(X_2\) is the temperature in Saskatoon, and \(X_3\) is the weight of a local cat). It seems absurd that combining unrelated data improves the estimate of each, but the combined risk is indeed lower.
- No “Free Lunch”: The James-Stein estimator does not improve every individual component \(\theta_i\) simultaneously for every realization. Instead, it minimizes the total risk \(\sum E(\hat{\theta}_i - \theta_i)^2\). It sacrifices accuracy on outliers (by biasing them) to gain significant stability on the bulk of the data.
- Destruction of Symmetry: The MLE is invariant under translation and rotation. The James-Stein estimator breaks this symmetry by shrinking toward an arbitrary point (usually the origin or the grand mean), yet it yields a better objective performance.
9.5.11 What We Learned
- Bias-Variance Tradeoff: This is the most famous example where introducing bias (shrinkage) leads to a massive reduction in variance, thereby reducing the overall Mean Squared Error (MSE). Unbiasedness is not always a virtue in estimation.
- Inadmissibility in High Dimensions: Intuitions formed in 1D or 2D (where MLE is admissible) fail in higher dimensions (\(p \ge 3\)). The volume of space grows so fast that “standard” diffuse priors or MLEs become inefficient.
- Hierarchical Modeling: Stein’s result provides the theoretical foundation for Hierarchical Bayesian Models. When we assume parameters come from a common distribution (e.g., \(\theta_i \sim N(\mu, \tau^2)\)), we naturally derive shrinkage estimators that “borrow strength” across groups, formalized as Empirical Bayes or fully Bayesian methods.
9.5.12 Bias-Variance Decomposition for James-Stein Estimator
Based on the derivations in your handwritten notes, here are the corresponding LaTeX equations formatted for your Quarto document.
\[ X = \begin{pmatrix} x_1 \\ x_2 \end{pmatrix} \]
The Mean Squared Error (MSE) of the James-Stein estimator \(d^{JS}(X)\) with respect to the parameter \(\theta\) is decomposed by adding and subtracting the expected value \(u_{d^{JS}} = E^{X|\theta}[d^{JS}(X)]\):
\[ \begin{aligned} E^{X|\theta} \left[ \| d^{JS}(X) - \theta \|^2 \right] &= E^{X|\theta} \left[ \| d^{JS} - u_{d^{JS}} + u_{d^{JS}} - \theta \|^2 \right] \\ &= V(d^{JS}(X)) + \left[ Bias(d^{JS}(X)) \right]^2 \end{aligned} \]
where the components are defined as:
Variance Component \[ V(d^{JS}(X)) = E^{X|\theta} \left[ \| d^{JS}(X) - u_{d^{JS}} \|^2 \right] \]
Bias Component \[ Bias(d^{JS}(X)) = u_{d^{JS}} - \theta \]
Remark. Note that while the ordinary MLE \(X\) is unbiased (\(E^{X|\theta}(X) - \theta = 0\)), the James-Stein estimator introduces a deliberate bias to significantly reduce the variance, resulting in a lower total MSE when the dimension is three or greater.
Code
library(ggplot2)
library(dplyr)
library(latex2exp)
# --- 1. Parameters ---
theta <- c(1, 1)
sigma <- 0.35
shrink_const <- 0.5
radii <- c(0.6, 1.2) * sigma
# --- 2. Helper Function ---
js_map <- function(x, y) {
sq_norm <- x^2 + y^2
s <- 1 - shrink_const / sq_norm
return(c(x * s, y * s))
}
# --- 3. Observation Data (8 Points) ---
angles_obs <- seq(0, 2 * pi, length.out = 9)[1:8]
obs_radii <- rep(radii, length.out = 8)
x_obs <- theta[1] + obs_radii * cos(angles_obs)
y_obs <- theta[2] + obs_radii * sin(angles_obs)
df_obs <- data.frame(x1 = x_obs, x2 = y_obs)
# Apply mapping to observations
df_obs_mapped <- t(apply(df_obs, 1, function(row) js_map(row[1], row[2])))
df_obs$x1_js <- df_obs_mapped[,1]
df_obs$x2_js <- df_obs_mapped[,2]
# Empirical mean of the 8 shrunken points (+)
mean_js <- colMeans(df_obs[, c("x1_js", "x2_js")])
mean_js_df <- data.frame(x = mean_js[1], y = mean_js[2])
# --- 4. Construct Contours via Mapping ---
angles_contour <- seq(0, 2 * pi, length.out = 200)
contour_list <- lapply(radii, function(r) {
gray_x <- theta[1] + r * cos(angles_contour)
gray_y <- theta[2] + r * sin(angles_contour)
green_pts <- t(mapply(js_map, gray_x, gray_y))
data.frame(
gx = gray_x, gy = gray_y,
jx = green_pts[,1], jy = green_pts[,2],
radius_id = as.factor(r)
)
})
df_contours <- bind_rows(contour_list)
# --- 5. Plotting ---
ggplot() +
coord_fixed(xlim = c(-0.1, 2.2), ylim = c(-0.1, 2.2)) +
theme_minimal() +
theme(
panel.grid = element_blank(),
axis.text = element_blank(),
axis.title = element_blank(),
axis.ticks = element_blank(),
plot.title = element_text(hjust = 0.5, size = 16),
legend.position = "right"
) +
# Arrowed Axis Lines
geom_segment(aes(x = 0, y = 0, xend = 2.1, yend = 0),
arrow = arrow(length = unit(0.3, "cm")), color = "black") +
geom_segment(aes(x = 0, y = 0, xend = 0, yend = 2.1),
arrow = arrow(length = unit(0.3, "cm")), color = "black") +
# Axis Labels
annotate("text", x = 2.2, y = 0, label = TeX("$x_1$"), vjust = 1.5, size = 5) +
annotate("text", x = 0, y = 2.2, label = TeX("$x_2$"), hjust = 1.5, size = 5) +
annotate("text", x = -0.05, y = -0.05, label = "O", size = 4) +
# Grey Lines from Origin to Original Points (x)
geom_segment(data = df_obs, aes(x = 0, y = 0, xend = x1, yend = x2),
color = "grey85", size = 0.5, alpha = 0.7) +
# Original Density Contours (Gray Dashed)
geom_path(data = df_contours, aes(x = gx, y = gy, group = radius_id),
color = "grey70", linetype = "dashed") +
# Mapped Density Contours (Green Dashed)
geom_path(data = df_contours, aes(x = jx, y = jy, group = radius_id),
color = "palegreen4", linetype = "dashed", size = 0.7) +
# Points for Legend
geom_point(aes(x = theta[1], y = theta[2], color = "theta", shape = "theta"), size = 4) +
geom_point(data = df_obs, aes(x = x1, y = x2, color = "x", shape = "x"),
size = 2.5, stroke = 0.8) +
geom_point(data = df_obs, aes(x = x1_js, y = x2_js, color = "djs", shape = "djs"),
size = 2.5) +
geom_point(data = mean_js_df, aes(x = x, y = y, color = "mean", shape = "mean"),
size = 3, stroke = 1.2) +
# Manual Scale Definitions
scale_color_manual(name = "Legend",
values = c("theta" = "red", "x" = "black",
"djs" = "darkgreen", "mean" = "darkgreen"),
labels = unname(TeX(c("$d^{JS}(x)$", "$\\bar{d}^{JS}$", "$x$", "$\\theta$")))) +
scale_shape_manual(name = "Legend",
values = c("theta" = 16, "x" = 1, "djs" = 17, "mean" = 3),
labels = unname(TeX(c("$d^{JS}(x)$", "$\\bar{d}^{JS}$", "$x$", "$\\theta$")))) +
ggtitle(TeX("Bias-Variance Tradeoff"))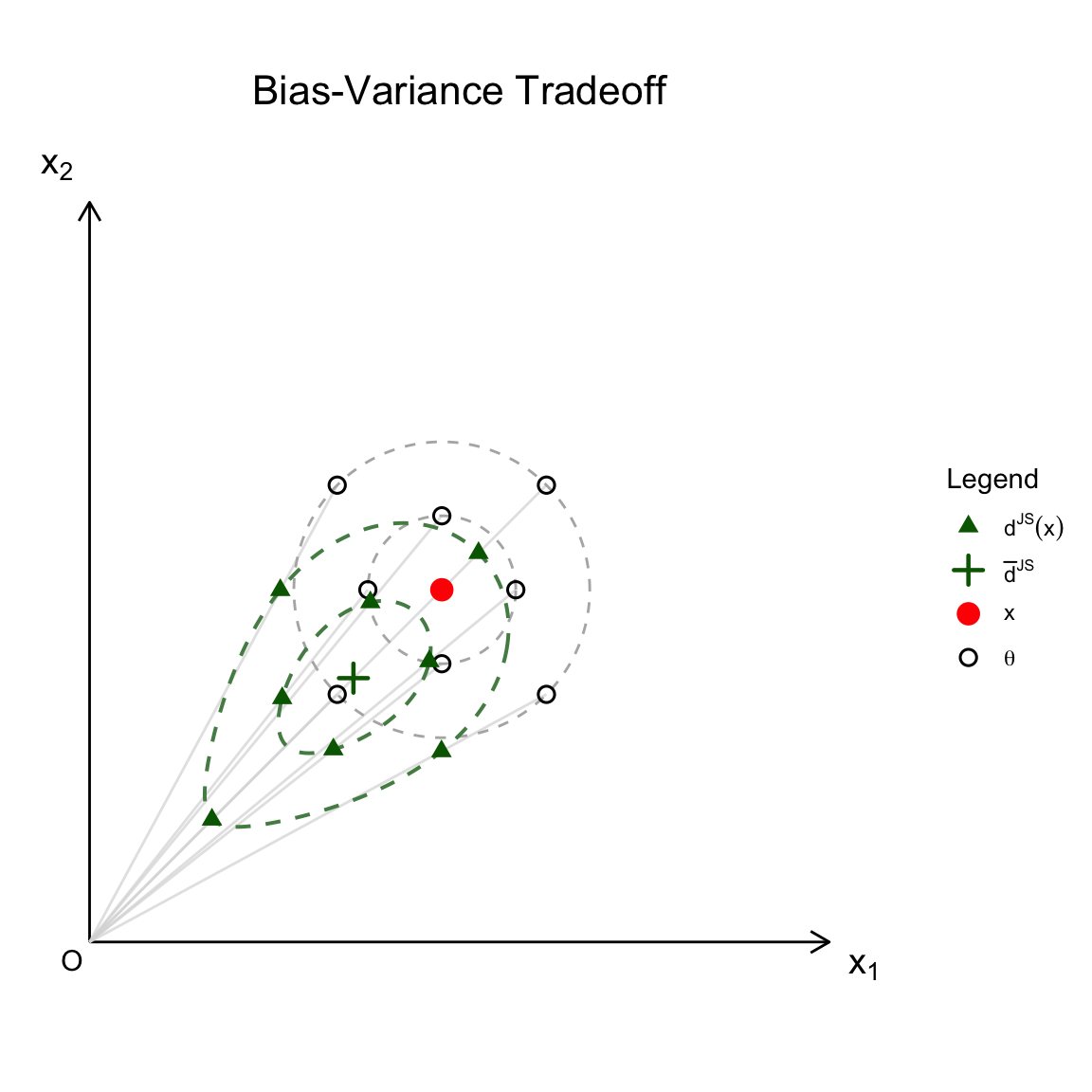
9.6 Empirical Bayes Rules
The James-Stein estimator provides a natural entry point into the concept of Empirical Bayes (EB). While the Stein estimator was originally derived using frequentist risk arguments, it can be intuitively understood as a Bayesian estimator where the parameters of the prior distribution are estimated from the data itself.
9.6.1 The General Empirical Bayes Framework
In a standard Bayesian analysis, the hyperparameters of the prior are fixed based on subjective belief or external information. In contrast, Empirical Bayes uses the observed data to “learn” the prior.
The workflow typically follows these steps:
Hierarchical Model: We assume the data \(X\) comes from a distribution \(f(x|\theta)\), and the parameter \(\theta\) comes from a prior \(\pi(\theta|\eta)\) controlled by hyperparameters \(\eta\).
Marginal Likelihood (Evidence): We integrate out the parameter \(\theta\) to obtain the marginal distribution of the data given the hyperparameters: \[m(x|\eta) = \int f(x|\theta) \pi(\theta|\eta) d\theta\]
Estimation of Hyperparameters: Instead of fixing \(\eta\), we estimate it by maximizing the marginal likelihood (Type-II Maximum Likelihood) or using method-of-moments: \[\hat{\eta} = \underset{\eta}{\arg\max} \ m(x|\eta)\]
Posterior Inference: We proceed with standard Bayesian inference, but we substitute the estimated estimate \(\hat{\eta}\) into the posterior: \[\pi(\theta|x, \hat{\eta}) \propto f(x|\theta) \pi(\theta|\hat{\eta})\]
Discussion:
- “Borrowing Strength”: EB allows us to pool information across independent groups to estimate the common structure (the prior) governing them.
- The Critique: A purist Bayesian might object that using the data twice (once to estimate the prior, once to estimate \(\theta\)) underestimates the uncertainty. A fully Bayesian Hierarchical model would instead place a “hyperprior” on \(\eta\) and integrate it out.
9.6.2 Deriving James-Stein as Empirical Bayes
The James-Stein estimator can be viewed as an Empirical Bayes procedure, where the hyperparameters of the prior are estimated directly from the data rather than being specified a priori.
Model:
- Likelihood: \(X_i | \mu_i \sim N(\mu_i, 1)\) for \(i=1, \dots, p\).
- Prior: \(\mu_i \sim N(0, \sigma^2)\), where \(\sigma^2\) is an unknown hyperparameter.
Step 1: The Ideal Bayes Estimator
If \(\sigma^2\) were known, the posterior distribution of \(\mu_i\) would be Normal. The optimal estimator under squared error loss is the posterior mean: \[E^{\mu_i|X_i, \sigma^2}[\mu_i] = \frac{\sigma^2}{1+\sigma^2} X_i = \left( 1 - \frac{1}{1+\sigma^2} \right) X_i\] We define the shrinkage factor \(B = \frac{1}{1+\sigma^2}\).
Step 2: Marginal Estimation
The marginal distribution of the data (integrating out \(\mu_i\)) is: \[X_i \sim N(0, 1+\sigma^2)\] Consequently, the sum of squares \(S = ||X||^2 = \sum X_i^2\) follows a scaled Chi-squared distribution: \[S \sim (1+\sigma^2) \chi^2_p\]
Step 3: Estimating the Shrinkage Factor
We need an estimator for \(B = \frac{1}{1+\sigma^2}\). From the properties of the inverse Chi-square distribution, we know \(E^X[1/\chi^2_p] = \frac{1}{p-2}\) for \(p > 2\). Therefore: \[E^X \left[ \frac{p-2}{S} \right] = \frac{p-2}{1+\sigma^2} E^X\left[\frac{1}{\chi^2_p}\right] = \frac{p-2}{1+\sigma^2} \cdot \frac{1}{p-2} = \frac{1}{1+\sigma^2} = B\]
Thus, \(\hat{B} = \frac{p-2}{||X||^2}\) is an unbiased estimator of the optimal shrinkage factor \(B\).
Step 4: The Empirical Bayes Rule
Plugging \(\hat{B}\) into the ideal Bayes estimator recovers the James-Stein rule: \[\delta^{EB}(X) = \left( 1 - \hat{B} \right) X = \left( 1 - \frac{p-2}{||X||^2} \right) X\]
Remarks:
Adaptive Shrinkage: The James-Stein estimator automatically adjusts the amount of shrinkage based on the observed total magnitude \(\lVert X \rVert^2\). If the data suggests the true means are spread far from zero, \(\lVert X \rVert^2\) will be large, \(\hat{B}\) will be small, and we shrink less.
Unbiasedness of B: Interestingly, while \(\hat{B}\) is an unbiased estimator of the shrinkage factor, the resulting James-Stein estimator itself is biased toward the origin. This is a classic example of sacrificing unbiasedness to minimize total risk.
9.7 Hierarchical Modeling via MCMC
In complex Bayesian settings where the posterior distribution cannot be derived analytically, we utilize hierarchical structures to represent levels of uncertainty and Markov Chain Monte Carlo (MCMC) to approximate the resulting distributions.
9.7.1 Hierarchical Model Structure
A hierarchical model decomposes a complex joint distribution into a series of conditional levels. The general mathematical form is:
\[ \begin{aligned} \text{Level 1 (Data Likelihood):} & \quad X_i | \mu_i, \sigma^2 \sim f(x_i | \mu_i, \sigma^2) \\ \text{Level 2 (Parameters):} & \quad \mu_i | \theta, \tau^2 \sim \pi(\mu_i | \theta, \tau^2) \\ \text{Level 3 (Hyperparameters):} & \quad \theta, \tau^2 \sim \pi(\theta, \tau^2) \end{aligned} \]
The goal is to compute the joint posterior distribution of all unobserved parameters given the data \(X = \{X_1, \dots, X_n\}\):
\[ p(\boldsymbol{\mu}, \theta, \tau^2 | X) \propto \left[ \prod_{i=1}^n f(x_i | \mu_i, \sigma^2) \pi(\mu_i | \theta, \tau^2) \right] \pi(\theta, \tau^2) \]
9.7.2 Graphical Model Representation (tree Structure)
The following tree diagram illustrates the conditional dependencies. Note that the parameters \(\mu_i\) are conditionally independent given the hyperparameter \(\theta\), which facilitates “borrowing strength” across groups.
9.7.3 MCMC Estimation
In hierarchical models, the joint posterior distribution \(p(\boldsymbol{\mu}, \theta | X)\) often lacks a closed-form analytical solution due to the integration required for the normalizing constant. We use Markov Chain Monte Carlo (MCMC) to draw sequence of samples \(\{\boldsymbol{\mu}^{(t)}, \theta^{(t)}\}\) that converge to the target posterior distribution.
9.7.3.1 Gibbs Sampling Algorithm
Gibbs sampling is an algorithm for sampling from a multivariate distribution by sequentially sampling from the full conditional distributions. To sample from a target distribution \(p(\theta_1, \theta_2, \dots, \theta_k)\), the algorithm iterates through each variable, updating it conditioned on the current values of all other variables:
\[ \begin{aligned} \theta_1^{(t+1)} &\sim p(\theta_1 | \theta_2^{(t)}, \theta_3^{(t)}, \dots, \theta_k^{(t)}) \\ \theta_2^{(t+1)} &\sim p(\theta_2 | \theta_1^{(t+1)}, \theta_3^{(t)}, \dots, \theta_k^{(t)}) \\ &\vdots \\ \theta_k^{(t+1)} &\sim p(\theta_k | \theta_1^{(t+1)}, \theta_2^{(t+1)}, \dots, \theta_{k-1}^{(t+1)}) \end{aligned} \]
Example 9.10 (Gibbs Sampling for Groups of Normal Data) The Model
To apply the general Gibbs sampling framework \(\theta_1, \theta_2, \dots, \theta_k\) to our specific hierarchical model, we identify the variables as follows:
Data Observations (\(X_i\)): These are the known, measured values at the lowest level of the hierarchy (e.g., test scores of students in school \(i\)). In the Gibbs sampler, these remain fixed and condition the updates of the parameters.
Group-Level Parameters (\(\theta_1 = \mu_i\)): These represent the latent means for each specific group or cluster. In the update step, \(\mu_i\) acts as the first block of variables. It is updated by “compromising” between the local data \(X_i\) and the global characteristic \(\theta\).
Global Hyperparameter (\(\theta_2 = \theta\)): This represents the common mean across all groups. It acts as the second block in the sampler. Its update depends on the current state of all \(\mu_i\) values, effectively “pooling” information from all groups to estimate the overall population center.
Gibbs Update in Hierarchical Models
In the hierarchical tree structure provided earlier, let our parameter vector be \((\mu_i, \theta)\). The “orthogonality” of the updates becomes clear when we derive the full conditionals for a Gaussian case:
Case \(\theta_1 = \mu_i\): Sample \(\mu_i^{(t+1)}\) from \(p(\mu_i | X_i, \theta^{(t)})\). This is a normal distribution with: \[ \mu_i^{(t+1)} \sim N\left( \frac{\tau^2 X_i + \sigma^2 \theta^{(t)}}{\sigma^2 + \tau^2}, \frac{\sigma^2 \tau^2}{\sigma^2 + \tau^2} \right) \]
Case \(\theta_2 = \theta\): Sample \(\theta^{(t+1)}\) from \(p(\theta | \boldsymbol{\mu}^{(t+1)})\). Assuming a flat prior \(\pi(\theta) \propto 1\): \[ \theta^{(t+1)} \sim N\left( \frac{1}{n} \sum_{i=1}^n \mu_i^{(t+1)}, \frac{\tau^2}{n} \right) \]
Visual Characteristic: Gibbs sampling moves along the coordinate axes because it updates one parameter at a time while holding others constant.
9.7.3.2 Metropolis-hastings (MH) Sampling
When the full conditional distributions are not easy to sample from, we use the Metropolis-Hastings algorithm. At each step \(t\):
- Propose: Draw a candidate state \(\theta^*\) from a proposal distribution \(q(\theta^* | \theta^{(t)})\).
- Accept/Reject: Calculate the acceptance probability: \[ \alpha = \min \left( 1, \frac{p(\theta^* | X) q(\theta^{(t)} | \theta^*)}{p(\theta^{(t)} | X) q(\theta^* | \theta^{(t)})} \right) \]
- Set \(\theta^{(t+1)} = \theta^*\) with probability \(\alpha\); otherwise, set \(\theta^{(t+1)} = \theta^{(t)}\).
Visual Characteristic: MH sampling moves in arbitrary directions and can “stay put” if a proposal is rejected, exploring the space via a random walk.
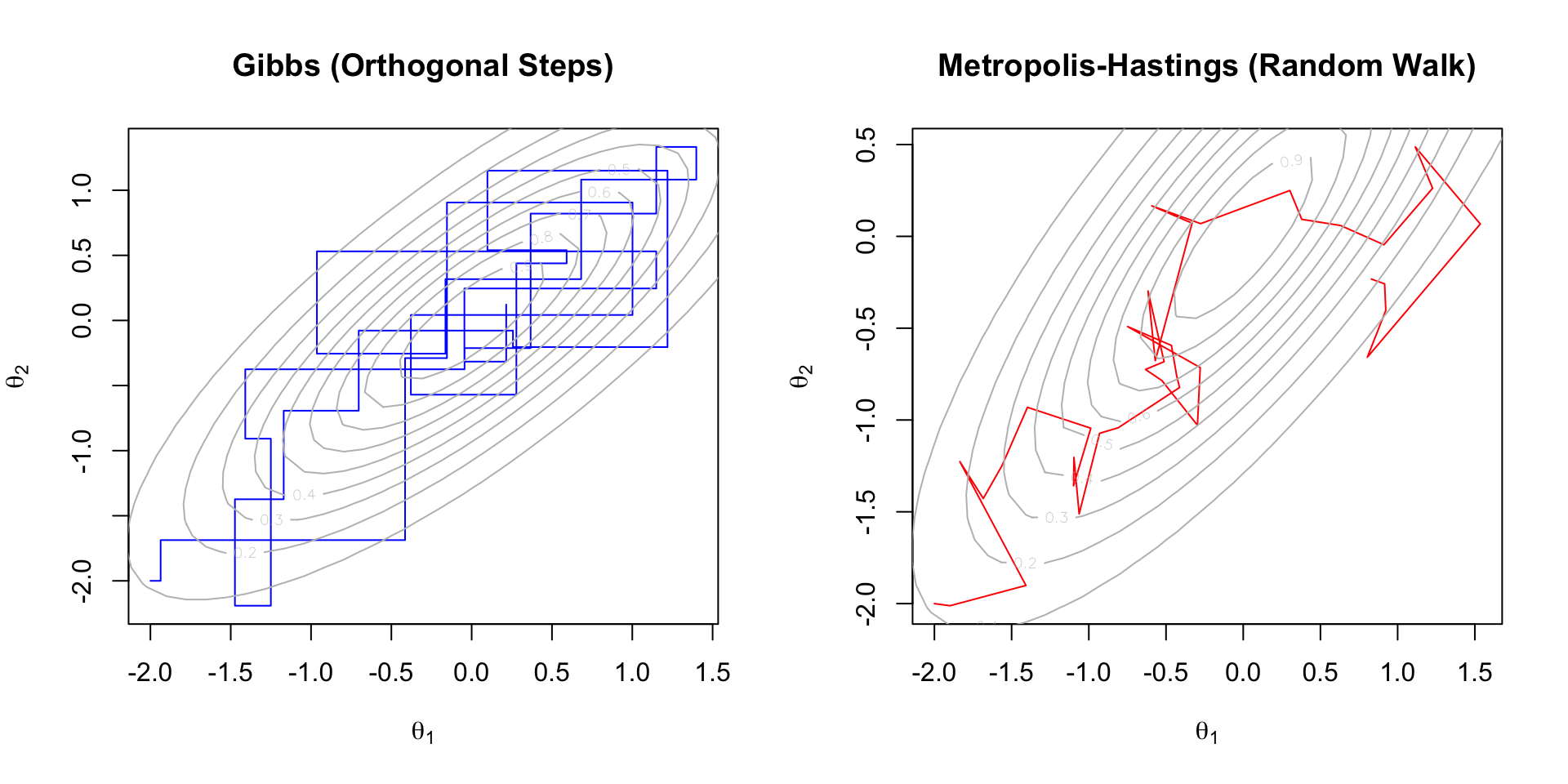
9.8 Case Study: 1998 Major League Baseball Home Run Race
In 1998, the baseball world was captivated by Mark McGwire and Sammy Sosa as they chased Roger Maris’ 1961 record of 61 home runs in a single season. While McGwire and Sosa finished with 70 and 66 home runs respectively, we consider whether such performance could have been predicted using pre-season exhibition data.
For a set of \(i = 1, \dots, 17\) players (including McGwire and Sosa), we observe their batting records in pre-season exhibition matches. Our goal is to estimate each player’s home run “strike rate” for the competitive season.
9.8.1 Transforming Data
We utilize the pre-season home runs (\(y_i\)) and at-bats (\(n_i\)) for 17 players. The data is transformed using a variance-stabilizing transformation to approximate a normal distribution with known variance \(\sigma^2 = 1\).
\[ x_i = \sqrt{n_i} \arcsin\left( 2 \frac{y_i}{n_i} - 1 \right) \]
The goal is to estimate the latent parameter \(\mu_i\) for each player and compare it to the “true” regular season performance.
9.8.2 True Season Parameter (\(\mu_i\) or \(p_i^{season}\))
To validate our estimates, we define the “true” parameter value \(\mu_i\) using the player’s performance over the full competitive season. Let \(Y_i\) be the total home runs and \(N_i\) be the total at-bats in the regular season. The true transformed rate is calculated as:
\[ \mu_i^{\text{season}} = \sqrt{n_i} \arcsin\left( 2 \frac{Y_i}{N_i} - 1 \right) \]
Note that while we use the season-long probability (\(Y_i/N_i\)), we scale it by the pre-season sample size (\(\sqrt{n_i}\)). This ensures that \(\mu_i^{\text{season}}\) is on the same scale as our observations \(x_i\), allowing for direct comparison of the estimation error.
| Player | \(y_i\) | \(n_i\) | \(p_i^{\text{pre}}\) | \(x_i\) | \(Y_i\) | \(N_i\) | \(p_i^{\text{seas}}\) | \(\mu_i\) |
|---|---|---|---|---|---|---|---|---|
| 1 | 7 | 58 | 0.121 | -6.559 | 70 | 509 | 0.138 | -6.176 |
| 2 | 9 | 59 | 0.153 | -5.901 | 66 | 643 | 0.103 | -7.055 |
| 3 | 4 | 74 | 0.054 | -9.476 | 56 | 633 | 0.088 | -8.317 |
| 4 | 7 | 84 | 0.083 | -9.029 | 46 | 645 | 0.071 | -9.441 |
| 5 | 3 | 69 | 0.043 | -9.558 | 45 | 606 | 0.074 | -8.463 |
| 6 | 6 | 63 | 0.095 | -7.488 | 44 | 555 | 0.079 | -7.937 |
| 7 | 2 | 60 | 0.033 | -9.323 | 43 | 619 | 0.069 | -8.035 |
| 8 | 10 | 54 | 0.185 | -5.005 | 40 | 609 | 0.066 | -7.734 |
| 9 | 2 | 53 | 0.038 | -8.589 | 37 | 552 | 0.067 | -7.622 |
| 10 | 2 | 60 | 0.033 | -9.323 | 34 | 540 | 0.063 | -8.238 |
| 11 | 4 | 66 | 0.061 | -8.720 | 32 | 561 | 0.057 | -8.843 |
| 12 | 3 | 66 | 0.045 | -9.270 | 30 | 440 | 0.068 | -8.469 |
| 13 | 2 | 72 | 0.028 | -10.487 | 29 | 585 | 0.050 | -9.518 |
| 14 | 5 | 64 | 0.078 | -8.034 | 28 | 531 | 0.053 | -8.859 |
| 15 | 3 | 42 | 0.071 | -6.673 | 23 | 454 | 0.051 | -7.237 |
| 16 | 2 | 38 | 0.053 | -6.829 | 21 | 504 | 0.042 | -7.149 |
| 17 | 6 | 58 | 0.103 | -6.975 | 15 | 244 | 0.061 | -8.146 |
In this analysis, we model the home run strike rates of 17 Major League Baseball players using pre-season exhibition data from 1998. We apply five statistical methods ranging from simple independent estimation to advanced Bayesian decision theory.
9.8.3 Methods for Estimating \(\mu_i\) (transformed Scale)
9.8.3.1 Method 1: Simple Estimation (MLE)
The Maximum Likelihood Estimator (MLE) assumes each player’s performance is independent. It relies solely on the observed pre-season data.
\[ \hat{\mu}_i^{MLE} = X_i \]
Code
# Simple Estimate Is Just the Data Itself
mu_mle <- baseball_data$x
# MSE Calculation (transformed Scale)
mse_mle <- mean((mu_mle - baseball_data$true_mu)^2)9.8.3.2 Method 2: Empirical Bayes (james-stein)
The James-Stein estimator introduces a global mean \(\bar{X}\) and shrinks individual estimates toward it. This assumes the players come from a common population distribution.
\[ \hat{\mu}_i^{JS} = \bar{X} + \left( 1 - \frac{k-3}{\sum (X_i - \bar{X})^2} \right) (X_i - \bar{X}) \]
where \(k=17\) is the number of players.
Code
theta_hat <- mean(baseball_data$x)
S <- sum((baseball_data$x - theta_hat)^2)
shrinkage_factor <- 1 - (14 / S)
mu_js <- theta_hat + shrinkage_factor * (baseball_data$x - theta_hat)
# MSE Calculation (transformed Scale)
mse_js <- mean((mu_js - baseball_data$true_mu)^2)9.8.3.3 Method 3: Fully Bayesian MCMC (brms)
We use a hierarchical Bayesian model where parameters are treated as random variables. We implement this using brms.
\[ \begin{aligned} X_i &\sim N(\mu_i, 1) \\ \mu_i &\sim N(\theta, \tau^2) \\ \theta &\sim N(0, 10) \\ \tau &\sim \text{Cauchy}(0, 2) \end{aligned} \]
Code
baseball_data$sei <- rep(1, length(baseball_data$x))
# Fit Random Intercept Model: X | Se(1) ~ 1 + (1|player)
fit_brms <- brm(
formula = x | se(sei, sigma = TRUE) ~ 1 + (1 | Player),
data = baseball_data,
prior = c(
prior(normal(0, 10), class = "Intercept"),
prior(cauchy(0, 2), class = "sd")
),
chains = 2, iter = 4000, warmup = 1000, seed = 123,
refresh = 0
)
# Extract Point Estimates (posterior Means)
post_means <- fitted(fit_brms)[, "Estimate"]
mu_brms <- post_means
# MSE Calculation (transformed Scale)
mse_brms <- mean((mu_brms - baseball_data$true_mu)^2)9.8.4 Comparison of Estimates of \(\mu_i\)
Full Comparison of Estimates (Transformed Scale)
The following table presents the transformed data (\(x_i\)) and the true season parameter (\(\mu_i\)) alongside the estimates from the three methods. The rows are sorted by \(x_i\) to visualize how the shrinkage methods (James-Stein and Bayesian) pull the estimates away from the extremes and toward the population mean compared to the raw MLE.
| Player | \(x_i\) (MLE) | \(\hat{\mu}_{JS}\) | \(\hat{\mu}_{Bayes}\) | \(\mu_{true}\) |
|---|---|---|---|---|
| 13 | -10.487 | -9.589 | -8.746 | -9.518 |
| 5 | -9.558 | -9.006 | -8.478 | -8.463 |
| 3 | -9.476 | -8.954 | -8.470 | -8.317 |
| 7 | -9.323 | -8.858 | -8.412 | -8.035 |
| 10 | -9.323 | -8.858 | -8.415 | -8.238 |
| 12 | -9.270 | -8.825 | -8.412 | -8.469 |
| 4 | -9.029 | -8.673 | -8.331 | -9.441 |
| 11 | -8.720 | -8.479 | -8.260 | -8.843 |
| 9 | -8.589 | -8.397 | -8.206 | -7.622 |
| 14 | -8.034 | -8.048 | -8.054 | -8.859 |
| 6 | -7.488 | -7.705 | -7.897 | -7.937 |
| 17 | -6.975 | -7.384 | -7.754 | -8.146 |
| 16 | -6.829 | -7.292 | -7.714 | -7.149 |
| 15 | -6.673 | -7.194 | -7.663 | -7.237 |
| 1 | -6.559 | -7.122 | -7.628 | -6.176 |
| 2 | -5.901 | -6.709 | -7.441 | -7.055 |
| 8 | -5.005 | -6.146 | -7.186 | -7.734 |
Plots of Squared Errors (Sorted by \(x_i\))
This plot displays the Squared Error for each player. The x-axis represents the players sorted from lowest pre-season performance to highest.
Code
# Calculate Squared Errors Using the SORTED Dataframe
err_mle <- (df_sorted$x_i - df_sorted$mu_true)^2
err_js <- (df_sorted$mu_js - df_sorted$mu_true)^2
err_brms <- (df_sorted$mu_bayes - df_sorted$mu_true)^2
# Determine Y-axis Range
y_max <- max(c(err_mle, err_js, err_brms))
# Plot MLE Errors (baseline)
plot(1:17, err_mle, type = "b", pch = 1, col = "black", lty = 2,
xlab = "Player Index (Sorted by Pre-season Performance)",
ylab = expression(Squared~Error~~(hat(mu) - mu[true])^2),
main = "Estimation Error Comparison (Sorted)",
ylim = c(0, y_max))
# Add James-stein Errors
lines(1:17, err_js, type = "b", pch = 19, col = "blue")
# Add Bayesian (brms) Errors
lines(1:17, err_brms, type = "b", pch = 17, col = "red")
# Add Grid and Legend
grid()
legend("topleft",
title = "Mean Squared Error",
legend = c(paste0("MLE: ", round(mse_mle, 3)),
paste0("JS: ", round(mse_js, 3)),
paste0("Bayes: ", round(mse_brms, 3))),
col = c("black", "blue", "red"),
pch = c(1, 19, 17),
lty = c(2, 1, 1))
9.8.5 Methods for Estimating \(p_i\) Directly
9.8.5.1 Method 1-3: Converting \(\hat \mu_i\) Back to \(p_i\)
The first three methods (MLE, James-Stein, and Normal-Normal Bayes) estimated the parameter \(\mu_i\) on the transformed scale. To obtain the probability estimates \(\hat{p}_i\), we apply the inverse of the variance-stabilizing transformation:
\[ \hat{p}_i = \frac{1}{2} \left( \sin\left( \frac{\hat{\mu}_i}{\sqrt{n_i}} \right) + 1 \right) \]
where \(\hat{\mu}_i\) corresponds to the estimate derived from Method 1, 2, or 3, and \(n_i\) is the number of pre-season at-bats for player \(i\).
9.8.5.2 Method 4: Hierarchical Logistic Regression (logit-normal)
In this fourth method, we model the probability \(p_i\) directly using a hierarchical structure on the log-odds scale, rather than transforming the data.
We assume the count \(y_i\) follows a Binomial distribution. The log-odds (logit) of the success rate \(p_i\) are drawn from a common Normal distribution with unknown mean \(\mu_0\) and standard deviation \(\tau_0\).
\[ \begin{aligned} y_i | p_i &\sim \text{Binomial}(n_i, p_i) \\ \text{logit}(p_i) &\sim N(\mu_0, \tau_0^2) \\ \mu_0 &\sim N(0, 10) \\ \tau_0 &\sim \text{Cauchy}(0, 2) \end{aligned} \]
We implement this in brms using the binomial family with a logit link. The individual point estimate \(\hat{p}_i\) is the posterior mean of \(p_i\). Note that because the inverse-logit function is non-linear, the posterior mean of \(p_i\) is not simply the inverse-logit of the posterior mean of the random effect; brms handles this integration automatically via the fitted() function.
Code
# 1. Fit Hierarchical Logistic Regression
# We use the 'file' argument to cache the model on disk
fit_logit <- brm(
formula = Pre_HR | trials(Pre_AtBats) ~ 1 + (1 | Player),
data = baseball_data,
family = binomial(link = "logit"),
prior = c(
prior(normal(0, 5), class = "Intercept"),
prior(cauchy(0, 2), class = "sd")
),
chains = 2, iter = 4000, warmup = 1000, seed = 123,
refresh = 0,
file = "fit_logit_baseball"
)
# 2. Extract specific players for the plots
ordered_players <- baseball_data %>% arrange(p_pre)
target_players <- ordered_players[c(1, 2, 16, 17), ]
# 3. Extract Posterior Draws
# summary = FALSE gives the full MCMC matrix (iter x players)
post_draws <- fitted(fit_logit,
newdata = target_players,
summary = FALSE)Code
library(ggplot2)
library(dplyr)
library(tidyr)
# 1. Prepare data for plotting
plot_list <- list()
for(i in 1:nrow(target_players)) {
p_id <- target_players$Player[i]
n_i <- target_players$Pre_AtBats[i]
plot_list[[i]] <- data.frame(
Player = paste("Player", p_id),
p_sample = post_draws[, i] / n_i,
p_pre = target_players$p_pre[i],
p_season = target_players$p_season[i]
)
}
plot_data <- do.call(rbind, plot_list)
# 2. Draw the faceted density plots
ggplot(plot_data, aes(x = p_sample)) +
geom_density(fill = "steelblue", alpha = 0.4, color = "steelblue") +
geom_vline(aes(xintercept = p_pre),
color = "grey50", linetype = "dashed", linewidth = 1) +
geom_vline(aes(xintercept = p_season),
color = "black", linetype = "solid", linewidth = 1) +
facet_wrap(~Player, scales = "free", ncol = 2) +
theme_minimal() +
labs(
title = "Posterior Distributions of HR Probabilities for Extreme Players",
subtitle = "Dashed Grey: Pre-season (Observed) | Solid Black: Remainder of Season (Actual)",
x = expression(p[i]),
y = "Posterior Density"
) +
theme(
strip.text = element_text(face = "bold"),
panel.spacing = unit(1, "lines")
)
9.8.5.3 Method 5: Optimal Bayes Estimator w.r.t. Relative Absolute Error
While the posterior mean (Method 4) minimizes the Mean Squared Error (MSE), it is not necessarily optimal for the Relative Standardized Error metric we defined earlier: \[L(p, \hat{p}) = \frac{|p - \hat{p}|}{\min(p, 1-p)}\]
This is a form of weighted absolute error loss, where the weight is \(w(p) = \frac{1}{\min(p, 1-p)}\). Theoretical derivation shows that the estimator minimizing the expected posterior loss for this function is the Weighted Posterior Median.
We compute this by extracting the full posterior samples from the Logit-Normal model (Method 4) and calculating the weighted median for each player.
Code
# 1. Extract Posterior Samples (n_samples X 17 Players)
# Posterior_epred Gives Samples of the Expected Count (N * P)
post_counts <- posterior_epred(fit_logit)
# Convert to Probability Scale by Dividing by Trials
p_samples <- sweep(post_counts, 2, baseball_data$Pre_AtBats, "/")
# 2. Extract Posterior Means (Method 4)
# This provides the missing p_hat_logit variable
p_hat_logit <- colMeans(p_samples)
# 3. Define Function for Weighted Median
# Finds the Value 'q' Such That Sum(weights Where X <= Q) >= 0.5 * Total_weight
get_weighted_median <- function(samples) {
# Calculate weights based on the loss function denominator
# Avoid division by exact zero (unlikely but safer)
denom <- pmin(samples, 1 - samples)
denom[denom < 1e-6] <- 1e-6
weights <- 1 / denom
# Normalize weights
weights_norm <- weights / sum(weights)
# Sort samples and weights
ord <- order(samples)
samp_sorted <- samples[ord]
w_sorted <- weights_norm[ord]
# Find cutoff
cum_w <- cumsum(w_sorted)
idx <- which(cum_w >= 0.5)[1]
return(samp_sorted[idx])
}
# 4. Apply to All Players (Method 5)
p_hat_optimal <- apply(p_samples, 2, get_weighted_median)9.8.5.4 Comparison of All Five Estimates of \(p_i\)
We now compare all five methods: MLE, James-Stein (transformed), Bayes Normal-Normal (transformed), Hierarchical Logit-Normal (Posterior Mean), and Optimal Bayes (Weighted Median).
| Player | Season Avg (\(p_i\)) | MLE | James-Stein | Normal-Bayes | Logit-Normal | Optimal-Bayes |
|---|---|---|---|---|---|---|
| 13 | 0.050 | 0.028 | 0.048 | 0.071 | 0.056 | 0.048 |
| 7 | 0.069 | 0.033 | 0.045 | 0.058 | 0.060 | 0.051 |
| 10 | 0.063 | 0.033 | 0.045 | 0.058 | 0.060 | 0.051 |
| 9 | 0.067 | 0.038 | 0.043 | 0.048 | 0.062 | 0.054 |
| 5 | 0.074 | 0.043 | 0.058 | 0.074 | 0.062 | 0.055 |
| 12 | 0.068 | 0.045 | 0.058 | 0.070 | 0.063 | 0.055 |
| 16 | 0.042 | 0.053 | 0.037 | 0.025 | 0.068 | 0.060 |
| 3 | 0.088 | 0.054 | 0.069 | 0.083 | 0.066 | 0.059 |
| 11 | 0.057 | 0.061 | 0.068 | 0.075 | 0.068 | 0.062 |
| 15 | 0.051 | 0.071 | 0.052 | 0.037 | 0.073 | 0.065 |
| 14 | 0.053 | 0.078 | 0.078 | 0.077 | 0.075 | 0.067 |
| 4 | 0.071 | 0.083 | 0.094 | 0.106 | 0.078 | 0.071 |
| 6 | 0.079 | 0.095 | 0.087 | 0.081 | 0.082 | 0.073 |
| 17 | 0.061 | 0.103 | 0.088 | 0.074 | 0.084 | 0.075 |
| 1 | 0.138 | 0.121 | 0.098 | 0.079 | 0.091 | 0.079 |
| 2 | 0.103 | 0.153 | 0.117 | 0.088 | 0.105 | 0.090 |
| 8 | 0.066 | 0.185 | 0.129 | 0.085 | 0.118 | 0.098 |
1. MSE Comparison
Code
# 3. Calculate MSE
mse_p_mle <- mean((df_compare_sorted$p_mle - df_compare_sorted$p_true)^2)
mse_p_js <- mean((df_compare_sorted$p_js - df_compare_sorted$p_true)^2)
mse_p_norm <- mean((df_compare_sorted$p_norm - df_compare_sorted$p_true)^2)
mse_p_logit <- mean((df_compare_sorted$p_logit - df_compare_sorted$p_true)^2)
mse_p_opt <- mean((df_compare_sorted$p_opt - df_compare_sorted$p_true)^2)
# 4. Plot MSE
y_max <- max((df_compare_sorted$p_mle - df_compare_sorted$p_true)^2)
plot(1:17, (df_compare_sorted$p_mle - df_compare_sorted$p_true)^2,
type = "b", pch = 1, col = "black", lty = 2,
xlab = "Player Index (Sorted by Pre-season)",
ylab = "Squared Error",
main = "Squared Error by Method",
ylim = c(0, y_max))
lines(1:17, (df_compare_sorted$p_js - df_compare_sorted$p_true)^2, type = "b", pch = 19, col = "blue")
lines(1:17, (df_compare_sorted$p_norm - df_compare_sorted$p_true)^2, type = "b", pch = 17, col = "red")
lines(1:17, (df_compare_sorted$p_logit - df_compare_sorted$p_true)^2, type = "b", pch = 15, col = "darkgreen")
lines(1:17, (df_compare_sorted$p_opt - df_compare_sorted$p_true)^2, type = "b", pch = 18, col = "purple")
grid()
legend("topleft",
legend = c(paste0("MLE [MSE: ", round(mse_p_mle, 4), "]"),
paste0("JS [MSE: ", round(mse_p_js, 4), "]"),
paste0("Normal-Bayes [MSE: ", round(mse_p_norm, 4), "]"),
paste0("Logit-Normal [MSE: ", round(mse_p_logit, 4), "]"),
paste0("Optimal-Bayes [MSE: ", round(mse_p_opt, 4), "]")),
col = c("black", "blue", "red", "darkgreen", "purple"),
pch = c(1, 19, 17, 15, 18),
lty = c(2, 1, 1, 1, 1),
cex = 0.75,
bg = "white")
2. Comparison of Relative Absolute Error
We also evaluate the methods using the relative error metric that penalizes deviations based on the rarity of the event: \[ \text{Metric}_i = \frac{|p_i^{\text{true}} - \hat{p}_i|}{\min(p_i^{\text{true}}, 1 - p_i^{\text{true}})} \]
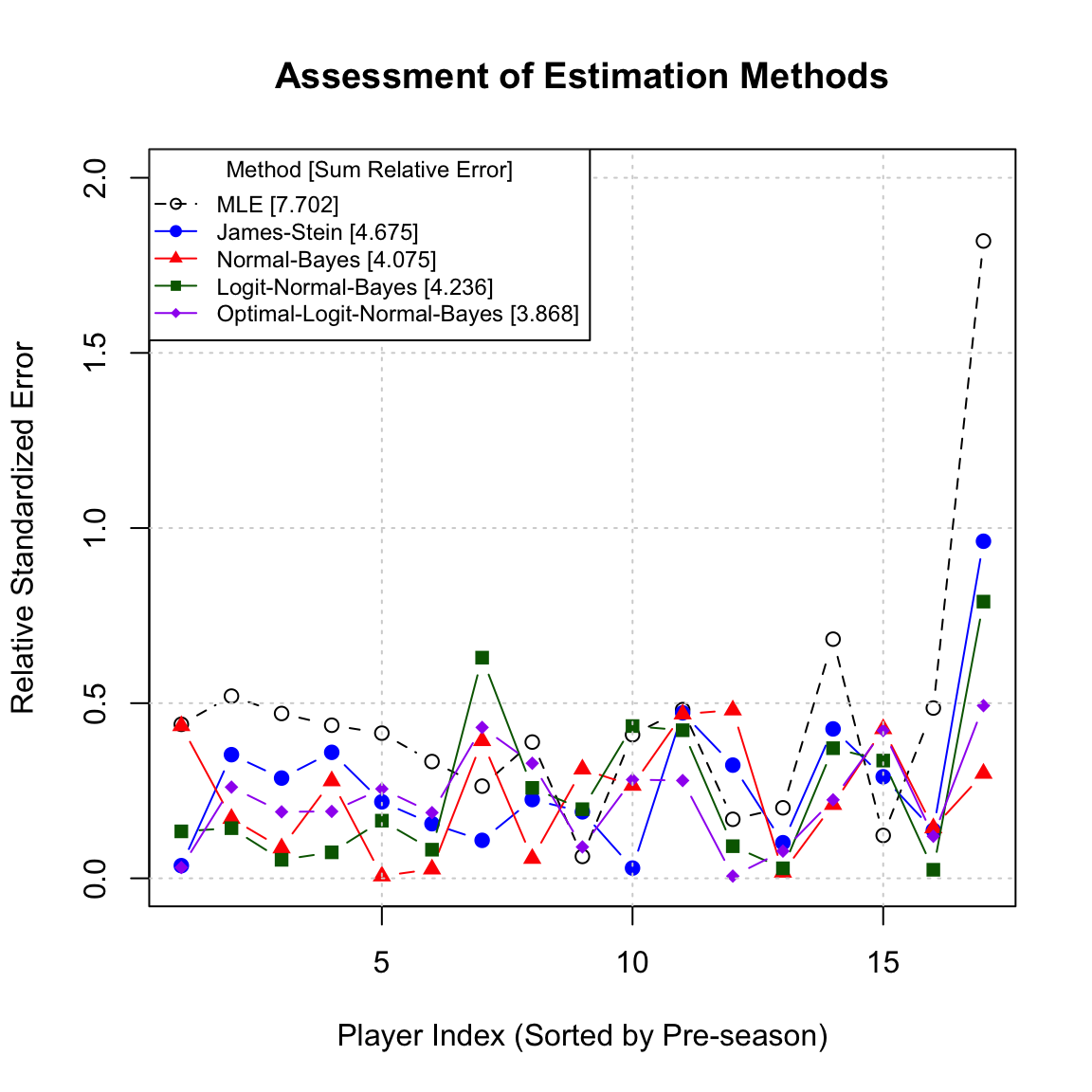
9.9 Bayesian Predictive Distributions
A key feature of Bayesian analysis is the ability to make inference about future observations, rather than just the model parameters. The posterior predictive distribution describes the probability of observing a new data point \(y^*\) given the observed data \(y\).
Definition 9.3 (Posterior Predictive Distribution) Let \(f(y^*|\theta)\) be the sampling distribution of a future observation \(y^*\) given parameter \(\theta\), and let \(\pi(\theta|y)\) be the posterior distribution of \(\theta\) given observed data \(y\). The posterior predictive density is obtained by marginalizing over the parameter \(\theta\):
\[ f(y^*|y) = \int_\Theta f(y^*|\theta) \pi(\theta|y) \, d\theta \]
This distribution incorporates two distinct sources of uncertainty:
- Sampling Uncertainty (Aleatoric): The inherent variability of the data generation process, represented by the variance in \(f(y^*|\theta)\).
- Parameter Uncertainty (Epistemic): The uncertainty regarding the true value of \(\theta\), represented by the variance in the posterior \(\pi(\theta|y)\).
As sample size \(n \to \infty\), the parameter uncertainty vanishes (the posterior approaches a point mass), and the predictive distribution converges to the true data-generating distribution.
Example 9.11 (Normal-normal Predictive Distribution) Consider a case where the data \(y_1, \dots, y_n\) are independent and normally distributed with unknown mean \(\mu\) and known variance \(\sigma^2\):
\[ Y_i | \mu \sim N(\mu, \sigma^2) \]
Assume a conjugate prior for the mean: \(\mu \sim N(\mu_0, \sigma_0^2)\). The posterior distribution is \(\mu|y \sim N(\mu_n, \sigma_n^2)\), where \(\mu_n\) and \(\sigma_n^2\) are the updated posterior hyperparameters.
The predictive distribution for a new observation \(y^*\) is derived as:
\[ \begin{aligned} f(y^*|y) &= \int_{-\infty}^{\infty} f(y^*|\mu) \pi(\mu|y) \, d\mu \\ &= \int_{-\infty}^{\infty} \frac{1}{\sqrt{2\pi\sigma^2}} e^{-\frac{(y^*-\mu)^2}{2\sigma^2}} \times \frac{1}{\sqrt{2\pi\sigma_n^2}} e^{-\frac{(\mu-\mu_n)^2}{2\sigma_n^2}} \, d\mu \end{aligned} \]
This convolution of two Gaussians results in a new Gaussian distribution:
\[ y^* | y \sim N(\mu_n, \sigma^2 + \sigma_n^2) \]
Here, the total predictive variance is the sum of the data variance (\(\sigma^2\)) and the posterior uncertainty about the mean (\(\sigma_n^2\)).