Pythagorean Theorem for Mahalanobis Distance
Definitions and Setup
Let \(x\) be a random vector partitioned as \(x = (x_0, x_1)^T\), and let \(\mu\) be its corresponding center vector \(\mu = (\mu_0, \mu_1)^T\). Let \(\Sigma\) be a symmetric, positive-definite covariance matrix governing the joint space, partitioned into corresponding blocks:
\[
\Sigma = \begin{pmatrix} \Sigma_{00} & \Sigma_{01} \\ \Sigma_{10} & \Sigma_{11} \end{pmatrix}
\]
Define the generalized squared Mahalanobis distance of any vector \(v\) to a center \(c\) with respect to a positive-definite matrix \(S\) as:
\[
D^2(v, c, S) = (v - c)^T S^{-1} (v - c)
\]
For a symmetric, positive-definite matrix \(S\), the Mahalanobis inner product between two vectors \(u\) and \(v\) is defined as \(\langle u, v \rangle_{S^{-1}} = u^T S^{-1} v\). Two vectors are orthogonal in this space if their inner product is zero.
Define the conditional expectation (the linear regression surface) of \(x_1\) given \(x_0\) as \(\mu_{1|0}(x_0)\):
\[
\mu_{1|0}(x_0) = \mu_1 + \Sigma_{10}\Sigma_{00}^{-1}(x_0 - \mu_0)
\]
Define the conditional covariance matrix (the Schur complement of \(\Sigma_{00}\) in \(\Sigma\)) as \(\Sigma_{1|0}\):
\[
\Sigma_{1|0} = \Sigma_{11} - \Sigma_{10}\Sigma_{00}^{-1}\Sigma_{01}
\]
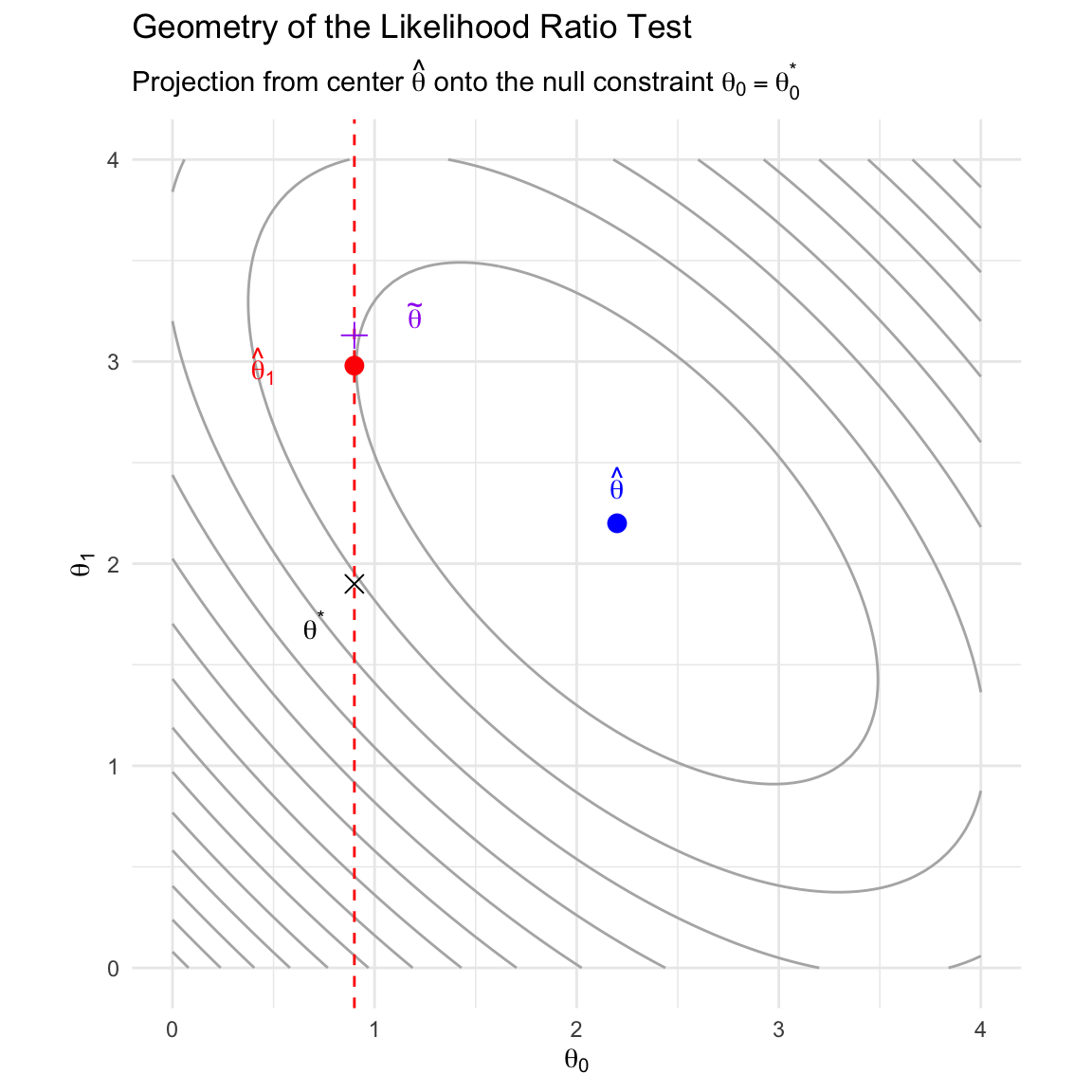
Finally, define the Projection Point (\(\tilde{x}\)) as the point where \(x\) projects exactly onto the regression surface: \(\tilde{x} = (x_0, \tilde{x}_1)^T\), where \(\tilde{x}_1 = \mu_{1|0}(x_0)\).
Lemma 6.1 (Fundamental Orthogonal Decomposition Lemma) Any deviation from the center, \((x - \mu)\), can be expressed as the sum of a conditional residual vector \((x - \tilde{x})\) and a marginal projection vector \((\tilde{x} - \mu)\).
These two vectors are strictly orthogonal with respect to the precision matrix \(\Sigma^{-1}\): \[
(x - \tilde{x})^T \Sigma^{-1} (\tilde{x} - \mu) = 0
\]
Furthermore, the joint Mahalanobis distances of these individual vectors perfectly isolate the conditional and marginal spaces:
- \((x - \tilde{x})^T \Sigma^{-1} (x - \tilde{x}) = D^2(x_1, \tilde{x}_1, \Sigma_{1|0})\)
- \((\tilde{x} - \mu)^T \Sigma^{-1} (\tilde{x} - \mu) = D^2(x_0, \mu_0, \Sigma_{00})\)
Proof. Proof via Block Factorization
We can express the partitioned covariance matrix \(\Sigma\) using a block \(LDL^T\) factorization. The precision matrix is then \(\Sigma^{-1} = (L^{-1})^T D^{-1} L^{-1}\), where:
\[
L^{-1} = \begin{pmatrix} I & 0 \\ -\Sigma_{10}\Sigma_{00}^{-1} & I \end{pmatrix}, \quad D^{-1} = \begin{pmatrix} \Sigma_{00}^{-1} & 0 \\ 0 & \Sigma_{1|0}^{-1} \end{pmatrix}
\]
Evaluating Mahalanobis inner products with \(\Sigma^{-1}\) is equivalent to applying the shearing transformation \(L^{-1}\) to the vectors, and then taking their inner product with respect to the block-diagonal metric \(D^{-1}\). Let us evaluate the transformed vectors for the residual \(u = (x - \tilde{x})\) and the projection \(v = (\tilde{x} - \mu)\).
- Transforming the Residual Vector (\(L^{-1}u\)):
\[
L^{-1} (x - \tilde{x}) = \begin{pmatrix} I & 0 \\ -\Sigma_{10}\Sigma_{00}^{-1} & I \end{pmatrix} \begin{pmatrix} 0 \\ x_1 - \tilde{x}_1 \end{pmatrix} = \begin{pmatrix} 0 \\ x_1 - \tilde{x}_1 \end{pmatrix}
\] The transformation leaves the residual vector unchanged; it lies entirely in the conditional subspace.
- Transforming the Projection Vector (\(L^{-1}v\)):
\[
L^{-1} (\tilde{x} - \mu) = \begin{pmatrix} I & 0 \\ -\Sigma_{10}\Sigma_{00}^{-1} & I \end{pmatrix} \begin{pmatrix} x_0 - \mu_0 \\ \Sigma_{10}\Sigma_{00}^{-1}(x_0 - \mu_0) \end{pmatrix} = \begin{pmatrix} x_0 - \mu_0 \\ 0 \end{pmatrix}
\] The transformation cleanly removes the induced correlation, flattening the projection vector so it lies entirely in the marginal subspace.
Evaluating the Inner Products: Because \(D^{-1}\) is block-diagonal, the inner product of these transformed vectors is simply the sum of the inner products of their corresponding blocks:
\[
(x - \tilde{x})^T \Sigma^{-1} (\tilde{x} - \mu) = \begin{pmatrix} 0 \\ x_1 - \tilde{x}_1 \end{pmatrix}^T \begin{pmatrix} \Sigma_{00}^{-1} & 0 \\ 0 & \Sigma_{1|0}^{-1} \end{pmatrix} \begin{pmatrix} x_0 - \mu_0 \\ 0 \end{pmatrix} = 0 + 0 = 0
\] This proves strict orthogonality.
Applying the same logic to the self-inner products evaluates the quadratic forms: \[
(x - \tilde{x})^T \Sigma^{-1} (x - \tilde{x}) = \begin{pmatrix} 0 \\ x_1 - \tilde{x}_1 \end{pmatrix}^T \begin{pmatrix} \Sigma_{00}^{-1} & 0 \\ 0 & \Sigma_{1|0}^{-1} \end{pmatrix} \begin{pmatrix} 0 \\ x_1 - \tilde{x}_1 \end{pmatrix} = (x_1 - \tilde{x}_1)^T \Sigma_{1|0}^{-1} (x_1 - \tilde{x}_1)
\] \[
(\tilde{x} - \mu)^T \Sigma^{-1} (\tilde{x} - \mu) = \begin{pmatrix} x_0 - \mu_0 \\ 0 \end{pmatrix}^T \begin{pmatrix} \Sigma_{00}^{-1} & 0 \\ 0 & \Sigma_{1|0}^{-1} \end{pmatrix} \begin{pmatrix} x_0 - \mu_0 \\ 0 \end{pmatrix} = (x_0 - \mu_0)^T \Sigma_{00}^{-1} (x_0 - \mu_0)
\] which yields exactly \(D^2(x_1, \tilde{x}_1, \Sigma_{1|0})\) and \(D^2(x_0, \mu_0, \Sigma_{00})\), respectively.
Theorem 6.1 (The Generalized Pythagorean Decomposition for Mahalanobis Distance) For any point \(x\), the total joint squared Mahalanobis distance from \(x\) to the center \(\mu\) decomposes precisely into the sum of the squared distances between \(x\) and its projection \(\tilde{x}\) (the Conditional Residual), and between \(\tilde{x}\) and the center \(\mu\) (the Marginal Projection):
\[
D^2(x, \mu, \Sigma) = D^2(x, \tilde{x}, \Sigma) + D^2(\tilde{x}, \mu, \Sigma)
\]
which, mapping to the marginal and conditional subspaces, is equivalent to:
\[
D^2(x, \mu, \Sigma) = D^2(x_1, \tilde{x}_1, \Sigma_{1|0}) + D^2(x_0, \mu_0, \Sigma_{00})
\]
Proof. Proof
We construct the vector from the origin to the target as the sum of the residual and the projection: \[
x - \mu = (x - \tilde{x}) + (\tilde{x} - \mu)
\]
We evaluate the total joint distance by expanding the quadratic form: \[
D^2(x, \mu, \Sigma) = \Big( (x - \tilde{x}) + (\tilde{x} - \mu) \Big)^T \Sigma^{-1} \Big( (x - \tilde{x}) + (\tilde{x} - \mu) \Big)
\]
\[
= (x - \tilde{x})^T \Sigma^{-1} (x - \tilde{x}) + (\tilde{x} - \mu)^T \Sigma^{-1} (\tilde{x} - \mu) + 2 (x - \tilde{x})^T \Sigma^{-1} (\tilde{x} - \mu)
\]
By the Fundamental Orthogonal Decomposition Lemma, the cross-term evaluates to zero due to orthogonality, leaving only the isolated quadratic forms:
\[
D^2(x, \mu, \Sigma) = (x - \tilde{x})^T \Sigma^{-1} (x - \tilde{x}) + (\tilde{x} - \mu)^T \Sigma^{-1} (\tilde{x} - \mu)
\]
This is exactly \(D^2(x, \tilde{x}, \Sigma) + D^2(\tilde{x}, \mu, \Sigma)\). Furthermore, as established by the Lemma, substituting the subspace identities for these two terms yields \(D^2(x_1, \tilde{x}_1, \Sigma_{1|0}) + D^2(x_0, \mu_0, \Sigma_{00})\).
Interactive Illustration
#| '!! shinylive warning !!': |
#| shinylive does not work in self-contained HTML documents.
#| Please set `embed-resources: false` in your metadata.
#| standalone: true
#| viewerHeight: 750
#| echo: false
#| column: screen
#| label: fig-MD-decomp-unified
library(shiny)
library(ggplot2)
ui <- fluidPage(
titlePanel("Pythagorean Decomposition of Mahalanobis Distance"),
# A relative container holding the plot and absolute panels
div(style = "position: relative;",
plotOutput("distPlot", height = "700px", width = "100%"),
# Floating Control Panel (Top Left)
absolutePanel(
top = 10, left = 10, width = 320, draggable = TRUE,
style = "background-color: rgba(255, 255, 255, 0.85); padding: 10px 15px; border-radius: 8px; border: 1px solid #ccc; box-shadow: 2px 2px 10px rgba(0,0,0,0.1);",
h4("Parameters", style = "margin-top: 0; margin-bottom: 10px; font-size: 16px;"),
fluidRow(
column(6, sliderInput("mu_0", "\\(\\mu_0\\)", min = 0, max = 5, value = 2.2, step = 0.1, ticks = FALSE)),
column(6, sliderInput("mu_1", "\\(\\mu_1\\)", min = 0, max = 5, value = 2.2, step = 0.1, ticks = FALSE))
),
fluidRow(
column(6, sliderInput("x_0", "\\(x_0\\)", min = 0, max = 5, value = 0.9, step = 0.1, ticks = FALSE)),
column(6, sliderInput("x_1", "\\(x_1\\)", min = 0, max = 5, value = 1.9, step = 0.1, ticks = FALSE))
),
hr(style = "margin: 5px 0; border-top: 1px solid #ddd;"),
fluidRow(
column(6, sliderInput("sigma_0", "\\(\\sigma_0\\)", min = 0.5, max = 3, value = 1.25, step = 0.05, ticks = FALSE)),
column(6, sliderInput("sigma_1", "\\(\\sigma_1\\)", min = 0.5, max = 3, value = 1.25, step = 0.05, ticks = FALSE))
),
sliderInput("rho", "Correlation \\(\\rho\\)", min = -0.95, max = 0.95, value = -0.6, step = 0.05, ticks = FALSE)
),
# Floating Legend Panel (Bottom Right)
absolutePanel(
bottom = 20, right = 20, width = 340, draggable = TRUE,
style = "background-color: rgba(255, 255, 255, 0.9); padding: 10px; border-radius: 8px; border: 1px solid #ccc; box-shadow: 2px 2px 10px rgba(0,0,0,0.1);",
uiOutput("legendUI")
)
)
)
server <- function(input, output, session) {
# Reactive calculations
calc_data <- reactive({
mu <- c(input$mu_0, input$mu_1)
x <- c(input$x_0, input$x_1)
# Construct Covariance Matrix
Sigma <- matrix(c(
input$sigma_0^2,
input$rho * input$sigma_0 * input$sigma_1,
input$rho * input$sigma_0 * input$sigma_1,
input$sigma_1^2
), nrow = 2)
Sigma_inv <- solve(Sigma)
# Marginal and Conditional variances
Sigma_00 <- Sigma[1, 1]
Sigma_1given0 <- Sigma[2, 2] - (Sigma[1, 2]^2) / Sigma[1, 1]
# Conditional Mean
mu_1given0 <- mu[2] + (Sigma[1, 2] / Sigma[1, 1]) * (x[1] - mu[1])
# Projected Point p = \tilde{x} = (x_0, \mu_{1|0}(x_0))
x_tilde <- c(x[1], mu_1given0)
# Calculate Distances
diff_total <- x - mu
d2_total <- as.numeric(t(diff_total) %*% Sigma_inv %*% diff_total)
# By theorem, marginal maps to D^2(\tilde{x}, \mu, \Sigma)
d2_marg <- (x[1] - mu[1])^2 / Sigma_00
# By theorem, conditional maps to D^2(x, \tilde{x}, \Sigma)
d2_cond <- (x[2] - mu_1given0)^2 / Sigma_1given0
list(mu = mu, x = x, x_tilde = x_tilde, Sigma = Sigma, Sigma_inv = Sigma_inv,
d2_total = d2_total, d2_marg = d2_marg, d2_cond = d2_cond)
})
output$legendUI <- renderUI({
res <- calc_data()
withMathJax(
HTML(paste0(
"<div style='font-size: 14px;'>",
"<b>Distance Legend</b><br><br>",
"<span style='color: black;'><b>Total:</b> \\( D^2(x, \\mu, \\Sigma) = \\) ", round(res$d2_total, 2), "</span><br>",
"<span style='color: blue;'><b>Marginal:</b> \\( D^2(\\tilde{x}, \\mu, \\Sigma) = \\) ", round(res$d2_marg, 2), "</span><br>",
"<span style='color: red;'><b>Conditional:</b> \\( D^2(x, \\tilde{x}, \\Sigma) = \\) ", round(res$d2_cond, 2), "</span>",
"</div>"
))
)
})
output$distPlot <- renderPlot({
res <- calc_data()
mu <- res$mu; x <- res$x; x_tilde <- res$x_tilde; Sigma <- res$Sigma; Sigma_inv <- res$Sigma_inv
# Generate grid for quadratic contours (extended for fixed bounds)
grid_vals <- seq(-2, 7, length.out = 100)
grid <- expand.grid(x0 = grid_vals, x1 = grid_vals)
grid$z <- apply(grid, 1, function(row) {
diff <- row - mu
as.numeric(t(diff) %*% Sigma_inv %*% diff)
})
# Regression surface line parameters
slope <- Sigma[1, 2] / Sigma[1, 1]
intercept <- mu[2] - slope * mu[1]
# Midpoints for labels
mid_marg <- (mu + x_tilde) / 2
mid_cond <- (x_tilde + x) / 2
mid_total <- (mu + x) / 2
ggplot(grid, aes(x = x0, y = x1)) +
# Contours
geom_contour(aes(z = z), bins = 25, color = "gray85") +
# The Regression Surface (Light Blue Line extending across plot)
geom_abline(intercept = intercept, slope = slope, color = "lightblue", linewidth = 2, alpha = 0.5) +
# The Distance Segments
geom_segment(aes(x = mu[1], y = mu[2], xend = x_tilde[1], yend = x_tilde[2]), color = "blue", linewidth = 1.2) +
geom_segment(aes(x = x_tilde[1], y = x_tilde[2], xend = x[1], yend = x[2]), color = "red", linewidth = 1.2) +
geom_segment(aes(x = mu[1], y = mu[2], xend = x[1], yend = x[2]), color = "black", linetype = "dashed", linewidth = 1) +
# Labels on Segments using unified notation
annotate("text", x = mid_marg[1] + 0.25, y = mid_marg[2] - 0.25, label = "D^2*(list(tilde(x), mu, Sigma))", parse = TRUE, color = "blue", size = 5) +
annotate("text", x = mid_cond[1] + 0.35, y = mid_cond[2], label = "D^2*(list(x, tilde(x), Sigma))", parse = TRUE, color = "red", size = 5) +
annotate("text", x = mid_total[1] - 0.25, y = mid_total[2] + 0.25, label = "D^2*(list(x, mu, Sigma))", parse = TRUE, color = "black", size = 5) +
# Points and their labels
annotate("point", x = mu[1], y = mu[2], color = "blue", size = 4) +
annotate("text", x = mu[1] - 0.2, y = mu[2] + 0.2, label = "mu", parse = TRUE, color = "blue", size = 6) +
annotate("point", x = x_tilde[1], y = x_tilde[2], color = "purple", shape = 3, size = 4, stroke = 2) +
annotate("text", x = x_tilde[1] + 0.3, y = x_tilde[2] - 0.2, label = "tilde(x)", parse = TRUE, color = "purple", size = 6) +
annotate("point", x = x[1], y = x[2], color = "black", shape = 4, size = 4, stroke = 2) +
annotate("text", x = x[1] - 0.15, y = x[2] + 0.2, label = "x", parse = TRUE, size = 6) +
# Strict Fixed Coordinates to prevent re-shaping
coord_fixed(xlim = c(-1, 6), ylim = c(-1, 6), expand = FALSE) +
labs(x = expression(x[0]), y = expression(x[1])) +
theme_minimal(base_size = 16) +
theme(panel.grid.minor = element_blank())
})
}
shinyApp(ui, server)