We begin with observations (units) \(X_1, X_2, \dots, X_n\). These may be vectors. We regard these observations as a realization of random variables.
Definition 1.1 (Population Distribution) We assume that \(X_1, X_2, \dots, X_n \sim f(x)\). The function \(f(x)\) is called the population distribution.
Assumptions and Scope
For simplicity, we often assume the data are Independent and Identically Distributed (i.i.d.). The assumption of identical distribution can be relaxed to regression settings in which the distributions of \(x_i\)’s are independent but dependent on covariate \(x_i\).
In Parametric Statistics, we assume \(f(x)\) is of a known analytic form but involves unknown parameters.
Example 1.1 (Parametric Model: Normal) Consider the Normal distribution: \[f(x; \theta) = \frac{1}{\sqrt{2\pi\sigma^2}} e^{-\frac{(x-\mu)^2}{2\sigma^2}}\] Here, the parameter space is \(\Theta = \{ (\mu, \sigma^2) : \mu \in \mathbb{R}, \sigma \in [0, +\infty) \}\). The goal is to learn aspects of the unknown \(\theta\) from observations \(X_1, \dots, X_n\).
Example 1.2 (Parametric Model: Bernoulli) Consider a sequence of binary outcomes (e.g., Success/Failure) where each \(X_i \in \{0, 1\}\). We assume \(X_i \sim \text{Bernoulli}(\theta)\). The probability mass function is: \[f(x; \theta) = \theta^x (1-\theta)^{1-x}\] Here, the parameter space is \(\Theta = [0, 1]\), where \(\theta\) represents the probability of success.
1.2 Probabilistic Model vs. Statistical Inference
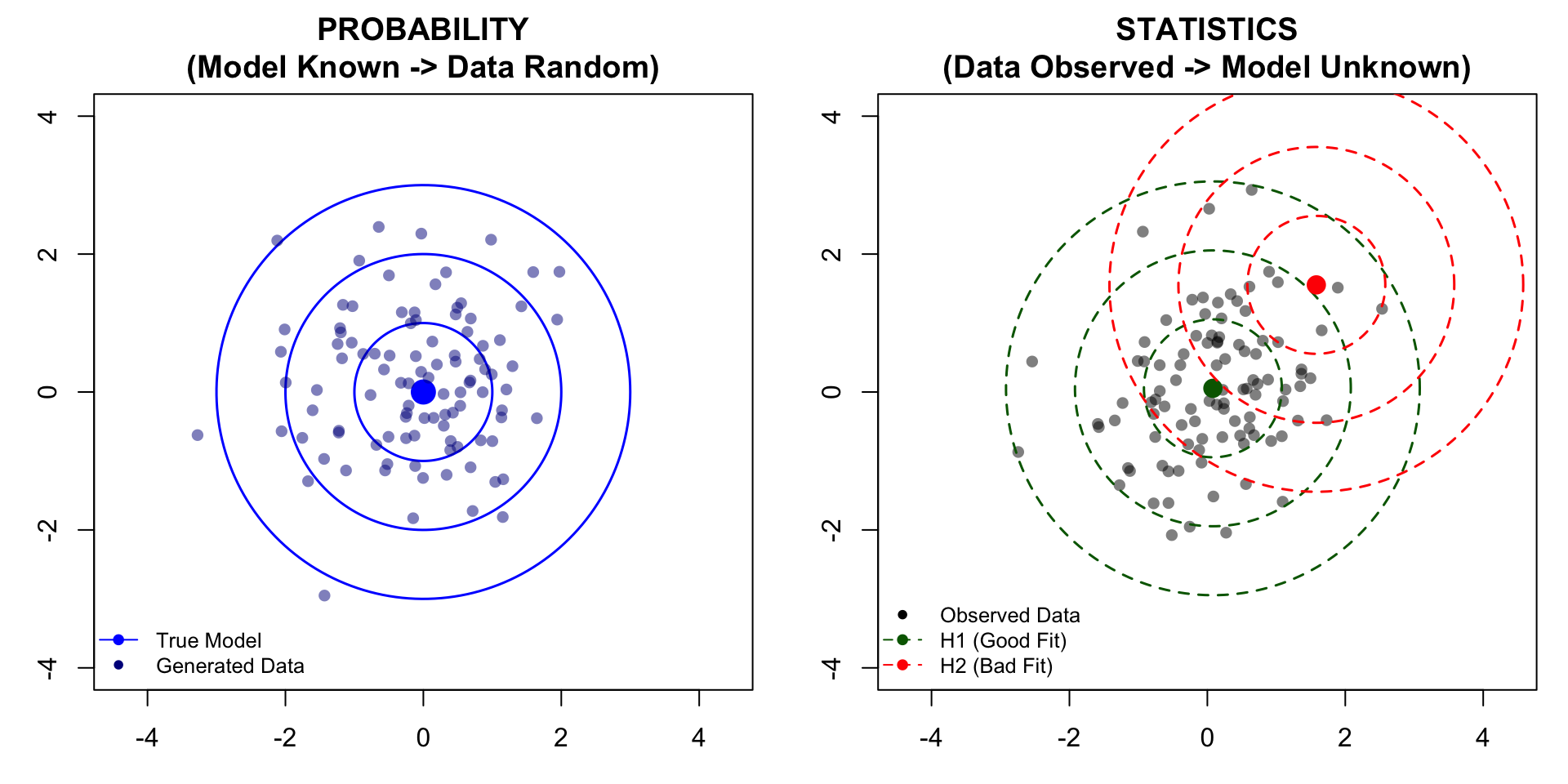
There is a fundamental distinction between probability and statistics regarding the parameter \(\theta\). We can visualize this using a “shooting target” analogy:
\(\theta\) (The Center): The true, unknown bullseye location.
\(x\) (The Shots): The observed holes on the target board.
Probability (Deductive): The center \(\theta\) is known. We predict where the shots \(x\) will land.
Statistics (Inductive): The shots \(x\) are observed on the board. The center \(\theta\) is unknown. We hypothesize different potential centers to see which one best explains the shots.
Code
# --- Setup ---set.seed(2024)n_sim <-100# Helper function to draw circles in base Rdraw_circle <-function(x, y, r, col, lty =1, lwd =1) { theta <-seq(0, 2* pi, length.out =200)lines(x + r *cos(theta), y + r *sin(theta), col = col, lty = lty, lwd = lwd)}# Layout: 1 row, 2 columns# mar: c(bottom, left, top, right) - decreasing margins to trim spacepar(mfrow =c(1, 2), mar =c(3, 3, 3, 1))# ---------------------------------------------------------# PLOT 1: PROBABILITY (The Generator)# ---------------------------------------------------------# 1. Generate Datax_prob <-rnorm(n_sim)y_prob <-rnorm(n_sim)# 2. Setup Canvas (asp=1 ensures circles look like circles)plot(NA, xlim =c(-4, 4), ylim =c(-4, 4), asp =1,xlab ="", ylab ="", main ="PROBABILITY\n(Model Known -> Data Random)")# 3. Draw Model (True Center & Contours)points(0, 0, pch =19, col ="blue", cex =2)for(r in1:3) draw_circle(0, 0, r, col ="blue", lwd =1.5)# 4. Draw Generated Datapoints(x_prob, y_prob, pch =16, col =adjustcolor("darkblue", alpha =0.5))# 5. Legendlegend("bottomleft", legend =c("True Model", "Generated Data"),col =c("blue", "darkblue"), pch =c(19, 16),lty =c(1, 0), bty ="n", cex =0.8)# ---------------------------------------------------------# PLOT 2: STATISTICS (The Inference)# ---------------------------------------------------------# 1. Generate NEW Observed Datax_stat <-rnorm(n_sim)y_stat <-rnorm(n_sim)x_bar <-mean(x_stat)y_bar <-mean(y_stat)# 2. Setup Canvasplot(NA, xlim =c(-4, 4), ylim =c(-4, 4), asp =1,xlab ="", ylab ="", main ="STATISTICS\n(Data Observed -> Model Unknown)")# 3. Draw Observed Datapoints(x_stat, y_stat, pch =16, col =adjustcolor("black", alpha =0.5))# 4. Draw Hypothesis 1 (Good Fit - Centered at Sample Mean)points(x_bar, y_bar, pch =19, col ="darkgreen", cex =1.5)for(r in1:3) draw_circle(x_bar, y_bar, r, col ="darkgreen", lty =2, lwd =1.5)# 5. Draw Hypothesis 2 (Bad Fit - Shifted)points(x_bar +1.5, y_bar +1.5, pch =19, col ="red", cex =1.5)for(r in1:3) draw_circle(x_bar +1.5, y_bar +1.5, r, col ="red", lty =2, lwd =1.5)# 6. Legendlegend("bottomleft", legend =c("Observed Data", "H1 (Good Fit)", "H2 (Bad Fit)"),col =c("black", "darkgreen", "red"), pch =c(16, 19, 19), lty =c(0, 2, 2), bty ="n", cex =0.8)
Figure 1.1: Probability vs Statistics. Left: Probability—The model is fixed (Blue center/contours), generating random data. Right: Statistics—Data is fixed (Black points); we test two hypothesized models: H1 (Green) centered at the sample mean (Good Fit) and H2 (Red) shifted by (1.5, 1.5) (Bad Fit).
1.3 A Motivating Example: The Lady Tasting Tea
To illustrate the concepts of statistical inference, we consider the famous experiment described by R.A. Fisher.
A lady claims she can distinguish whether milk was poured into the cup before or after the tea. To test this claim, we prepare \(n\) cups of tea.
Random Variable: Let \(X_i=1\) if she identifies the cup correctly, and \(0\) otherwise.
Parameter: Let \(\theta\) be the probability that she correctly identifies a cup.
The Data: Suppose we observe that she identifies 70% of cups correctly (\(\bar{x} = 0.7\)), which is a summary of the observed vector of \(x_i\), for example,
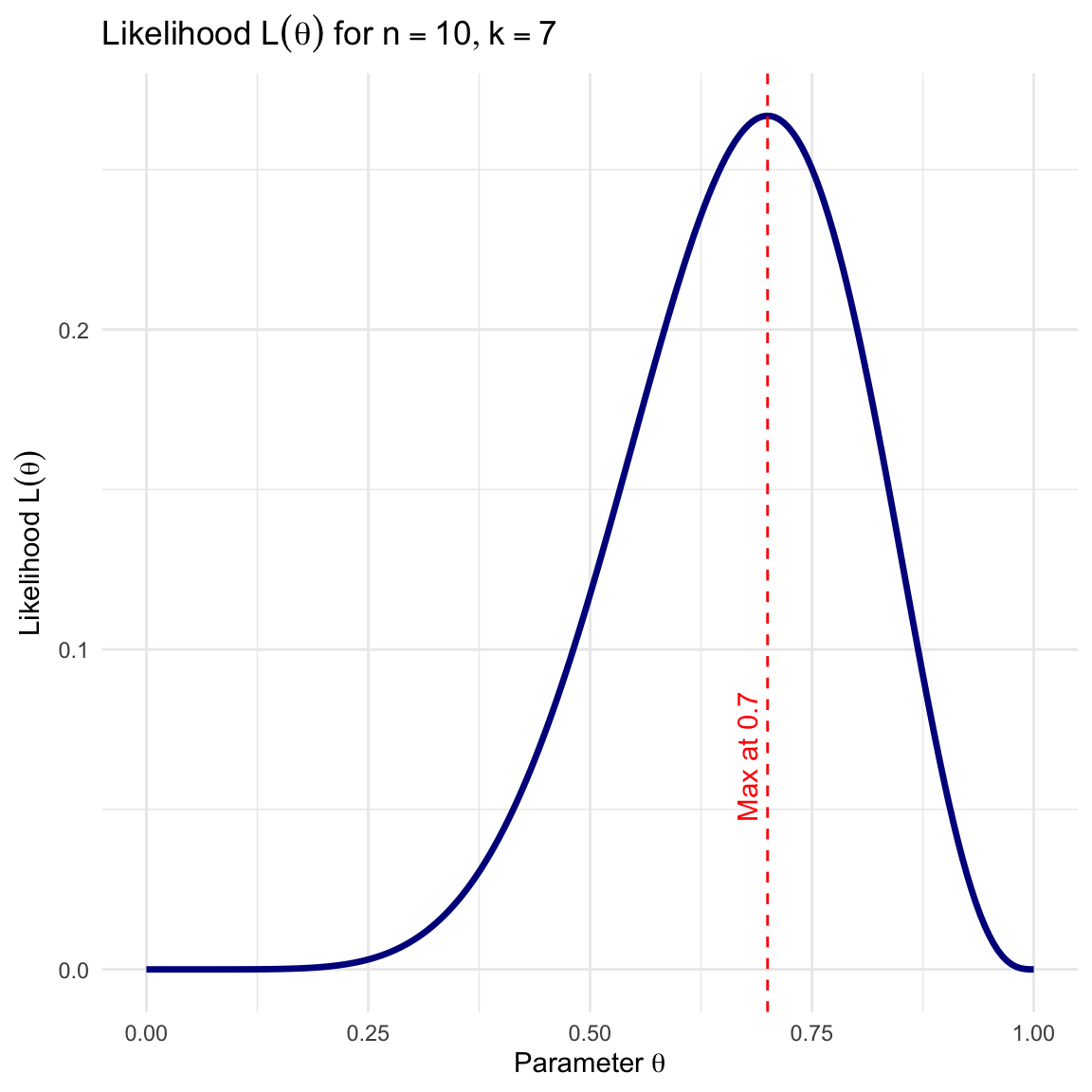
We observe 7 out of 10 correct (\(k=7\)). \[\bar{x} = 0.7\]
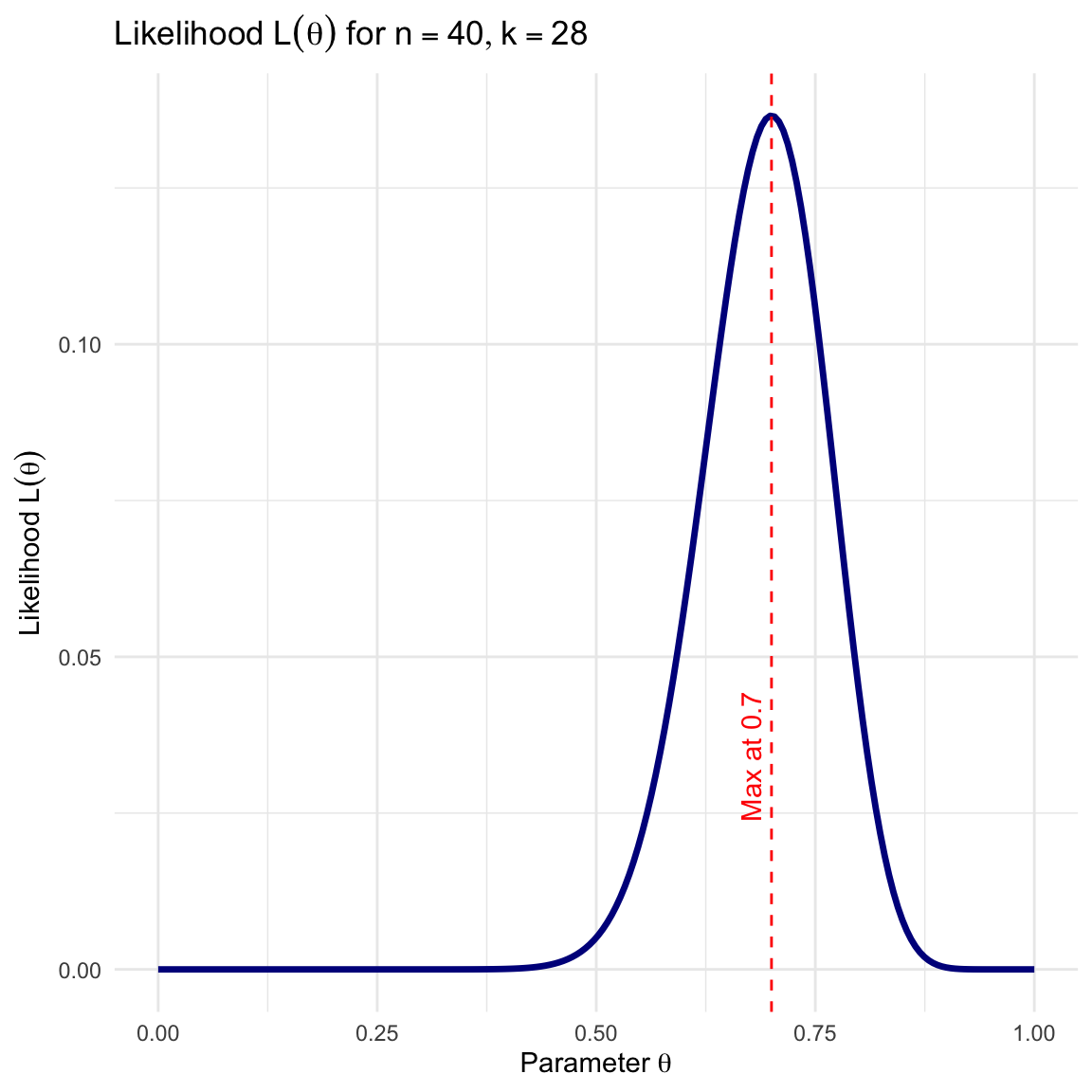
We observe 28 out of 40 correct (\(k=28\)). \[\bar{x} = 0.7\]
1.4 Questions to Answer in Statistical Inference
Using this example, we identify the four main types of statistical inference.
Point Estimation
We want to use a single number to capture the parameter: \(\hat{\theta} = \theta(X_1, \dots, X_n)\).
Tea Example: Our best guess for her success rate is \(\hat{\theta} = 0.7\).
Hypothesis Testing
We want to test a theory about the parameter: \(H_0\) vs \(H_1\).
Tea Example: Is she just guessing? We test \(H_0: \theta = 0.5\) vs \(H_1: \theta > 0.5\).
Model Assessment
We want to test a theory about the parameter: \(H_0\) vs \(H_1\).
Example: Can we use a reduced model? What level of complexity of \(f(x; \theta)\) is necessary?
Interval Estimation
We want to construct an interval likely to contain the parameter: \(\theta \in (L, U)\).
Tea Example: We might say her true skill \(\theta\) is likely between \(0.45\) and \(0.95\).
Prediction
We want to predict a new observation \(Y_{n+1}\) given previous data.
Tea Example: If we give her an \((n+1)\)-th cup, what is the probability she identifies it correctly?
1.5 The Likelihood Function
The bridge between probability and statistics is the Likelihood Function.
Definition 1.2 (Likelihood Function) Let \(f(x_1, \dots, x_n; \theta)\) be the joint probability density (or mass) function of the data given the parameter \(\theta\). When we view this function as a function of \(\theta\) for fixed observed data \(x_1, \dots, x_n\), we call it the likelihood function, denoted \(L(\theta)\). \[L(\theta) = f(x_1, \dots, x_n; \theta)\]
Example: Lady Tasting Tea
For our Tea Tasting data, the likelihood is proportional to the Binomial probability: \[L(\theta) = \binom{n}{k} \theta^k (1-\theta)^{n-k}\]
Here, \(L(\theta) = \binom{40}{28} \theta^{28} (1-\theta)^{12}\). Notice how the likelihood becomes narrower (more peaked) with more data, even though the peak remains at 0.7.
Is an estimator like \(\bar x\), which is called Maximum Likelihood Estimator (MLE), a good estimator in general?
What do you discover from actually observing the two likelihood unctions of different sample size \(n\)?
Is the likelihood function central to all inference problems?
What are the essential ‘parameters’ of the likelihood function?
There are two primary frameworks for “How” to perform these inferences.
1.6 Frequentist Inference
Concept:\(\theta\) is unknown but fixed; Data \(X\) is random.
Sampling Distribution: We analyze how \(\hat{\theta}\) behaves under hypothetical repeated sampling.
Example: Frequentist Test of Lady Tasting Tea
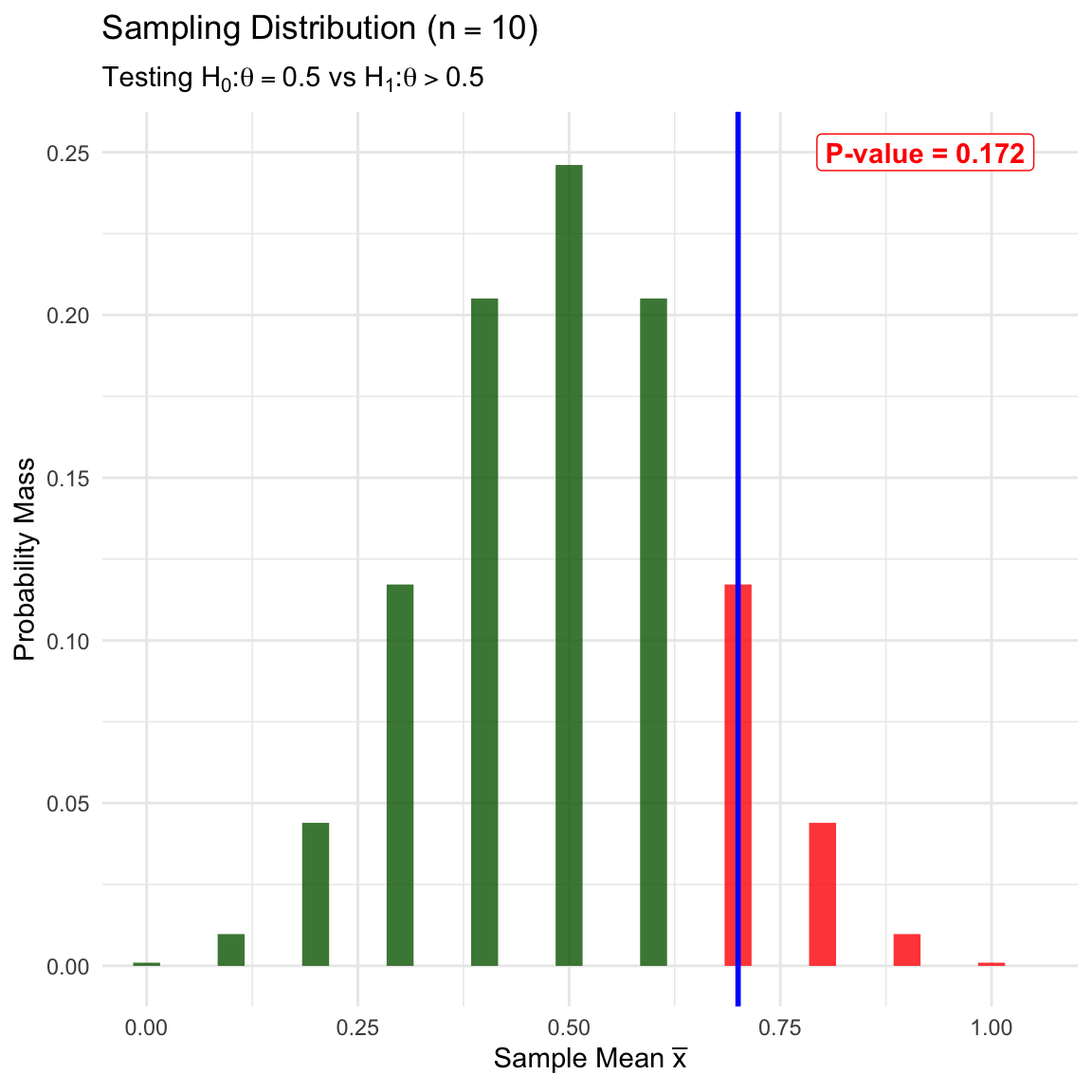
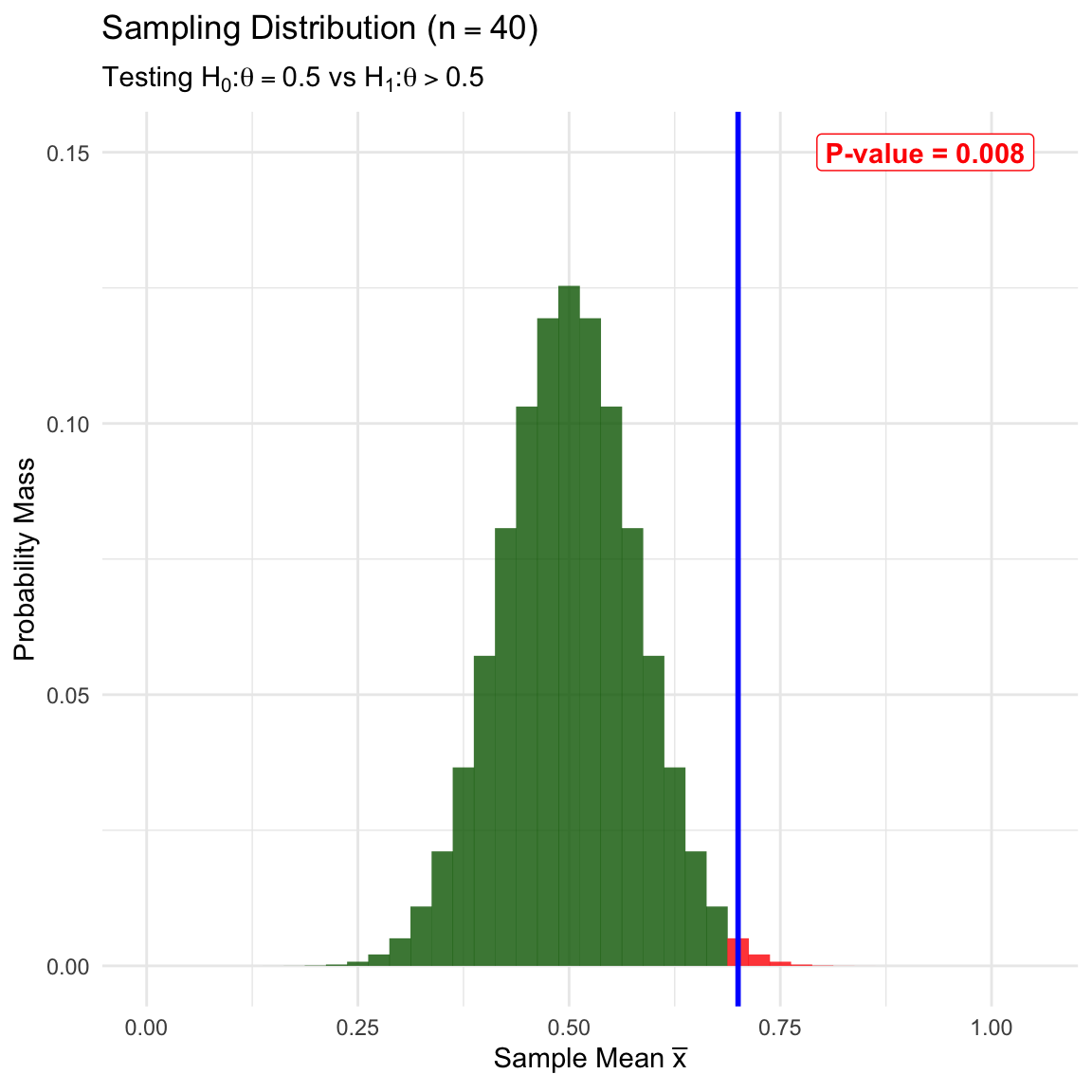
We test \(H_0: \theta=0.5\) (Guessing) vs \(H_1: \theta > 0.5\) (Skill). We analyze the behavior of \(\bar{X}\) assuming \(H_0\) is true. The rejection region (one-sided) is shaded red.
We calculate the P-value: Probability of observing \(\ge 28\) correct out of 40. With a larger sample size, the same proportion (0.7) provides stronger evidence against the null.
In this course, we will answer several challenging questions related to general parametric models in the Frequentist framework.
MLE: Can we use the Maximum Likelihood Estimator (MLE) \(\hat{\theta}\) for general models even no closed-form solution exists? Is MLE a good method?
Sampling Distributions: What is the distribution of \(\hat{\theta}_{\text{MLE}}\)? What’s its mean and standard deviation?
Confidence Intervals: How to construct CI with \(\hat{\theta}\)?
Hypothesis Testing: How do we derive powerful tests from the likelihood function? How to assess goodness-of-fit of parametric models with their likelhiood information?
1.7 Bayesian Inference
Concept:\(\theta\) is regarded as a random variable.
We will also tackle the specific technical challenges involved in Bayesian analysis.
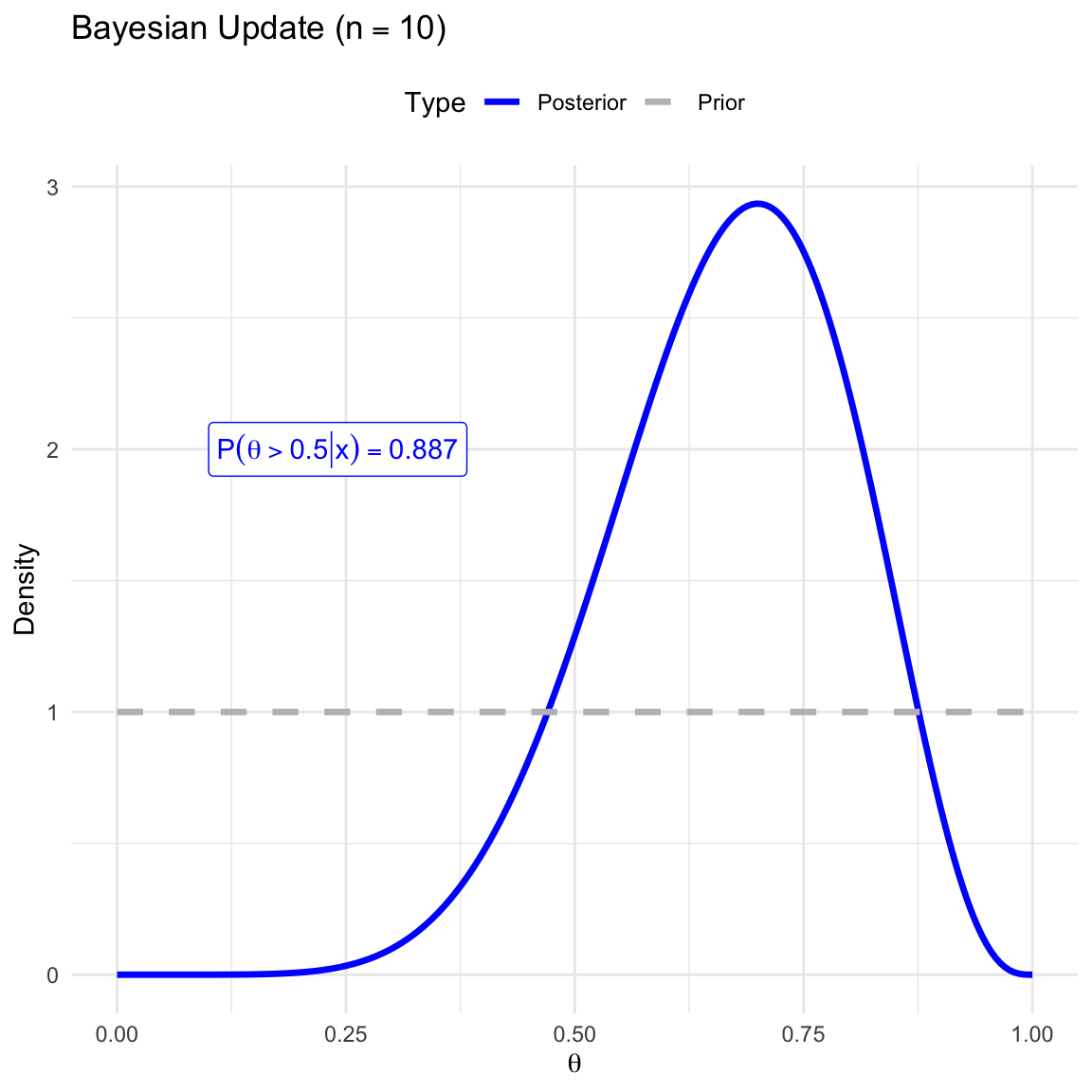
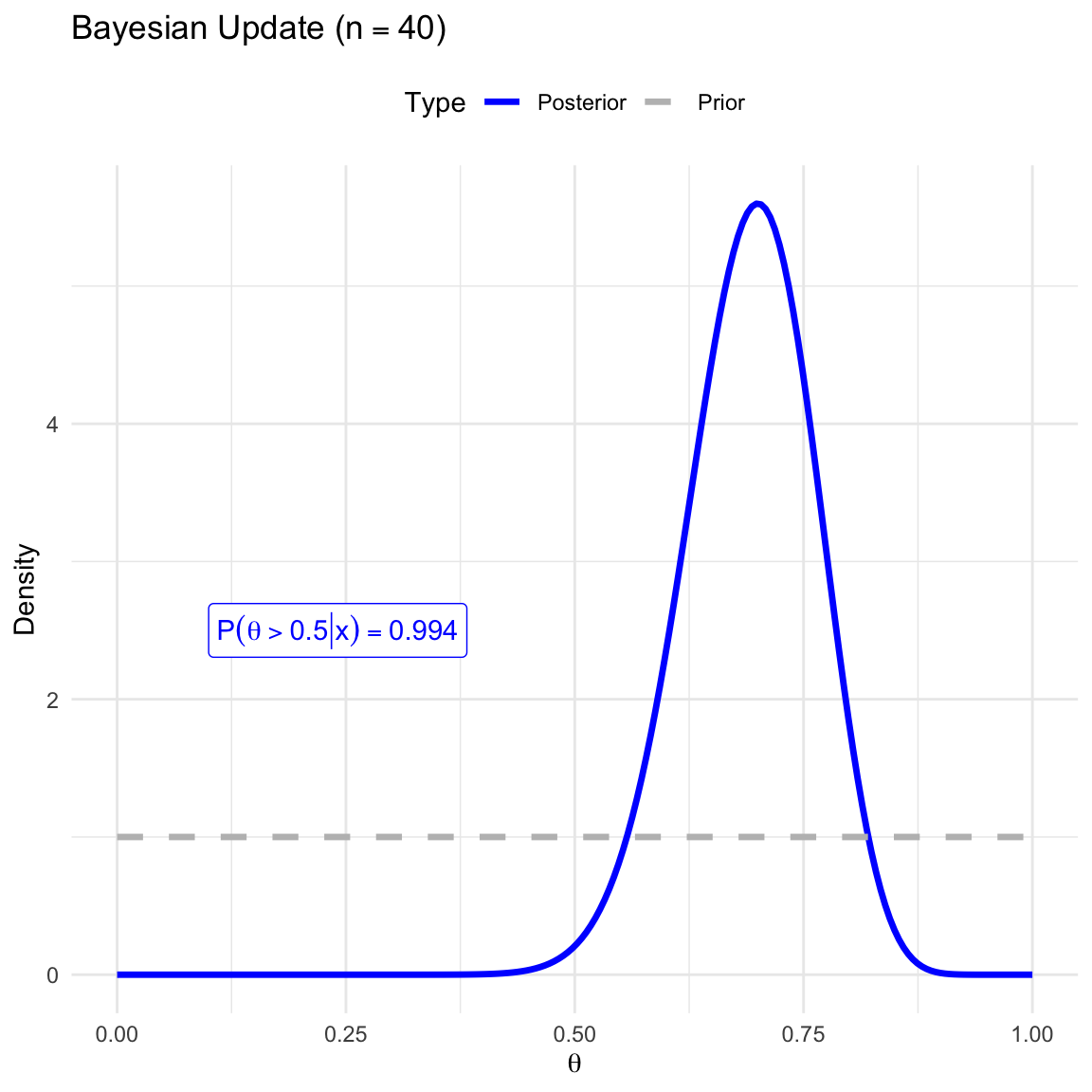
Posterior Derivation: How do we derive the posterior distribution \(f(\theta|x)\) for various likelihoods and priors?
Comparing with Other methods: Are Bayesain methods good or not or general inference?
Computation: When the posterior cannot be derived analytically, how do we use computational techniques like Markov Chain Monte Carlo (MCMC) to sample from it?
Summarization: How do we construct Credible Intervals (e.g., Highest Posterior Density regions) from posterior samples?
Prediction: How do we solve the integral required to compute the posterior predictive distribution for future data?
Prior: How to choose our prior? What’s its effect on our inference?
Model Comparison and Assessment: How to assess a Bayesian model?