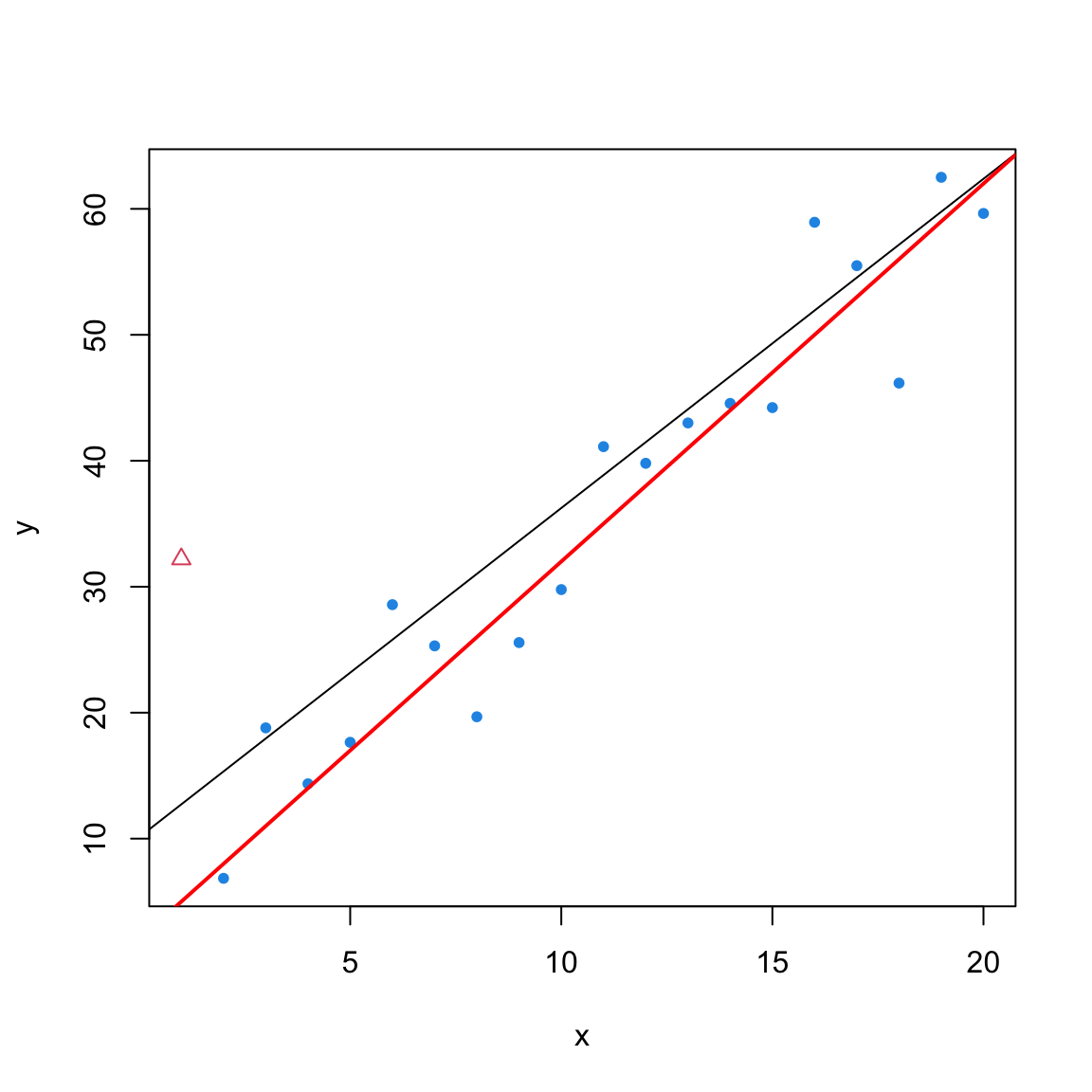
Note: this html contains materials for understanding residuals not the techniques that students need to master.
5.2 Introduction
In statistical modeling, identifying data points that don’t fit—the outliers—is a critical step. The most reliable tool for this job is the externally studentized residual. Its power comes from a simple, intuitive idea: to judge a point fairly, you shouldn’t use that point when building your model. This is the core principle of Leave-One-Out Cross-Validation (LOOCV).
This article provides a complete walkthrough of this essential concept. We’ll start with the basic linear model, introduce the necessary notation, explore the flaws of simpler residuals, and then formally define and prove the equivalence of the conceptual and computational formulas for studentized residuals. Finally, we’ll make it all concrete with a simple example.
5.3 The Linear Model
Our discussion is based on the standard multiple linear regression model. In matrix form, the relationship between a response vector Y and a predictor matrix X is: \[
\mathbf{Y} = \mathbf{X}\beta + \epsilon
\]
where:
Y is an n x 1 vector of the observed outcomes.
X is the n x p design matrix of predictor variables (where p is the number of coefficients, including the intercept).
\(\beta\) is the p x 1 vector of unknown true coefficients we want to estimate.
\(\epsilon\) is an n x 1 vector of unobservable random errors, assumed to be independent and identically distributed with a mean of 0 and a variance of \(\sigma^2\).
5.4 Residuals for OLS
5.4.1 Our Notations
To discuss models fit with all data versus those with one point removed, we need clear notation.
Full Data Model (Using all n observations)
\(\hat{\beta}\): The estimated coefficient vector.
\(\hat{y}_i\): The predicted value for observation i from this model.
\(e_i\): The ordinary residual (\(e_i = y_i - \hat{y}_i\)).
\(\hat{\sigma}\): The estimated standard deviation of the errors (Residual Standard Error).
\(h_{ii}\): The leverage of observation i, a measure of how much its x-values influence the model.
Leave-One-Out (LOOCV) Model
\(\hat{\beta}_{-i}\): The coefficient vector estimated after removing observation i.
\(\hat{y}_{i,-i}\): The predicted value for observation i, from the model fit without observation i.
\(e_{i,-i}\): The deleted residual (\(e_{i,-i} = y_i - \hat{y}_{i,-i}\)).
\(\hat{\sigma}_{-i}\): The standard deviation of the errors estimated from the model fit without observation i.
5.4.2 Non-studentized Residuals
Before getting to the correct solution, it’s crucial to understand why simpler methods of standardizing residuals are flawed.
5.4.2.1The Ordinary Residual (\(e_i\)): Too Small and \(x_i\) Dependent
The most basic residual, \(e_i\), is problematic for two key reasons.
An outlier has an undue influence on the model, pulling the regression line towards itself. This makes its own predicted value, \(\hat{y}_i\), artificially close to its actual value, \(y_i\). As a result, its residual, \(e_i\), is deceptively small and doesn’t reflect the true magnitude of the error.
The variance of an ordinary residual is not constant; it depends on the point’s leverage. The variance can be derived from the hat matrix \(H = X(X^\top X)^{-1}X^\top\). Since \[\hat{y} = HY,\] we have \[\begin{equation}
e = (I - H)\epsilon.
\end{equation}\] Thus, \[\begin{equation}
\mathrm{Var}(e) = (I-H)\,\sigma^2\,(I-H)^\top = (I-H)\sigma^2.
\end{equation}\] Therefore, for the \(i\)th residual, \[\begin{equation}
\mathrm{Var}(e_i) = \sigma^2(1 - h_{ii}).
\end{equation}\]
Since leverage (\(h_{ii}\)) is always greater than 0, the variance of an ordinary residual is always less than the true error variance,\(\sigma^2\). High-leverage points act as “anchors” for the line and have even smaller variance.
5.4.2.2The LOOCV Residual (\(e_{i,-i}\)): Too large and \(x_i\)-Dependent Variance
The deleted residual, \(e_{i,-i}\), solves the “too small” problem. Because the model isn’t influenced by the point it’s predicting, the residual is an honest measure of prediction error. However, its variance is still not constant. The variance of a deleted residual also depends on leverage, but in the opposite way. \[\begin{equation}
\text{Var}(e_{i,-i}) = \frac{\sigma^2}{1 - h_{ii}}
\end{equation}\]
Since \(1-h_{ii}\) is less than 1, the variance of a deleted residual is always greater than the true error variance,\(\sigma^2\). This is because it has two sources of randomness: the error in the point itself (\(y_i\)) and the error in the prediction (\(\hat{y}_{i,-i}\)).
5.4.3 Studentized Residuals
5.4.3.1 Studentized LOOCV (Deleted) Residual
The correct solution is to take the LOOCV residual and divide it by its true standard error, which properly accounts for its larger, x-dependent variance. This is the externally studentized residual, \(t_i\), defined as follows:
\[
t_i = \frac{e_{i,-i}}{\text{SE}(e_{i,-i})} = \frac{e_{i,-i}}{\frac{\hat{\sigma}_{-i}}{\sqrt{1-h_{ii}}}}
\tag{5.1}\] This final value is a reliable diagnostic. Under the null hypothesis that the observation is not an outlier, it follows a Student’s t-distribution with \(n - p - 1\) degrees of freedom.
5.4.3.2 Studentized Full Data Residuals
Calculating the conceptual formula appears to require fitting n different regression models—a computationally expensive task. Fortunately, a mathematical identity allows us to calculate the exact same value using only the results from the single, full data model.
\[
t_i = \frac{e_i}{\hat{\sigma}_{-i}\sqrt{1 - h_{ii}}}
\tag{5.2}\] This is not an approximation; it is an exact algebraic rearrangement of the conceptual definition.
Let’s start with the conceptual definition of the studentized LOOCV residuals Equation 5.1 and show how it transforms into Equation 5.2.
Start with the conceptual LOOCV definition:\[\begin{equation}
t_i = \frac{e_{i,-i}}{\text{SE}(e_{i,-i})} = \frac{e_{i,-i}}{\frac{\hat{\sigma}_{-i}}{\sqrt{1-h_{ii}}}}
\end{equation}\]
Substitute the key identity into the numerator: \[\begin{equation}
t_i = \frac{\frac{e_i}{1 - h_{ii}}}{\frac{\hat{\sigma}_{-i}}{\sqrt{1 - h_{ii}}}}
\end{equation}\]
Simplify the complex fraction. We can do this by multiplying the numerator by the reciprocal of the denominator: \[\begin{equation}
t_i = \frac{e_i}{1-h_{ii}} \cdot \frac{\sqrt{1-h_{ii}}}{\hat{\sigma}_{-i}}
\end{equation}\]
Cancel the terms. Since \(1 - h_{ii} = (\sqrt{1 - h_{ii}})^2\), one of the \(\sqrt{1 - h_{ii}}\) terms in the denominator cancels with the term in the numerator. This leaves us with the computational shortcut formula: \[\begin{equation}
t_i = \frac{e_i}{\hat{\sigma}_{-i}\sqrt{1-h_{ii}}}
\end{equation}\]
This proves that the two formulas are mathematically identical. The computational shortcut is simply a clever algebraic rearrangement of the more intuitive LOOCV definition, allowing for efficient and accurate calculation. ✅
Of course. Here is the modified .qmd file with the standardized residual (which you’ve labeled STD-Full) added to the table, the descriptions, and the plot.
The main changes include:
Adding the STD-Full column to the residuals_df data frame using R’s rstandard() function.
Updating the list of calculated columns to include a description of STD-Full.
Modifying the plotting code to include STD-Full with its own distinct color and shape.
5.4.4 List of Residuals
In this article, we will compare the four residuals given as:
The simulation uses a simple linear regression model to describe the relationship between a single predictor variable, \(x_i\), and a response variable, \(y_i\). The underlying “true” model from which the data is generated is: \[y_i = 2 + 3x_i + \epsilon_i\] This means we have a true intercept of 2, a true slope of 3, and a random error term, \(\epsilon_i\), drawn from a normal distribution with a mean of 0 and a standard deviation of 5. One artificial outlier is added to this data to test the behavior of the different residual types. 5 unrelated predictors are added to the dataset.
The final table compiles several important quantities calculated during the simulation. Here’s what each column represents:
\(x_i\): The predictor variable, which is simply the index of the observation from 1 to 20.
\(h_i\): The leverage of the i-th observation. It measures how influential a point’s x-value is in determining the model’s fit. A higher value indicates a more influential point.
\(e_i\): The ordinary residual, calculated as the difference between the actual value (\(y_i\)) and the predicted value (\(\hat{y}_i\)) from the model fit on all data.
\(\hat{\sigma}\): The residual standard error (or Root Mean Square Error) of the full model, representing the typical size of an ordinary residual.
\(e_{i,-i}\): The deleted (or LOOCV) residual. This is the difference between the actual value (\(y_i\)) and the value predicted for it by a model that was fit on all other data except point i.
\(\hat{e}_{i,-i}\): This column shows the deleted residual calculated using the efficient algebraic shortcut (\(e_i / (1-h_{ii})\)), verifying it’s identical to the brute-force \(e_{i,-i}\).
\(\hat{\sigma}_{-i}\): The LOOCV residual standard error, calculated from a model that was fit after removing observation i.
\(\tilde{\sigma}_{-i}\): The LOOCV residual standard error, calculated from the shortcut formula ?eq-sigma_-i.
NS-Full: The Non-studentized Full-Data Residual, calculated as the ordinary residual divided by the full model’s standard error (\(e_i / \hat{\sigma}\)).
NS-LOO: The Non-studentized LOOCV Residual, calculated as the deleted residual divided by the corresponding LOOCV standard error (\(e_{i,-i} / \hat{\sigma}_{-i}\)).
STD-Full: The Standardized (or Internally Studentized) Residual, calculated as the ordinary residual divided by its estimated standard error (\(e_i / (\hat{\sigma}\sqrt{1-h_{ii}})\)). This is provided by R’s rstandard() function.
ST-LOO: The Studentized LOOCV Residual, calculated using the conceptual formula by dividing the deleted residual by its true standard error.
ST-Full: The Studentized Full-Data Residual, calculated using the efficient shortcut formula, which is provided by R’s rstudent() function.
## Load librarieslibrary(dplyr)library(tidyr)library(ggplot2)library(knitr)## -------------------------------## 3) Plotting Code with Updated Names## -------------------------------## Prepare data for plottingplot_df <- residuals_df %>%## Use the new, simple column names (R converts '-' to '.')select( x, NS.Full, NS.LOO, STD.Full, # <-- ADDED FOR PLOTTING ST.LOO, ST.Full ) %>%pivot_longer(cols =-x,names_to ="residual_type",values_to ="residual_value" )## Update the names in the mapping vectorsshape_map <-c(NS.Full =16, # solid circleNS.LOO =1, # hollow circleSTD.Full =2, # hollow triangle <-- ADDEDST.LOO =6, # asteriskST.Full =10# asterisk)labels_map <-c(NS.Full ="NS-Full",NS.LOO ="NS-LOO",STD.Full ="STD-Full", # <-- ADDEDST.LOO ="ST-LOO",ST.Full ="ST-Full")color_map <-c(NS.Full ="#1f77b4", # blueNS.LOO ="#ff7f0e", # orangeSTD.Full ="#9467bd", # purple <-- ADDEDST.LOO ="#2ca02c", # greenST.Full ="#d62728"# red)## Generate the plotggplot( plot_df,aes(x = x, y = residual_value,shape = residual_type, color = residual_type, group = residual_type)) +geom_hline(yintercept =0, linetype ="dashed") +geom_point(size =3, stroke =1.2) +# Increased stroke for visibilityscale_shape_manual(values = shape_map,breaks =names(labels_map),labels =unname(labels_map),name ="Residual Type" ) +scale_color_manual(values = color_map,breaks =names(labels_map),labels =unname(labels_map),name ="Residual Type" ) +labs(title ="Five Residual Variants vs x",x ="x_i",y ="Residual value" ) +theme_bw() +theme(legend.position ="right",legend.title =element_text(face ="bold") )
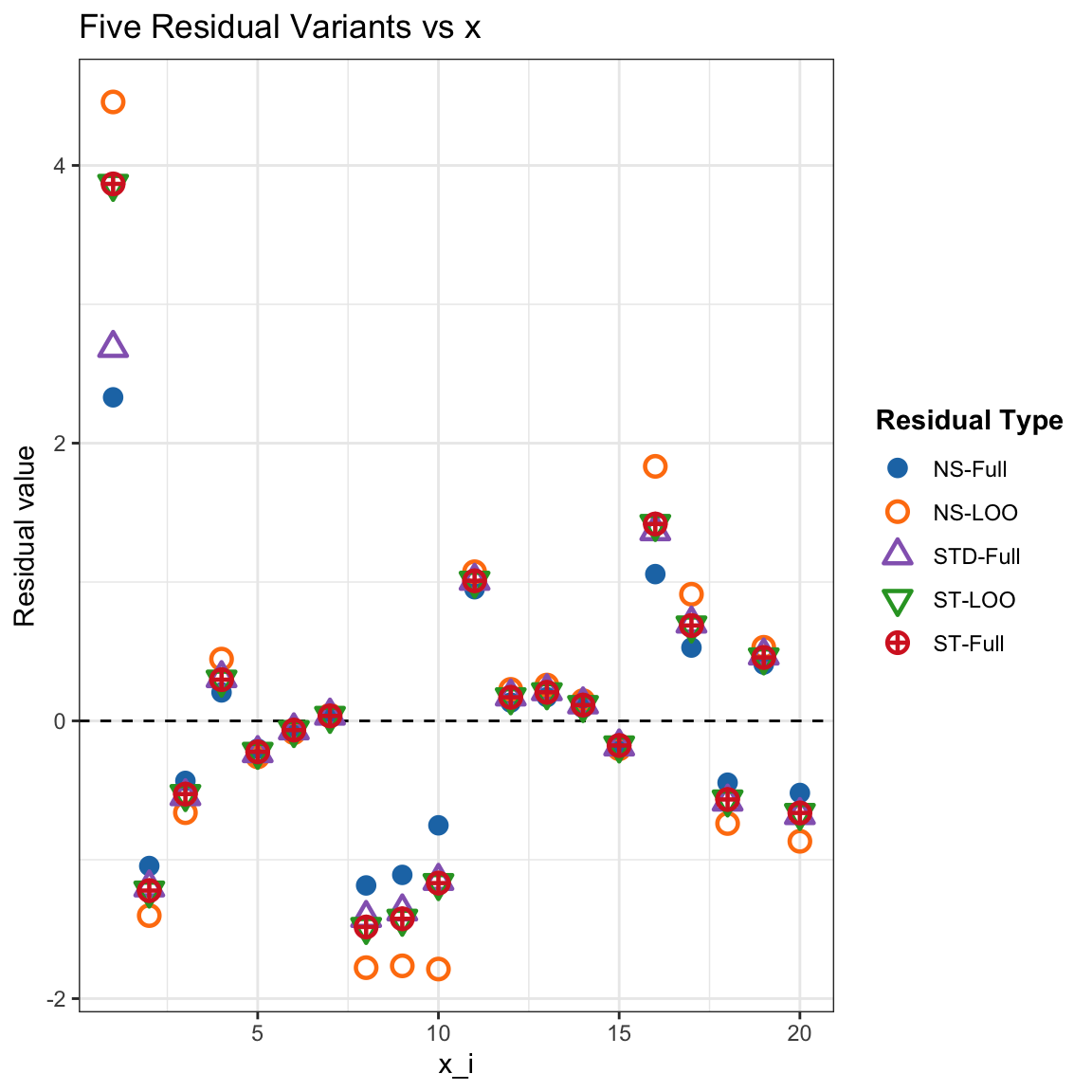
Five residual variants plotted against the predictor variable x.
From the above simulation results, we observe the following important facts:
Leverage and Influence: The simulation confirms that leverage (\(h_{ii}\)) measures an observation’s influence on the model’s coefficients. It shows that points with higher leverage pull the regression line toward them, resulting in smaller, deceptively conservative full-data residuals (\(e_i\)).
Conservative Residuals: The study highlights that the ordinary residual (\(e_i\)) is a “conservative” measure of error because its value for an outlier is systematically reduced by that same outlier’s influence on the model.
Identity Verification: The numerical results validated the key algebraic identity that connects the full-data residual (\(e_i\)) to the leave-one-out (deleted) residual (\(e_{i,-i}\)), as well as the identity for calculating the LOOCV standard error (\(\hat{\sigma}_{-i}\)) from the full model’s statistics. This demonstrates that all key LOOCV errors can be calculated efficiently from a single model fit.
Effective Studentization: The final step of studentization, which uses leverage to properly scale the residuals, is shown to be crucial. It successfully transforms the residuals into a reliable diagnostic tool with a constant variance across all predictor values (\(x_i\)), causing them to behave much more like a standard normal or t-distribution.
5.5 Cook’s Distance
5.5.1 Definition from the change in coefficients
Let \(\hat{\boldsymbol\beta}\) be the OLS estimate on all \(n\) cases and \(\hat{\boldsymbol\beta}_{(-i)}\) the estimate after deleting case \(i\).
With \(p\) parameters (including intercept) and \(\hat\sigma^2=\mathrm{MSE}\),
This measures how far the whole coefficient vector moves (in the \(X^{\!\top}X\) metric) when case \(i\) is removed, scaled per parameter.
5.5.1.1 Express \(D_i\) via the studentized LOOCV residual: \(t_i\)
Let \(h_{ii}\) be the leverage and define the LOOCV quantities \(e_{i,-i}\) and \(\hat\sigma_{-i}\) from the model refit without case \(i\).
The externally studentized residual is
So \(4/n\) is a rule-of-thumb 95% cutoff for an average-leverage point; the exact leverage–aware cutoff is \(d_{i,\alpha}\) above (larger for high \(h_{ii}\), smaller for low \(h_{ii}\)).
5.5.1.4 Comparing \(4/n\) rules with the actual critical values
Code
library(dplyr)library(tidyr)library(gt)## Exact 95% Cook's D cutoff under average leverage h_ii = p/n (so c_i = 1):## d_{i,0.95} = qbeta(0.95; 1/2, (n - p - 1)/2), valid when nu = n - p - 1 > 0cook_crit_avg <-function(n, p, alpha =0.05) { nu <- n - p -1if (nu <=0) return(NA_real_) stats::qbeta(1- alpha, shape1 =0.5, shape2 = nu /2)}## Grids (edit as needed)n_vals <-c(20, 30, 50, 80)p_vals <-c(2, 3, 5, 10)df <- tidyr::crossing(n = n_vals, p = p_vals) %>%mutate(valid = p <= n -2,nu = n - p -1L) %>%rowwise() %>%mutate(cook_crit_95 =if (valid) cook_crit_avg(n, p, 0.05) elseNA_real_,`4/n`=4/ n,ratio = cook_crit_95 /`4/n`,`p/n`= p / n ) %>%ungroup() %>%filter(valid) %>%select(n, p, `p/n`, nu, cook_crit_95, `4/n`, ratio) %>%mutate(`p/n`=round(`p/n`, 3),cook_crit_95 =round(cook_crit_95, 6),`4/n`=round(`4/n`, 6),ratio =round(ratio, 4) )df |>gt() |>cols_label(n =md("$n$"),p =md("$p$"),`p/n`=md("$p/n$"),nu =md("$\\nu = n - p - 1$"),cook_crit_95 =md("$d_{i,0.95}$"),`4/n`=md("$4/n$"),ratio =md("$d_{i,0.95} / (4/n)$") ) |>cols_align(align ="right",columns =everything() )
Exact 95% Cook’s D critical value (average leverage \(h_{ii}=p/n \Rightarrow c_i=1\)) vs heuristic \(4/n\).
\(n\)
\(p\)
\(p/n\)
\(\nu = n - p - 1\)
\(d_{i,0.95}\)
\(4/n\)
\(d_{i,0.95} / (4/n)\)
20
2
0.100
17
0.207508
0.200000
1.0375
20
3
0.150
16
0.219284
0.200000
1.0964
20
5
0.250
14
0.247316
0.200000
1.2366
20
10
0.500
9
0.362487
0.200000
1.8124
30
2
0.067
27
0.134893
0.133333
1.0117
30
3
0.100
26
0.139791
0.133333
1.0484
30
5
0.167
24
0.150733
0.133333
1.1305
30
10
0.333
19
0.187366
0.133333
1.4052
50
2
0.040
47
0.079282
0.080000
0.9910
50
3
0.060
46
0.080951
0.080000
1.0119
50
5
0.100
44
0.084510
0.080000
1.0564
50
10
0.200
39
0.094944
0.080000
1.1868
80
2
0.025
77
0.048973
0.050000
0.9795
80
3
0.038
76
0.049605
0.050000
0.9921
80
5
0.062
74
0.050920
0.050000
1.0184
80
10
0.125
69
0.054533
0.050000
1.0907
5.5.2 Example for Cook’s Distance:
Code
library(dplyr)library(ggplot2)library(knitr)## --- 1) Data and full-model fit (your setup)n <-20x <-1:ny <-2+3* x +rnorm(n, mean =0, sd =5)y[1] <- y[1] +30# add an outlier at i = 1y[11] <- y[11] +30full_data <-data.frame(x = x, replicate(5, rnorm(n)), y = y)fit <-lm(y ~ ., data = full_data)## --- 2) Ingredients for Cook's D and thresholdsp <-length(coef(fit)) # includes intercepth <-hatvalues(fit) # leverage h_iiD <-cooks.distance(fit) # Cook's D_inu <- n - p -1# df for deleted-studentized residualalpha <-0.05## Per-case scaling factor: c_i = ((n-p)/p) * (h_ii/(1-h_ii))c_i <- ((n - p) / p) * (h / (1- h))## Exact per-case Beta 95% critical values:## D_i / c_i ~ Beta(1/2, (n-p-1)/2) => D_crit_i = c_i * qbeta(0.95, 1/2, (n-p-1)/2)crit_beta_i <- c_i *qbeta(1- alpha, shape1 =0.5, shape2 = nu /2)## Average-leverage Beta 95% critical value:## If h_ii = p/n (average leverage), then c_i = 1 exactlycrit_beta_avg <-qbeta(1- alpha, shape1 =0.5, shape2 = nu /2)## Heuristic 4/n linecrit_heur <-4/ n## --- 3) Assemble results tabledf_cook <-tibble(i =seq_len(n),h_ii =as.numeric(h),D_i =as.numeric(D),c_i =as.numeric(c_i),crit_beta_i =as.numeric(crit_beta_i),crit_beta_avg = crit_beta_avg,crit_heur = crit_heur)## Print a compact tableknitr::kable( df_cook %>%mutate(across(where(is.numeric), ~round(.x, 5))),caption ="Cook's D, leverage, and thresholds: per-case Beta 95%, average-leverage Beta 95%, and 4/n.")
Cook’s D, leverage, and thresholds: per-case Beta 95%, average-leverage Beta 95%, and 4/n.
i
h_ii
D_i
c_i
crit_beta_i
crit_beta_avg
crit_heur
1
0.54404
1.03571
2.21590
0.62813
0.28346
0.2
2
0.42228
0.20010
1.35749
0.38480
0.28346
0.2
3
0.21470
0.00018
0.50773
0.14392
0.28346
0.2
4
0.47853
0.00077
1.70425
0.48309
0.28346
0.2
5
0.40799
0.03221
1.27988
0.36280
0.28346
0.2
6
0.15620
0.03515
0.34377
0.09745
0.28346
0.2
7
0.42643
0.01204
1.38073
0.39139
0.28346
0.2
8
0.16456
0.02982
0.36582
0.10370
0.28346
0.2
9
0.24595
0.02222
0.60575
0.17171
0.28346
0.2
10
0.25873
0.00978
0.64821
0.18374
0.28346
0.2
11
0.44169
0.52592
1.46921
0.41647
0.28346
0.2
12
0.39893
0.01004
1.23260
0.34940
0.28346
0.2
13
0.35963
0.00202
1.04297
0.29564
0.28346
0.2
14
0.31597
0.02317
0.85786
0.24317
0.28346
0.2
15
0.24452
0.00672
0.60109
0.17039
0.28346
0.2
16
0.49796
0.27524
1.84205
0.52215
0.28346
0.2
17
0.29447
0.18950
0.77512
0.21972
0.28346
0.2
18
0.32086
0.00109
0.87742
0.24872
0.28346
0.2
19
0.41145
0.00851
1.29829
0.36802
0.28346
0.2
20
0.39510
0.00595
1.21300
0.34384
0.28346
0.2
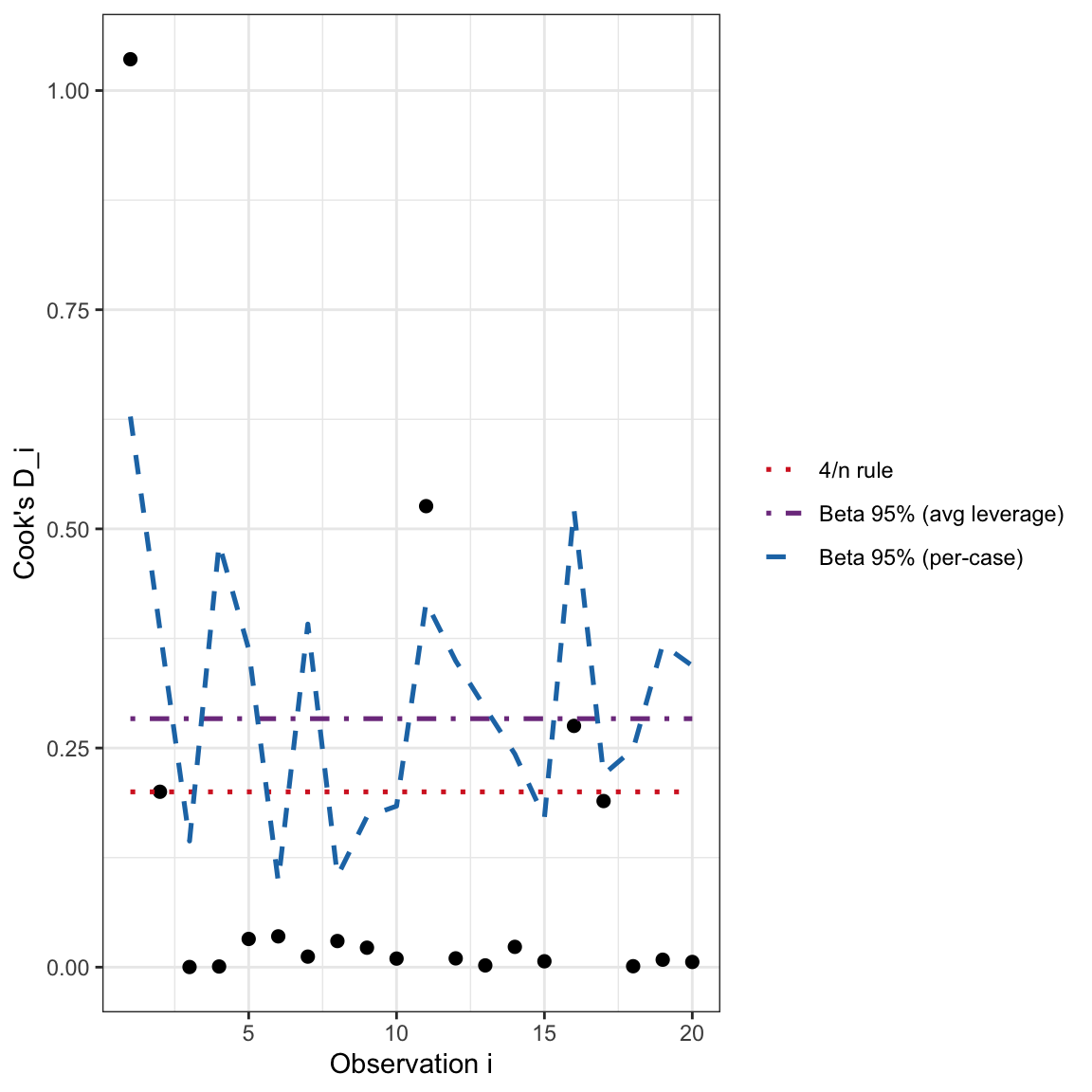
Cook’s D by case with heuristic 4/n (red dotted), per-case Beta 95% critical values (blue dashed), and average-leverage Beta 95% line (purple dot-dash).
Code
## --- 4) Plot D_i with thresholdsthresh_df <-bind_rows( df_cook %>%transmute(i, value = crit_beta_i, Type ="Beta 95% (per-case)"),tibble(i =seq_len(n), value = crit_beta_avg, Type ="Beta 95% (avg leverage)"),tibble(i =seq_len(n), value = crit_heur, Type ="4/n rule"))ggplot(df_cook, aes(x = i, y = D_i)) +geom_point(size =2) +geom_line(data = thresh_df,aes(y = value, color = Type, linetype = Type),linewidth =0.9) +scale_color_manual(values =c("Beta 95% (per-case)"="#1f77b4","Beta 95% (avg leverage)"="#7f3c8d","4/n rule"="#d62728" )) +scale_linetype_manual(values =c("Beta 95% (per-case)"="dashed","Beta 95% (avg leverage)"="dotdash","4/n rule"="dotted" )) +labs(x ="Observation i", y ="Cook's D_i") +theme_bw() +theme(legend.title =element_blank())
Cook’s D by case with heuristic 4/n (red dotted), per-case Beta 95% critical values (blue dashed), and average-leverage Beta 95% line (purple dot-dash).
Appendix: Key Identities
The power of modern regression diagnostics comes from algebraic shortcuts that allow us to find the results of a leave-one-out process without the computational cost of refitting the model n times. The following two identities are fundamental to this efficiency.
Finding the LOOCV Residual (\(e_{i,-i}\)) from the Ordinary Residual (\(e_i\))
This identity shows that we can find the “pure” leave-one-out residual using only the results from the single model fit on all data.
\[e_{i,-i} = \frac{e_i}{1 - h_{ii}} \tag{5.3}\]
Finding the LOOCV Standard Error from the Full-Model Standard Error
Similarly, this formula provides an efficient shortcut to see how the model’s overall error changes when a single point is removed.
The derivation of this formula relies on first proving the relationship between the full model’s Residual Sum of Squares (\(RSS\)) and the leave-one-out version (\(RSS_{-i}\)).
Start with the definition of the leave-one-out residual sum of squares: \[
RSS_{-i} = \sum_{k \neq i} (y_k - \mathbf{x}_k^T\hat{\beta}_{-i})^2
\]
Introduce the key identity that relates the leave-one-out coefficient vector (\(\hat{\beta}_{-i}\)) to the full model’s coefficient vector (\(\hat{\beta}\)): \[
\hat{\beta}_{-i} = \hat{\beta} - (X^TX)^{-1}\mathbf{x}_i \frac{e_i}{1 - h_{ii}}
\]
Substitute this identity into the expression for a generic leave-one-out residual, \(e_{k,-i} = y_k - \mathbf{x}_k^T\hat{\beta}_{-i}\). After simplification, this yields: \[
e_{k,-i} = e_k + h_{ki} \frac{e_i}{1 - h_{ii}}
\] where \(e_k\) is the ordinary residual and \(h_{ki}\) is the \((k,i)\)-th element of the hat matrix.
Substitute this back into the definition of\(RSS_{-i}\). After expanding the squared term and performing the summation (which involves considerable but standard matrix algebra), the expression simplifies to the elegant result: \[
RSS_{-i} = RSS - \frac{e_i^2}{1 - h_{ii}}
\]
Finally, derive the formula for\(\hat{\sigma}_{-i}\). We know that \(\hat{\sigma}^2_{-i} = \frac{RSS_{-i}}{n-p-1}\) and that \(RSS = (n-p)\hat{\sigma}^2\). By substituting the result from Step 4, we arrive at the formula for the variance, and taking the square root gives us the standard error.