This section analyzes data from a Completely Randomized Design (CRD). In a CRD, experimental units (in this case, the silicon wafers being etched) are assigned to treatments (the RF Power levels) completely at random. The primary goal is to determine if changing the RF Power level has a statistically significant effect on the mean etch rate.
7.1.2.1 Data and Visualization
We begin by loading the data into a single, tidy data.frame. The response variable, rate, contains all the etch rate observations. The predictor variable, power, is a factor, which is R’s way of representing a categorical variable. This tells R to treat the different power levels as distinct groups.
Code
## Define the data vectorsrate <-c(575, 542, 530, 539, 570, 565, 593, 590, 579, 610,600, 651, 610, 637, 629, 725, 700, 715, 685, 710)power_levels <-c(160, 180, 200, 220)## Create the data frameetching_df <-data.frame(rate = rate,power =factor(rep(power_levels, each =5)))## Display the first few rowsetching_df
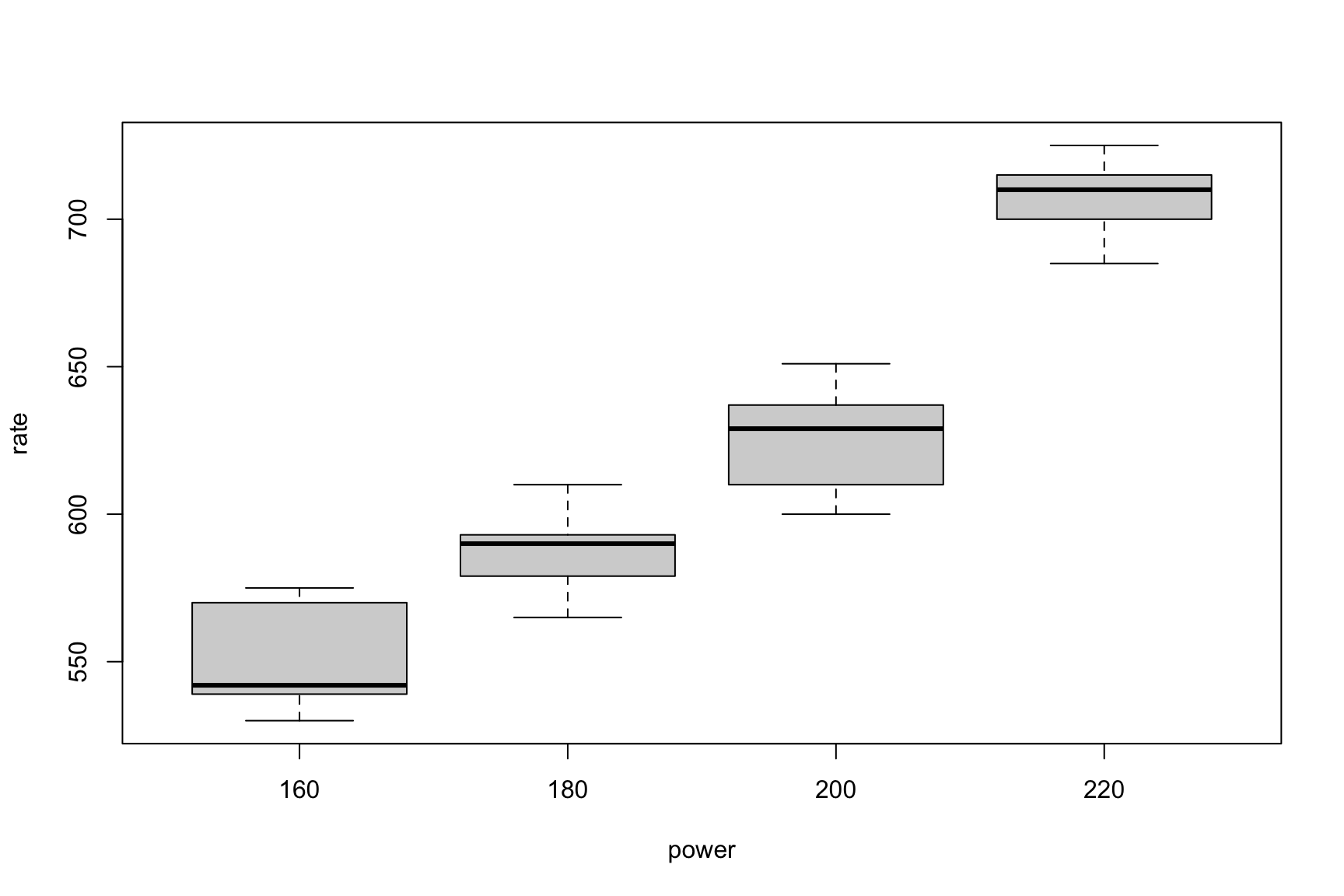
Grouped Boxplots
Code
boxplot(rate~power, data=etching_df)
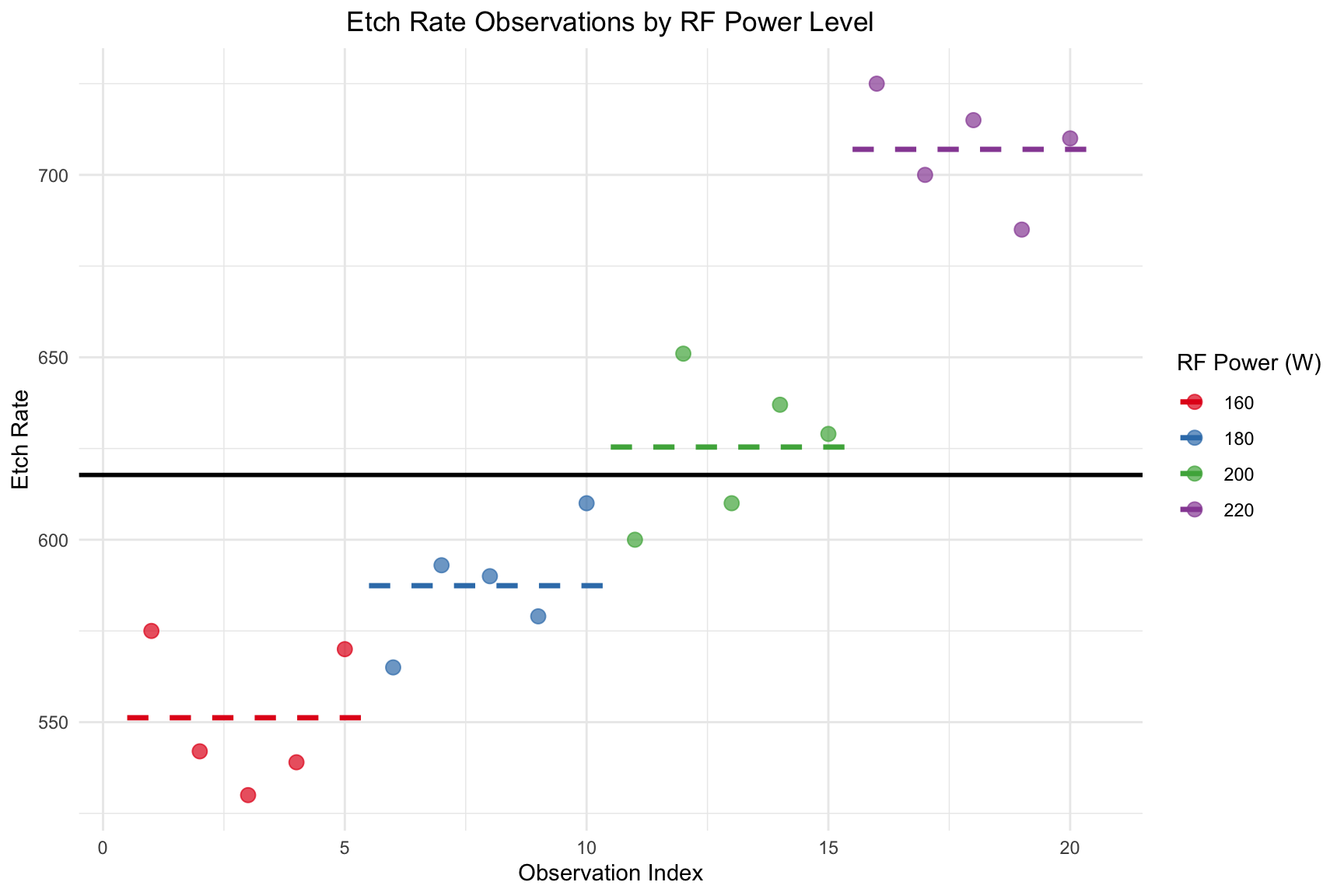
Using ggplot to visualize grouped data
Code
library(ggplot2)library(dplyr) # Using dplyr for easier data manipulation## Calculate group means and their start/end indicesmean_rates <- etching_df %>%mutate(obs_index =row_number()) %>%group_by(power) %>%summarise(mean_rate =mean(rate),x_start =min(obs_index) -0.5,x_end =max(obs_index) +0.5 )ggplot(etching_df, aes(x =1:nrow(etching_df), y = rate, color = power)) +geom_hline(yintercept =mean(etching_df$rate), linetype ="solid", color ="black", size =1 ) +# ----------------------------------------geom_point(size =3, alpha =0.7) +# Plot individual data pointsgeom_segment(data = mean_rates, aes(x = x_start, xend = x_end, y = mean_rate, yend = mean_rate),linetype ="dashed", size =1.2 ) +# Add line segments for group meanslabs(title ="Etch Rate Observations by RF Power Level",x ="Observation Index",y ="Etch Rate",color ="RF Power (W)" ) +scale_color_brewer(palette ="Set1") +theme_minimal() +theme(plot.title =element_text(hjust =0.5))
Index Plot of Etch Rate with Group-Specific Mean Lines
7.1.2.2 Cell Mean Models (zero-intercept)
Code
fit_nointercpt <-lm(rate ~0+power, data = etching_df)model.matrix(fit_nointercpt)
This ANOVA result is typically unwanted. If we want to see the causal effect of power, we need to compare to intercept-only model:
Code
fit_intercept <-lm(rate ~1, data = etching_df)anova(fit_intercept, fit_nointercpt)
7.1.2.3 Centralized Effect Model (Sum-to-Zero Constraint)
We fit a linear model using the lm() function to perform an Analysis of Variance (ANOVA). The model is specified as rate ~ power, and we now include the data = etching_df argument.
To get interpretable estimates for the treatment effects (\(\tau_i\)), we use a sum-to-zero constraint (contr.sum), which forces the sum of the treatment effects to be zero (\(\sum \tau_i = 0\)).
Code
fit <-lm(rate ~ power, data = etching_df, contrasts =list(power = contr.sum))
Call:
lm(formula = rate ~ power, data = etching_df, contrasts = list(power = contr.sum))
Residuals:
Min 1Q Median 3Q Max
-25.4 -13.0 2.8 13.2 25.6
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 617.750 4.085 151.234 < 2e-16 ***
power1 -66.550 7.075 -9.406 6.39e-08 ***
power2 -30.350 7.075 -4.290 0.000563 ***
power3 7.650 7.075 1.081 0.295602
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 18.27 on 16 degrees of freedom
Multiple R-squared: 0.9261, Adjusted R-squared: 0.9122
F-statistic: 66.8 on 3 and 16 DF, p-value: 2.883e-09
Confidence Interval for Centralized Effects:
The output of the model provides estimates for the overall mean (\(\hat{\mu}\)) and the treatment effects for the first k-1 levels (\(\hat{\tau}_1, \hat{\tau}_2, \hat{\tau}_3\)).
\(\hat{\mu}\) (the Intercept) is the estimate of the grand mean etch rate across all power levels.
\(\hat{\tau}_i\) is the estimated effect of the i-th power level, representing how much that level’s mean deviates from the grand mean.
Using the sum-to-zero constraint, we can manually calculate the effect for the final level, \(\hat{\tau}_4\).
Code
# Define a named vector of all linear combinations## NOTE: Replace 'power1', 'power2', 'power3' with the# actual names from your coef(fit) output.## The names on the left (e.g., "Level_1_Effect") are# for you; they will label the output rows.library(biostat3)k_all_levels <-c("Effect for Level 1"="power1","Effect for Level 2"="power2","Effect for Level 3"="power3","Effect for Level 4"="-power1 - power2 - power3")# Run lincom on the whole vectorlincom(fit, k_all_levels)
Estimate 2.5 % 97.5 % Df Sum of Sq
Effect for Level 1 -66.55 -80.41666 -52.68334 1 29526.02
Effect for Level 2 -30.35 -44.21666 -16.48334 1 6140.817
Effect for Level 3 7.65 -6.216659 21.51666 1 390.15
Effect for Level 4 89.25 75.38334 103.1167 1 53103.75
Code
##### Estimate of Treatment Means
We can verify the above results by looking at the point estimate of centralized effect by direct calculation. The construction of CI is more complicated, hence, omitted.
The ANOVA table partitions the total variation into variation between treatment groups (power) and variation within treatment groups (random error). The p-value (Pr(>F)) indicates if the treatment has a significant effect.
Code
anova(fit)
7.1.2.4 Baseline Model (Default for R)
Fitting the model without specifying contrasts uses R’s default (“treatment” contrast), which sets \(\tau_1 = 0\). The fundamental results (ANOVA, treatment means) remain unchanged.
Code
fit1 <-lm(rate ~ power, data = etching_df)model.matrix(fit1)
Pairwise comparisons using t tests with pooled SD
data: rate and power
220 160 180
160 3.7e-10 - -
180 1.7e-08 0.0064 -
200 2.7e-06 8.4e-06 0.0046
P value adjustment method: none
7.1.2.5.2 Tukey’s HSD Test
Tukey’s Honest Significant Difference (HSD) controls the family-wise error rate, adjusting p-values to account for multiple comparisons.
Code
fit.aov <-aov(rate ~ power, data = etching_df)TukeyHSD(fit.aov)
The validity of our ANOVA results depends on three key assumptions about the model’s residuals. We use diagnostic plots to check them.
Code
r <-rstudent(fit)fitted <-fitted.values(fit)
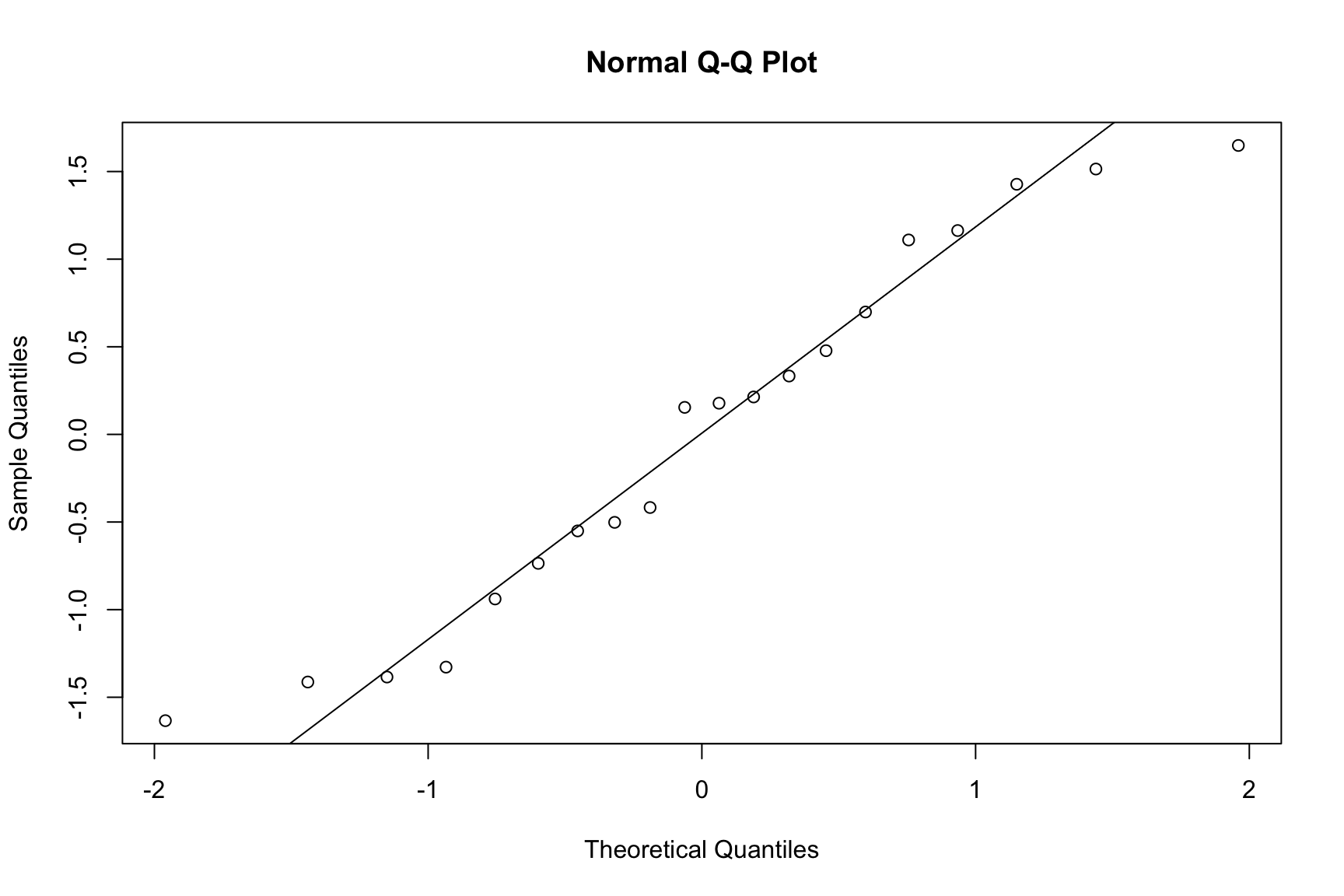
7.1.2.6.1 Normality of Residuals
A Normal Q-Q plot is used to check if the residuals are normally distributed. The points should fall closely along the straight diagonal line.
Code
qqnorm(r)qqline(r)
Normal Q-Q plot of standardized residuals.
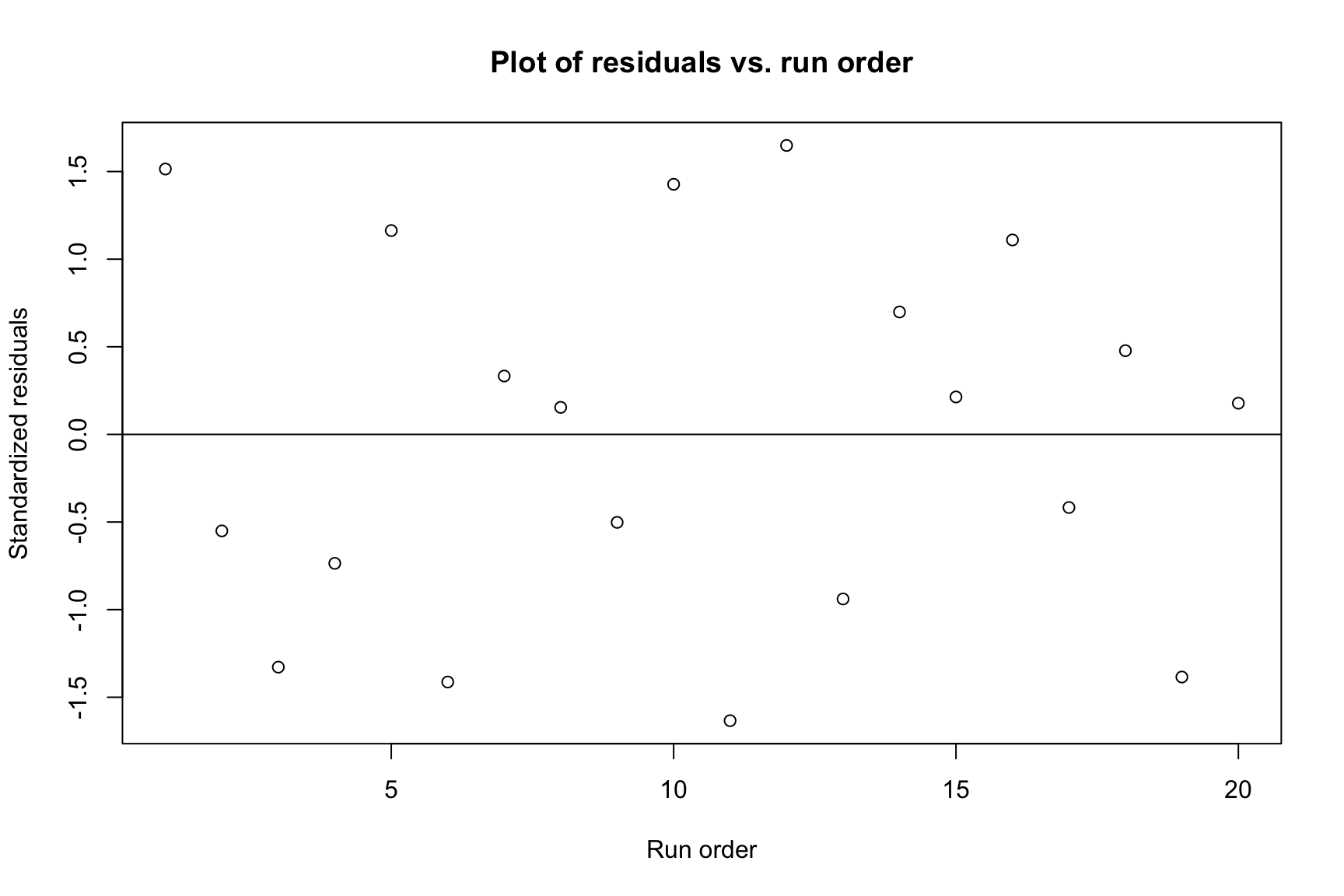
7.1.2.6.2 Independence of Residuals
A plot of residuals versus run order helps check for independence. We look for random scatter around the zero line.
Code
plot(r, ylab ="Standardized residuals", xlab ="Run order",main ="Plot of residuals vs. run order")abline(h =0)
Standardized residuals vs. run order.
7.1.2.6.3 Constant Variance (Homoscedasticity)
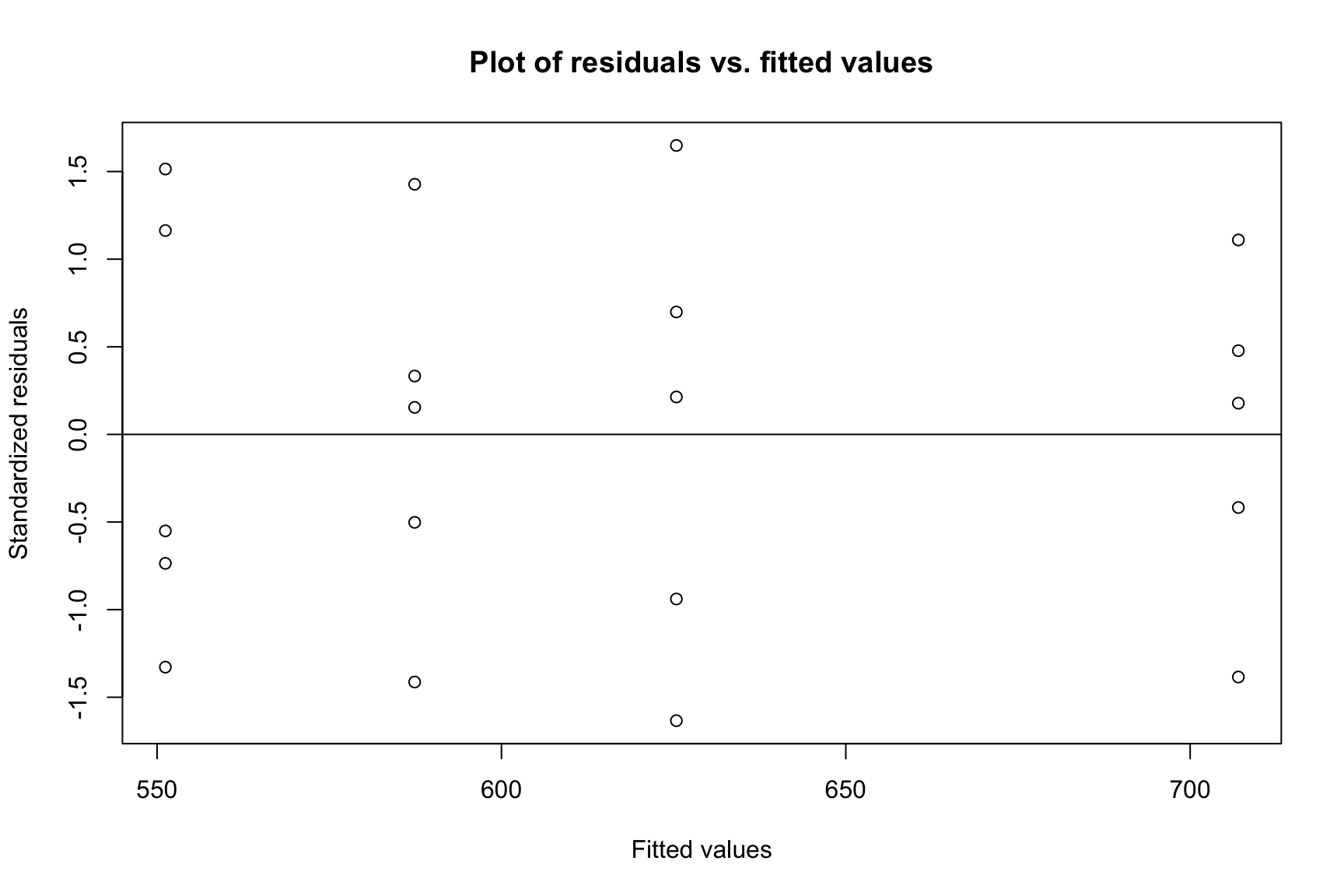
A plot of residuals versus fitted values helps check for constant variance. The spread of residuals should be roughly constant across all fitted values.
Code
plot(fitted, r, ylab ="Standardized residuals", xlab ="Fitted values", main ="Plot of residuals vs. fitted values")abline(h =0)
Standardized residuals vs. fitted values.
7.2 Unbalanced Designs with Unequal Sample Sizes
The ANOVA framework also handles unbalanced designs. We again start by creating a data frame.
## Fit the model and get the ANOVA tablefit2 <-lm(density ~ temperature, data = bricks_df)summary(fit2)
Call:
lm(formula = density ~ temperature, data = bricks_df)
Residuals:
Min 1Q Median 3Q Max
-0.300 -0.100 0.000 0.095 0.200
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 21.74000 0.07171 303.150 <2e-16 ***
temperature125 -0.24000 0.10757 -2.231 0.0425 *
temperature150 -0.02000 0.10142 -0.197 0.8465
temperature175 -0.04000 0.10757 -0.372 0.7156
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.1604 on 14 degrees of freedom
Multiple R-squared: 0.3025, Adjusted R-squared: 0.153
F-statistic: 2.024 on 3 and 14 DF, p-value: 0.1569
Code
anova(fit2)
In this case, the large p-value (0.133) indicates that there is no statistically significant evidence that firing temperature affects brick density.
7.3 Randomized Complete Block Design
7.3.1 Vascular Graft Experiment
This section analyzes a Randomized Complete Block Design (RCBD), used to control for a known source of variability (here, “batches of resin,” treated as blocks).
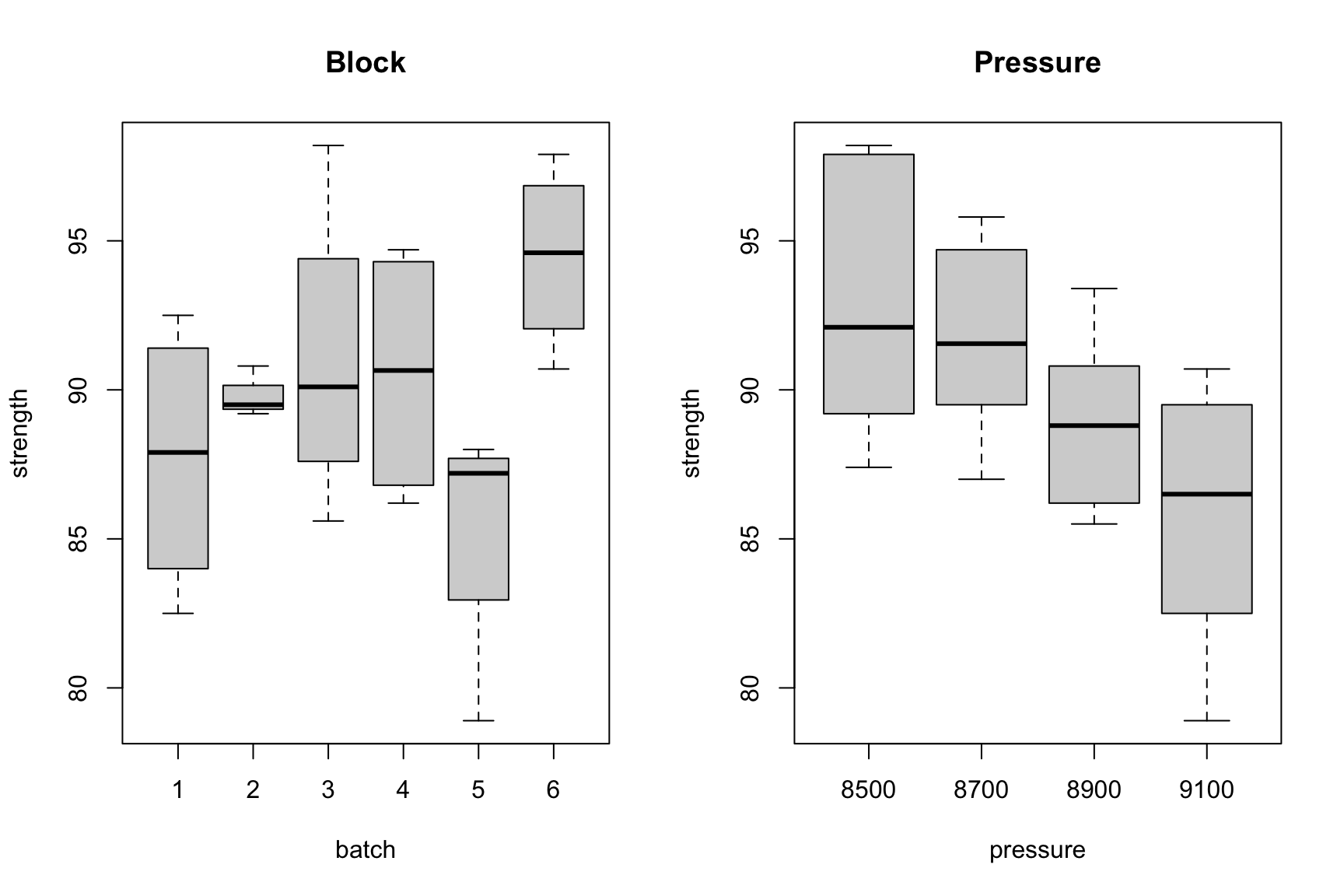
7.3.1.1 Data and Visulization
We structure the data in a data.frame to identify the response, treatment (pressure), and block (batch) for each observation.
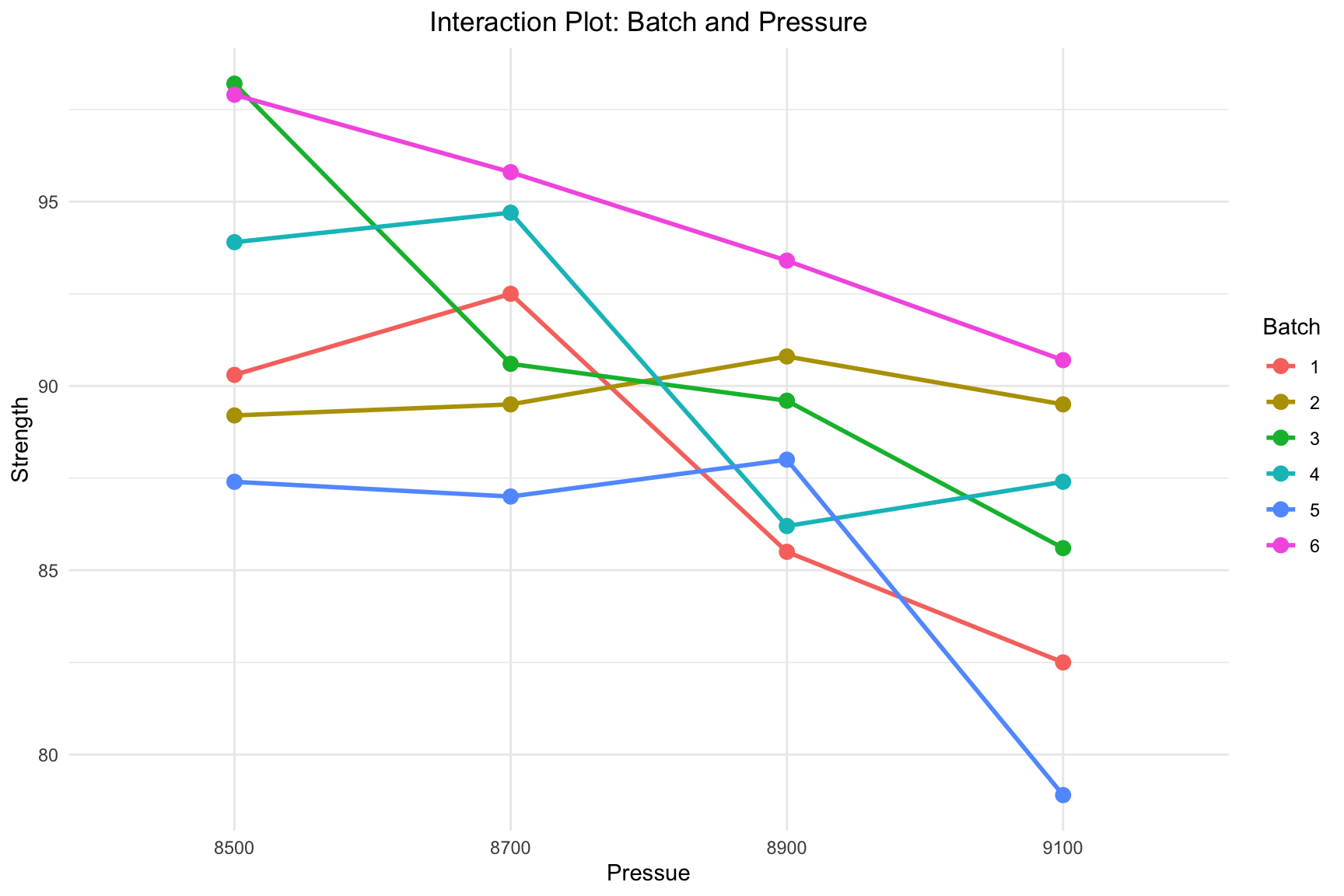
Interaction between Material Type and Temperature.
7.3.1.2 Model Fitting and ANOVA
The model strength ~ pressure + batch partitions the total variance into treatment, block, and error components. Our primary interest is in the significance of the pressure factor.
Code
rcbd.fit1 <-lm(strength ~ pressure + batch, data = graft_df)summary(rcbd.fit1)
The small p-value for pressure (0.0019) provides strong evidence that extrusion pressure significantly affects graft strength after accounting for batch differences.
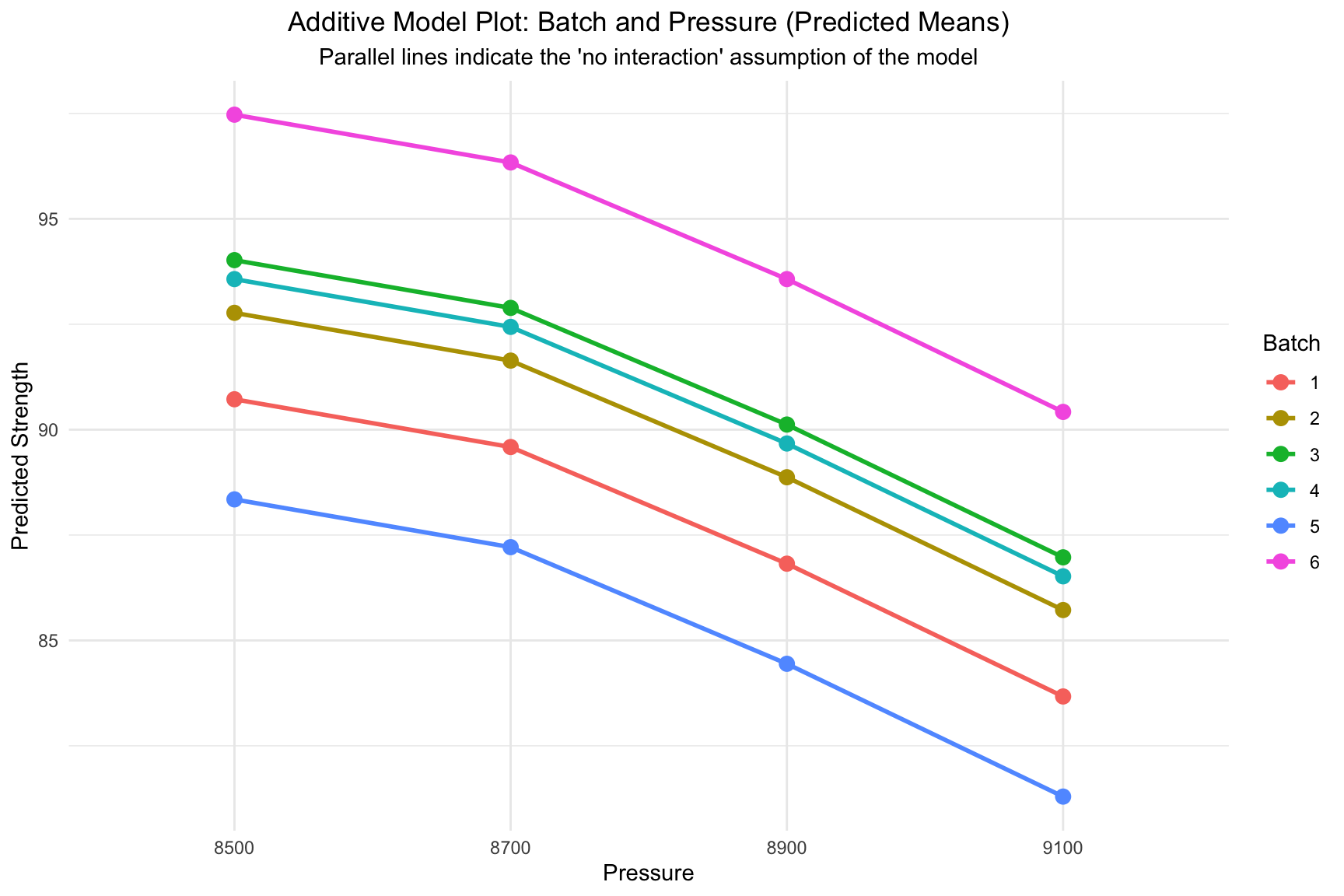
7.3.1.3 Visualizing the Additive Assumption
The plot below visualizes the predictions generated by the fitted additive model (strength ~ pressure + batch). Notice that the lines are perfectly parallel, which is the graphical representation of the model’s assumption that there is no interaction between the two factors.
Code
# 1. Create a data frame for plotting predictionspred_df <- graft_df# 2. Make predictions using the fitted additive modelpred_df$predicted_strength <-predict(rcbd.fit1, newdata = pred_df)# 3. Plot the predicted values# Plotting the predicted means will show the parallel lines.ggplot(pred_df, aes(x = pressure, y = predicted_strength, group = batch, color = batch)) +# Use stat_summary to plot the predicted means for each pressure/batch combinationstat_summary(fun = mean, geom ="line", size =1) +stat_summary(fun = mean, geom ="point", size =3) +labs(title ="Additive Model Plot: Batch and Pressure (Predicted Means)",subtitle ="Parallel lines indicate the 'no interaction' assumption of the model",x ="Pressure",y ="Predicted Strength",color ="Batch" ) +theme_minimal() +theme(plot.title =element_text(hjust =0.5),plot.subtitle =element_text(hjust =0.5))
Interaction plot showing the predictions from the additive model (parallel lines).
7.3.1.4 Model Adequacy Checks
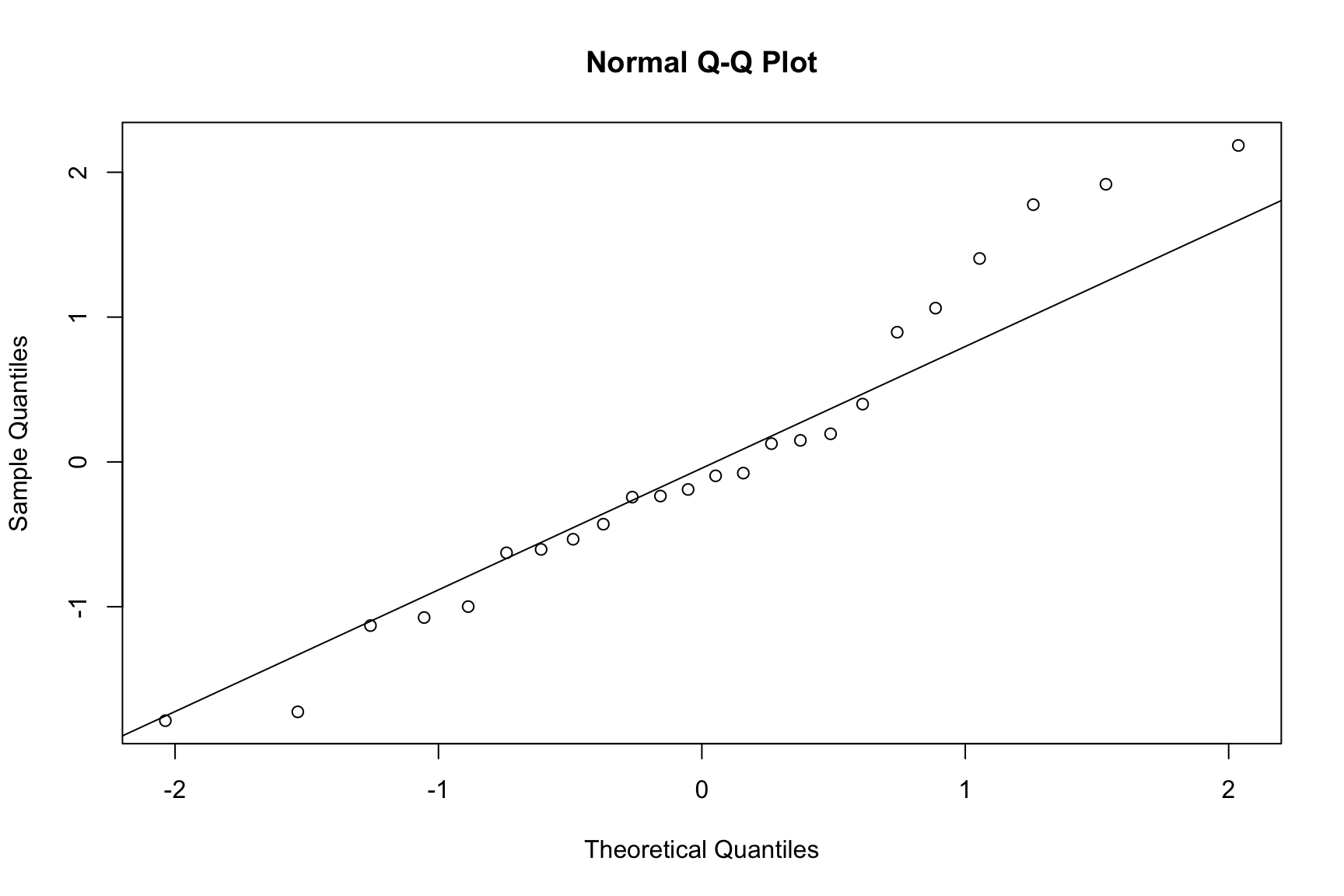
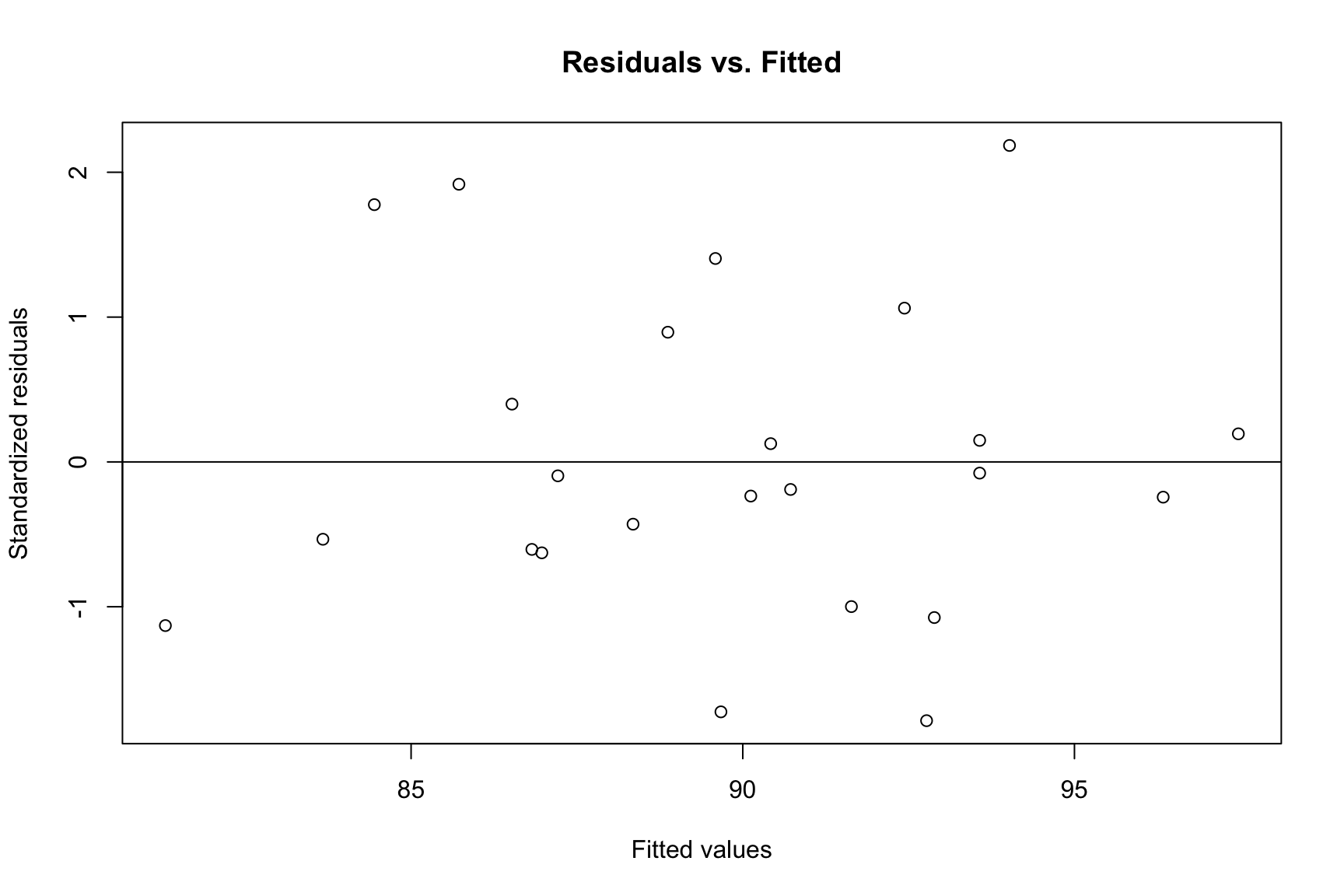
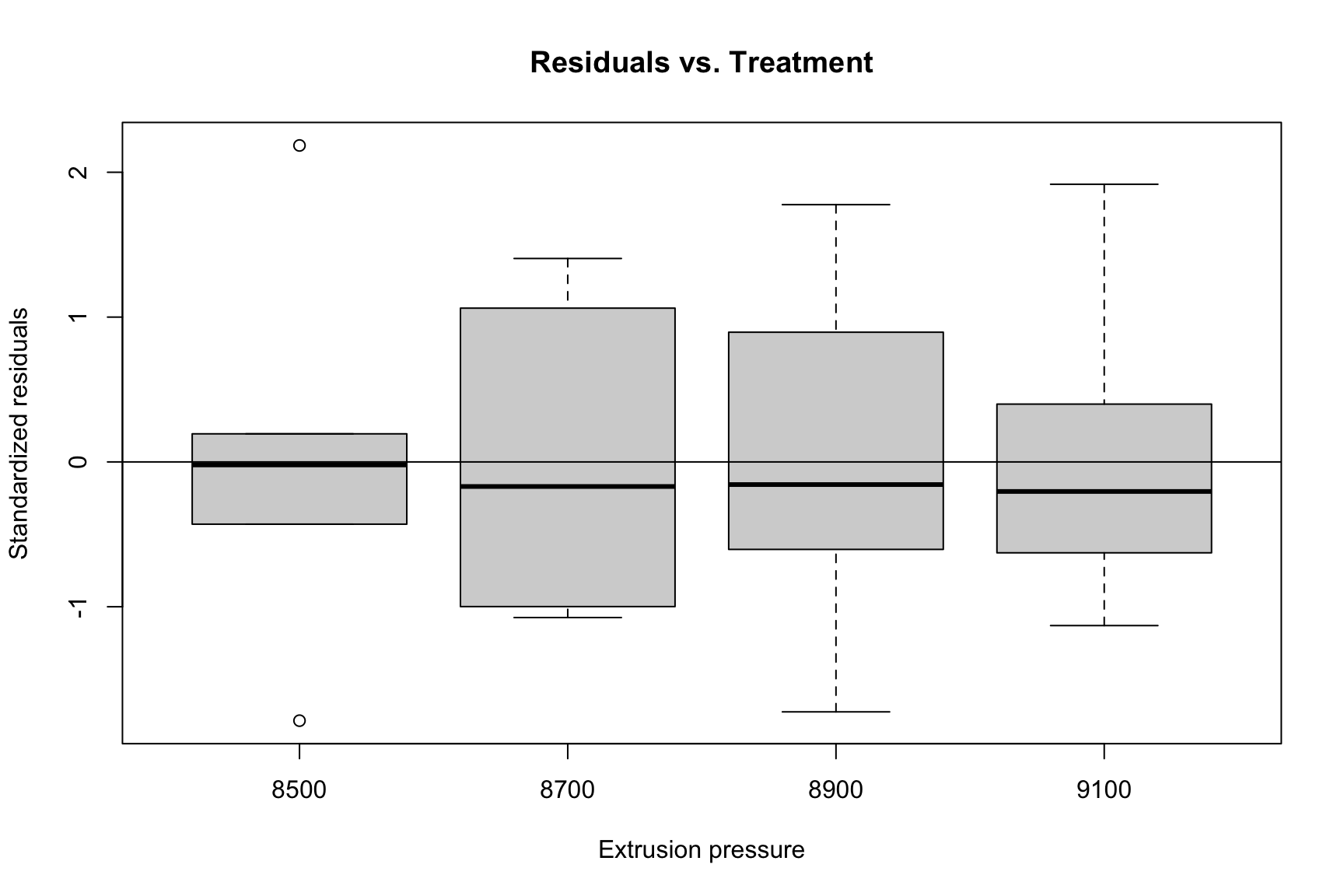
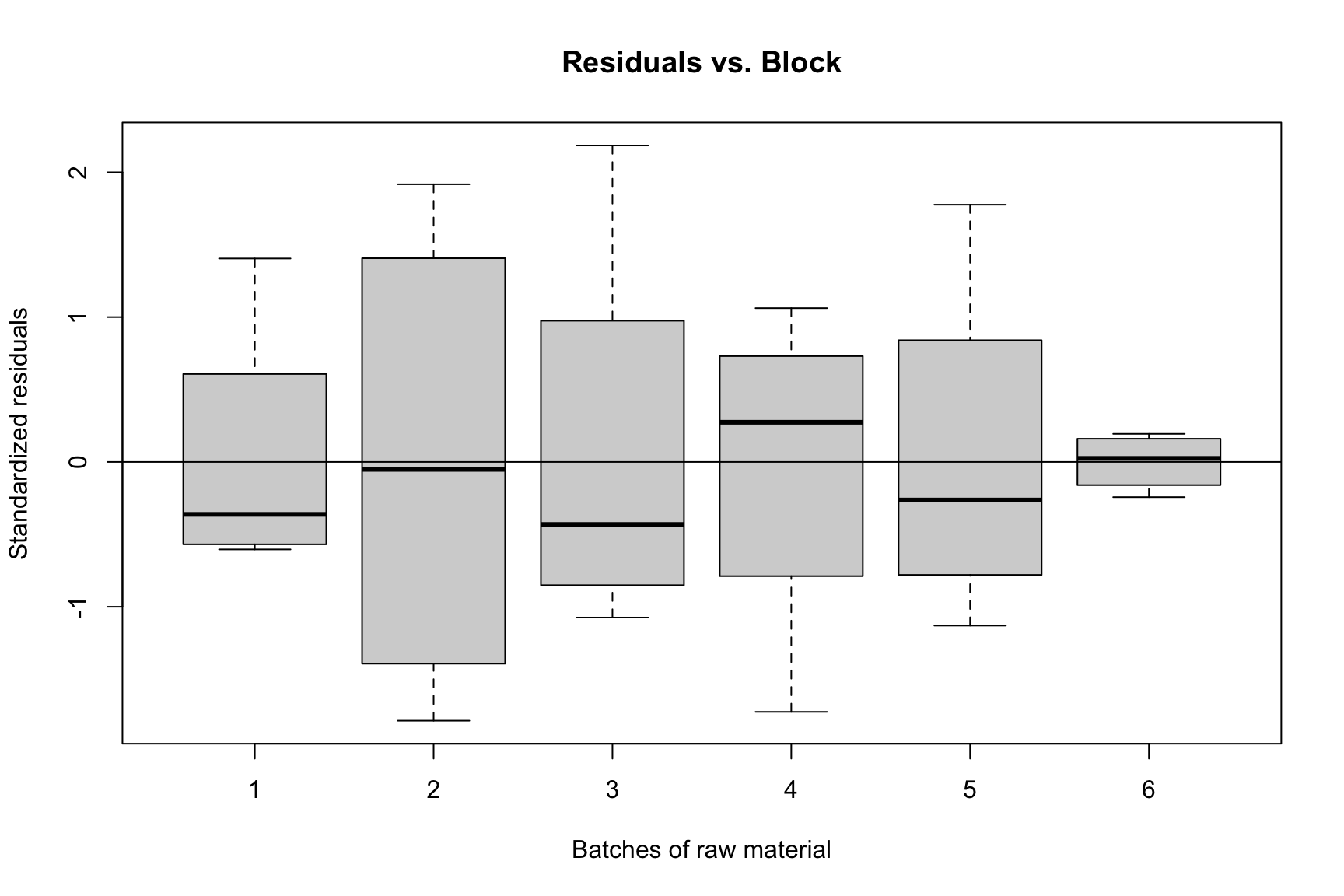
The assumptions for an RCBD are the same as for a CRD. We perform the same diagnostic checks.
Code
rcbd.r1 <-rstudent(rcbd.fit1)rcbd.fitted1 <-fitted.values(rcbd.fit1)qqnorm(rcbd.r1, main ="Normal Q-Q Plot")qqline(rcbd.r1)plot(rcbd.fitted1, rcbd.r1, ylab ="Standardized residuals", xlab ="Fitted values", main ="Residuals vs. Fitted")abline(h =0)plot(graft_df$pressure, rcbd.r1, ylab ="Standardized residuals", xlab ="Extrusion pressure", main ="Residuals vs. Treatment")abline(h =0)plot(graft_df$batch, rcbd.r1, ylab ="Standardized residuals", xlab ="Batches of raw material", main ="Residuals vs. Block")abline(h =0)
Normal Q-Q Plot
Residuals vs. Fitted Values
Residuals vs. Treatment (Pressure)
Residuals vs. Block (Batch)
7.3.1.5 Pairwise Comparisons
Again, since the treatment factor (pressure) is significant, we perform post-hoc tests.
7.3.1.5.1 Tukey’s HSD Test
Tukey’s HSD compares all pairs of treatment levels while controlling the family-wise error rate.
Code
rcbd.aov <-aov(strength ~ pressure + batch, data = graft_df)TukeyHSD(rcbd.aov, which ="pressure")